CDN边缘节点容器调度实践(下)
5月27日,OSC 源创会在上海成功举办。又拍云系统开发高级工程师黄励博在大会分享了《CDN 边缘节点容器调度的实践》。主要介绍又拍云自主开发的边缘节点容器调度方案,从 0 到 1 ,实现零停机、负载均衡,以及基于容器的子网组建、管理等底层功能。
因为分享内容较多,所以将分享整理为两篇文章:
第一篇文章,CDN边缘节点容器调度实践(上)介绍又拍云边缘节点容器调度平台版本1到版本2的发展过程,以及搭建平台时的基本思路;
第二篇文章着重介绍又拍云边缘节点容器调度平台版本3到版本4的发展过程,对平台后续功能的完善做了详细的讲解。本文是第二篇,以下为讲师分享内容:
版本 3 支持动态负载均衡
版本 2 完成了对 App 所有者的隔离和限制,我们来看下服务的访问者,现在他们都是直接访问节点的机器,这样并不适合完成一些服务的调度, 比如负载均衡和服务更新等。
由于之前提供端口映射方案可以是随机的,在这种情况下,App 的访问者甚至不知道服务具体跑在哪些机器, 监听在哪些端口上,因此需要有一个统一的入口。
 △ Slardar
△ Slardar
上图是又拍云开源的基于 ngx_lua 的动态负载均衡方案——Slardar。它可以做到在不 load Nginx 的情况下,动态更新 upstream 列表和动态更新 lua 代码。方便动态的维护容器服务的地址。
那么 Slardar 是如何完成服务动态选择的?

如图所示, 首先对于 http 服务我们可以通过 host 来区分不同服务,动态地找到指定的服务,类似的, 对于 tcp 服务,我们通过接入的端口来区分不同的服务
其中, checkups 是一个动态选择上游的组件,他提供了一个注册机制,我们可以注册用户自定义的负载均衡策略, 默认支持轮询和 hash 算法,同时也支持注册主动的健康检查策略, 默认支持 tcp http mysql等协议,这样为每个服务选择一个正常工作的地址。
 △ 健康检查功能
△ 健康检查功能
上图是健康检查页面,在 slardar 中我们会启用一个定时器来定时检查所有上游的状态。其中 checkup_timer_alive 字段代表这个定时器是否还存活着,last_check_time 字段代表上一次定时器的检查时间。后面是上游的健康状态, 包括 IP、端口号、服务名称, status 状态等。
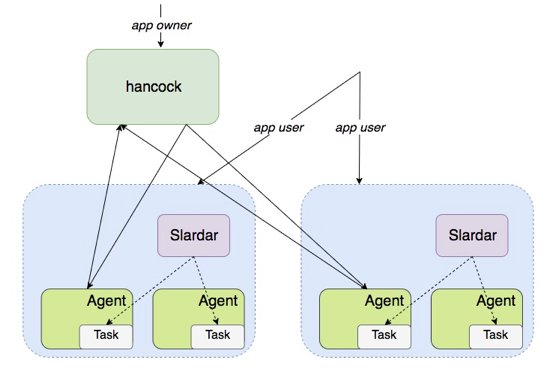 △ 版本3
△ 版本3
