【ML入门】李宏毅机器学习笔记01-Learning Map
版权声明:小博主水平有限,希望大家多多指导。
本文仅代表作者本人观点,转载请联系知乎原作者——BG大龍。
目录
1 什么是机器学习?
2 机器学习的3个步骤
3 李宏毅老师的机器学习课程
4 按“模型的不同学习理论”分,机器学习的模型可以分为有监督学习,半监督学习,无监督学习,迁移学习和强化学习。
——4.1【解读】 有监督学习(Supervised Learning)
————4.1.1 监督学习Supervised Learning-> 回归Regression
————4.1.2 监督学习Supervised Learning-> 分类Classification
————4.1.3 分类Classification-> 线性模型Linear Model 与 非线性模型Non-Linear Model
————4.1.4 结构化学习Structuerd Learning
——4.2【解读】 无监督学习(Un-supervised Learning)-(聚类方法)
——4.3【解读】半监督学习(Semi-supervised Learning)
——4.4【解读】迁移学习Transfer Learning
——4.5【解读】强化学习(Reinforcement Learning)
1 什么是机器学习?
【01】 这是来自百度百科的介绍。
传统上,如果想让计算机工作,给它一串指令,然后计算机遵照这个指令一步步执行下去。有因有果,非常明确。但这样的方式在机器学习中行不通,机器学习根本不接受你输入的指令。
相反,它接受你输入的数据!
也就是说,机器学习是一种让计算机“利用数据而非指令”来进行各种工作的方法。
不可思议,但又非常可行。
【02】举例来说明一个机器学习的简单又经典的Application