我们可以在节点上部署 slardar 作为容器服务的统一入口完成服务的负载均衡和健康检查。服务的用户访问时,都会接入到 Slardar 这个统一入口。由 Slardar 代理到具体的 Task。版本3 的架构如上图所示。
版本 4 支持零停机更新
有了统一的入口,我们可以保证在任务更新时,服务不会出现不可用的状态。可以通过运行两个不同版本的服务同时运行来实现蓝绿更新。
当 Master 收到服务更新请求的时候,Master 会让 Agent 负责启动服务新版本的容器 Tasks,同时把新版本容器地址写入 etcd 把旧版本的地址删除, 之前我们介绍过 calico 会用到这个分布式的 key value 服务器,这边管理 upstream 列表, 我们也同样使用了 etcd 这个 kv 数据库。
旧版本是图中三个蓝色的 Tasks,更新任务开始,会部署三个绿色的新版本 Tasks。当三个新版本任务起来后,Agent 会把 Tasks 中的地址更新到 etcd 中。图中看到有个 confd 的服务会监听 etcd 中 upstream 列表的变更, 把 upstream 列表主动同步给 slardar 完成 upstream 的切换, 而 slardar 启动的时候也支持从 etcd 加载 upstream 列表, 这样就完成了服务的更新, 等旧版本的服务流量没有的时候 Agent 会主动删除旧版本完成更新操作。
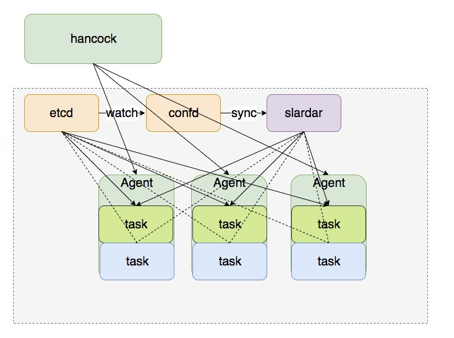 △ 零停机更新
△ 零停机更新
结合上文讲的访问控制、统一入口以及动态更新,我们就拥有了这样一个架构。
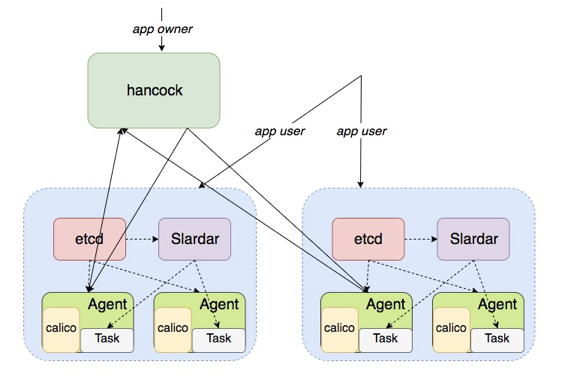 △ 版本4
△ 版本4
版本 4 架构中,Slardar 是 HTTP/TCP 代理,它是一个无状态的代理服务,所以可以任意部署,不存在单点问题,直接部署多台就可以保障可用性。而 Hancock Master 作为服务拥有者的入口,拥有着所有服务的状态,可以看到到现在为止,还是单点的,不是一个高可用的服务。为了解决这个问题,我们需要有一个高可用的方案。
版本 5 实现高可用
与版本 4 项目,版本 5 中使用 Raft 分布式一致性协议实现高可用。
Raft 主要特点有三个:
- 领导选举: 心跳机制来触发选举, term 充当逻辑时钟的作用;
- 日志复制: 领导者把一条指令(能被复制状态机执行)附加到日志中,发起附加条目 RPC 请求给其他角色;
- 强领导者:日志条目只从 leader 发送给其他的服务器。
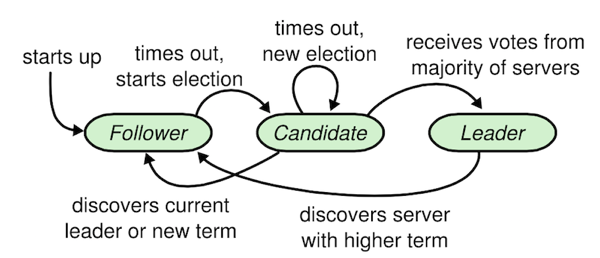