1 我有一栋100平方房子需要售卖,我应该给它标上多大的价格?价格是100万,120万,还是140万?
很显然,我希望获得房价与面积的某种规律。
该如何获得这个规律?→使用报纸上的房价平均数据?参考别人相似面积房屋出售?无论哪种,似乎都并不是“最优解”。
我希望获得一个合理的,并且能够最大程度的反映“面积与房价关系”的规律。
2 对规律的寻找
于是我调查了周边与我房型类似的一些房子,获得一组数据。
这组数据中包含了大大小小房子的面积与价格。拟合出一条直线,让它“穿过”所有的点,并且与各个点的距离尽可能的小。——【数据处理】
通过这条直线,我获得了一个能够最佳反映房价与面积规律的规律。 这条直线用函数来表达: 房价 = 面积 * a + b ——【模型】
上述中的a、b都是直线的参数,这些参数的值我们可以调整。 ——【参数调优】
假设a = 0.75,b = 50,则房价 = 100 * 0.75 + 50 = 125万。
这个结果与我前面所列的100万,120万,140万都不一样。由于这条直线综合考虑了大部分的情况,因此从“统计”意义上来说,这是一个最合理的预测。——【预测结果】
3 回顾
例子中拟合直线的过程,可以对机器学习过程做一个完整的回顾。
1,我们需要在计算机中“存储”历史的数据。
2,我们将这些数据通过机器学习算法进行处理,这个过程在机器学习中叫做“训练”。
3,处理的结果可以被我们用来对新的数据进行预测,这个结果一般称之为“模型”。
4,对新数据的预测过程在机器学习中叫做“预测”。
4 总结
【类比人类】
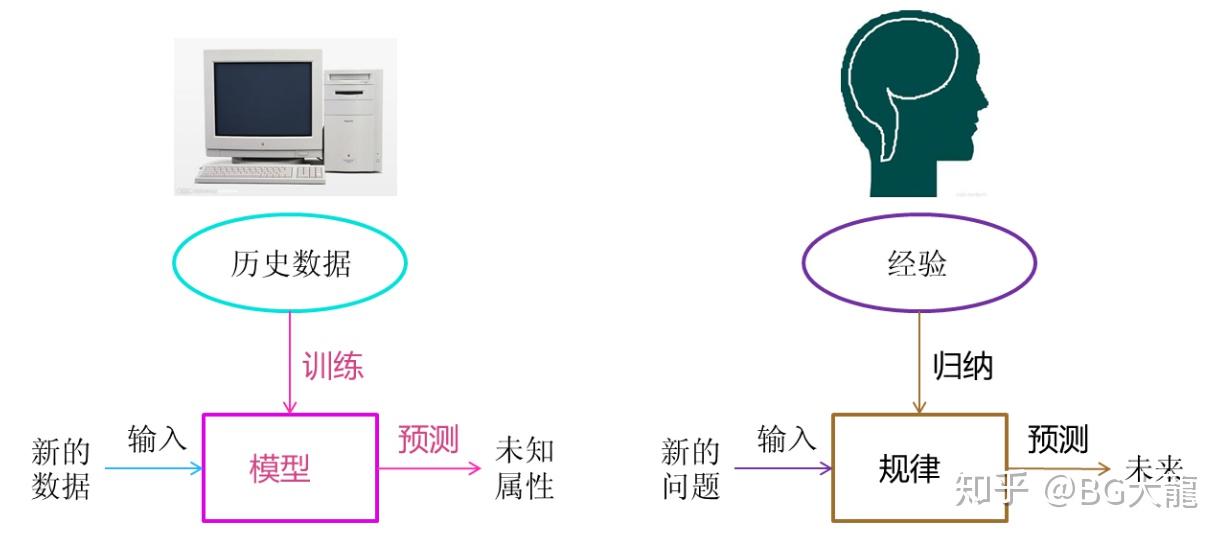
“人类通过(思考)归纳出经验的过程”转化为“计算机通过(数据的处理)训练出模型的过程”,解决更复杂、运算量更大的问题。