如图所示, 服务起来时默认为跟随者, 如果发现当前集群中有一个领导者, 那就接受它。如果超时时间内一直没有收到领导者的消息, 它就会把角色切换成获选人, 同时把自己的 term 任期号加1, 开始一轮选举, 如果获得了集群中半数以上的节点的投票, 它就会变成领导者。如果在此过程中, 发现了集群领导者, 而且它的任期号不小于自身的任期号, 那么就把角色退化成跟随者, 如果在随机的一段超时时间到来后, 没有发现领导者也没有多数人的投票, 那么就再进行一轮新的选举。
领导者会把指令附加到日志中, 然后发起 RPC 请求给集群中的其他服务器, 让他们复制日志, 这条指令会最终在集群的每台机器上在 Raft 的状态机中执行, 日志条目只能从 leader 发送给其他服务器。
 △ 版本5
△ 版本5
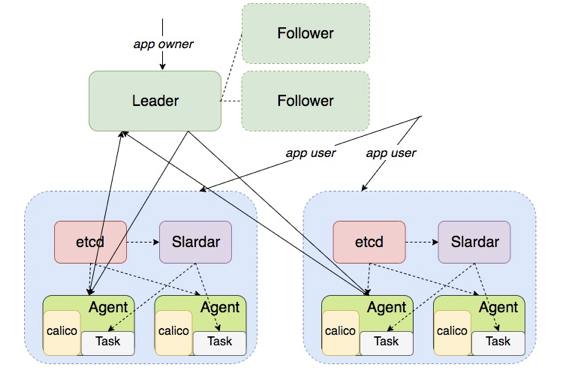
在增加了 Raft 之后,版本 5 已经是一个高可用的方案,leader 平时是会与所有的 Agent 交
互,并且它是有状态的,可以把状态同步到两个跟随者中。当 leader 挂掉时,follower 拥有 leader 完整的状态,只要重新选举出来一个成为新的 leader,服务就可以继续运行下去。
版本 6 监控与告警
由于系统中的消息都是异步交互, App 服务可以通过注册回调通知地址,来实时获取各个事件。除了用户需要及时获取一些事件(实例状态变更,服务状态变更等)之外, 我们也需要一个监控和告警方案来及时了解我们边缘服务的情况。
监控:
Agent 会收集 Metrics 到 InfluxDB, 由 Grafana 展示, 如图所示几个节点的流量监控

告警:
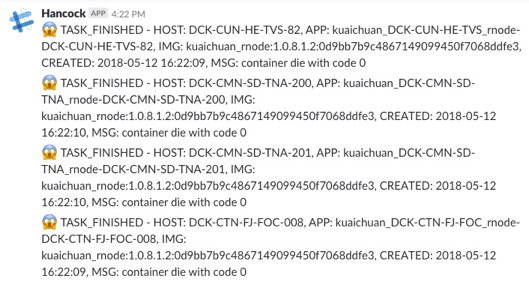
告警信息分两类, 一类是任务相关: Hancock 会发送消息到 slack , 截图是 Hancock 的一个告警信息。
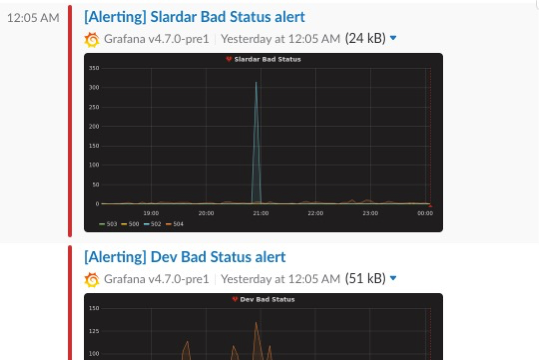
还有一类是监控相关, 比如设定的指标异常时, 发送实时消息到 slack, 截图是 slardar 上 500-504 响应的告警信息 , 可以看到在 21点左右 502 的状态出现了一个峰值,有三百多次 502.
最后有了我们现在的边缘容器调度架构。
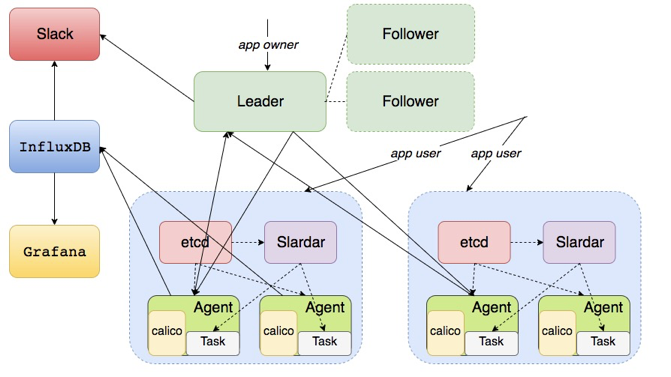
这些就是我们边缘节点容器调度架构涉及到的一些主要组件, 一些更具体的细节就不再这边一一展开了, 欢迎感兴趣的公司或个人使用我们的这个服务。
了解更多:容器云 – 全球首家分布式容器云平台