【总结】
机器学习方法=计算机利用历史数据,训练某种模型,利用模型预测新数据的一种方法
2 机器学习的3个步骤
通常学习一个好的函数,分为以下三步:
- 选择一个合适的模型Model。这通常需要依据实际问题而定,针对不同的问题和任务需要选取恰当的模型,模型就是一组函数的集合。
- 判断一个函数的好坏Goodness of function。这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function)。损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
- 找出“最好”的函数function。如何从众多函数中最快的找出“最好”的那一个,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。
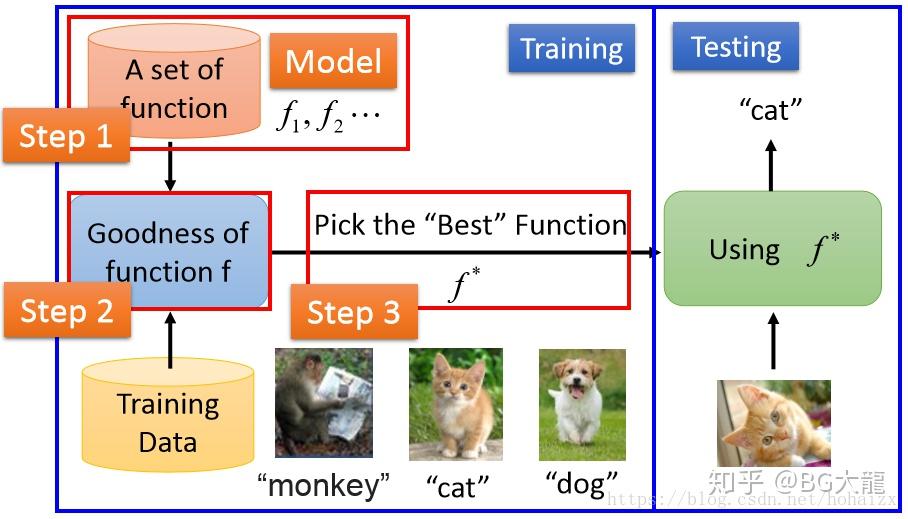
PS:学习得到“最好”的函数后,需要在新样本上进行测试,只有在新样本上表现很好,才算是一个“好”的函数。
也就是,【训练集】→【测试集】
3 李弘毅老师的机器学习课程
【01】2017-秋季机器学习-课程链接

这是李宏毅老师的个人网站主页,里面有PDF文件和Video课程。
【02】2017-秋季机器学习-【课程作业】链接
maplezzz/NTU_ML2017_Hung-yi-Lee_HWgithub.com
【03】课程框架
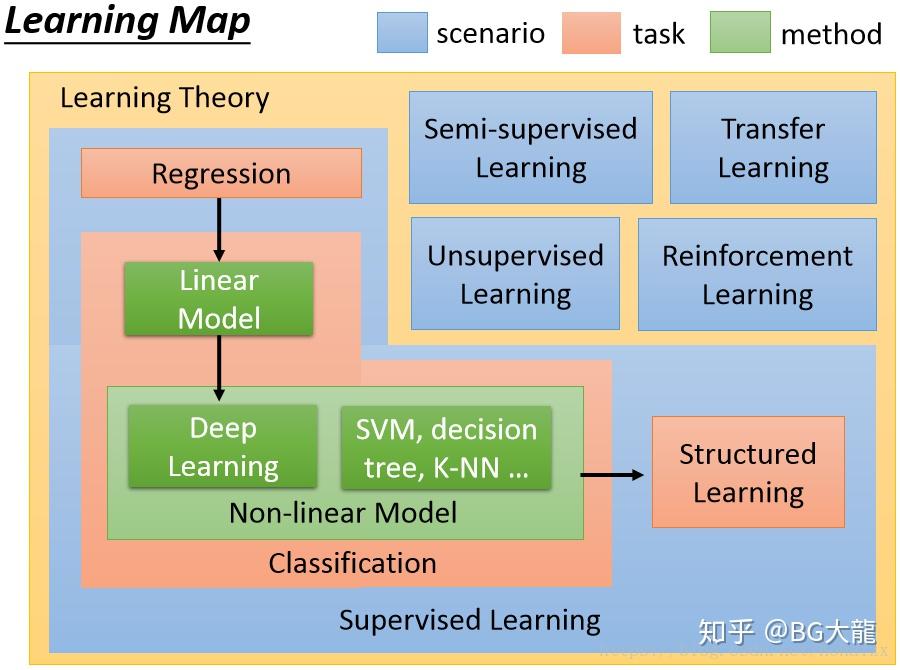
机器学习是一个庞大的家族体系,涉及众多算法,任务和学习理论。
蓝色代表不同的学习理论,红色代表任务,绿色代表方法。
根据李宏毅老师的框架,我自己制作了思维导图
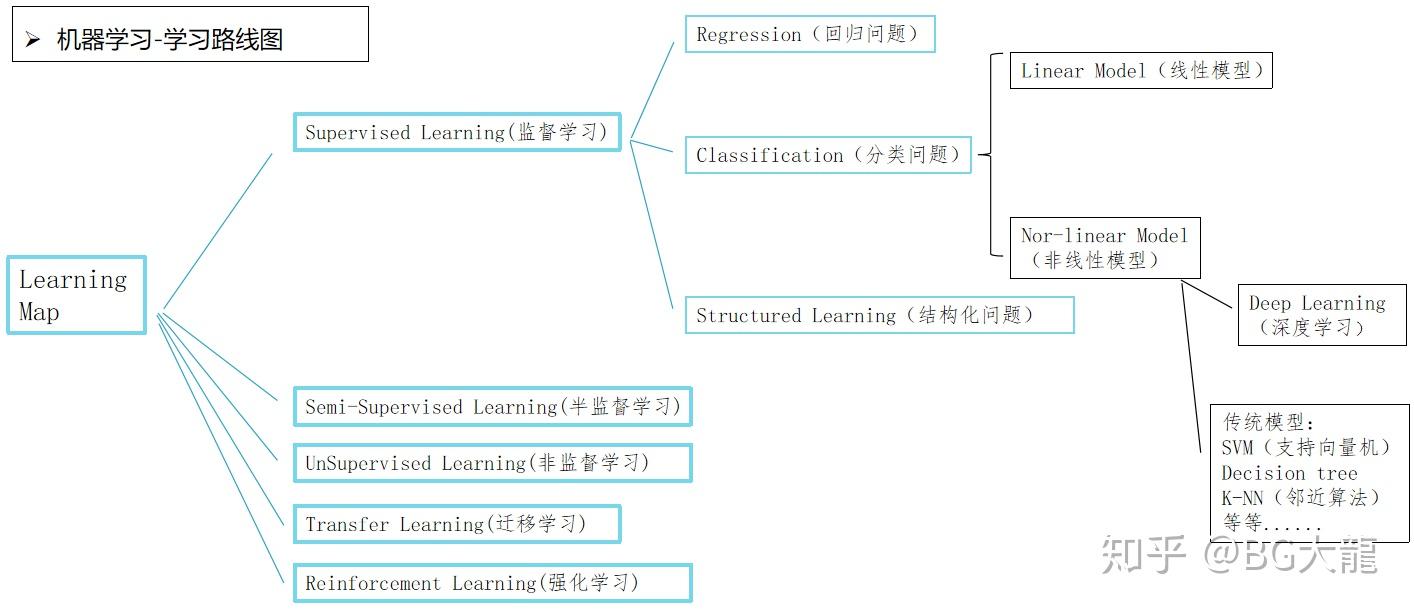
4 按“模型的不同学习理论”分——机器学习的模型可以分为有监督学习,半监督学习,无监督学习,迁移学习和强化学习。
【01】蓝色部分代表scenario,意思是你现在的 training data是什么样的类型
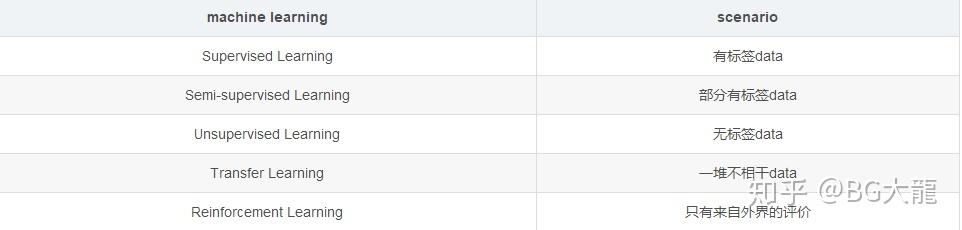
#训练样本带有标签时,是有监督学习;
#训练样本部分有标签,部分无标签时是半监督学习;
#训练样本全部无标签时,是无监督学习;
#迁移学习,就是就是把已经训练好的模型参数,迁移到新的模型上以帮助新模型训练。
#强化学习是一个学习最优策略(policy),可以让本体(agent)在特定环境(environment)中,根据当前状态(state),做出行动(action),从而获得最大回报(reward)。
强化学习和有监督学习最大的不同是,每次的决定没有对与错,而是希望获得最多的累计奖励。
【02】 在有监督学习中,按任务类型(红色)分,机器学习模型可以分为回归模型、分类模型和结构化学习模型。

#回归模型又叫预测模型,输出是一个不能枚举的数值;
#分类模型又分为二分类模型和多分类模型,常见的二分类问题有垃圾邮件过滤,常见的多分类问题有文档自动归类;
#结构化学习模型的输出不再是一个固定长度的值,如图片语义分析,输出是图片的文字描述
===================这是一条有“灵魂”的分割线=================
4.1【解读】 有监督学习(Supervised Learning)
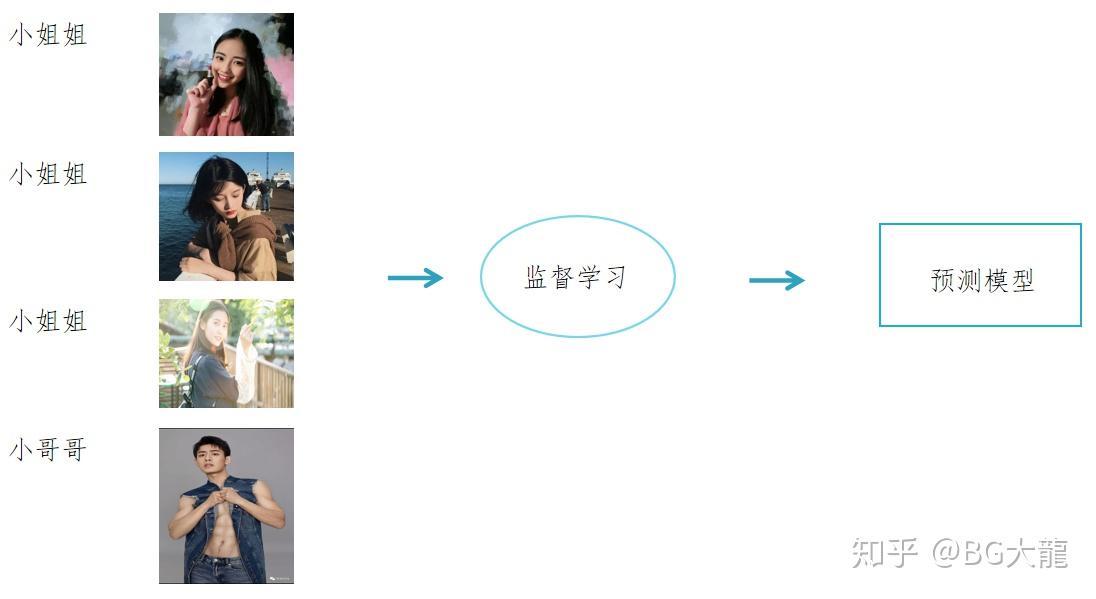
所谓监督学习,利用一组“已知类别的样本”去调整分类器的参数,使其达到能区别新样本类别的效果。
正如下图中给出了好多男生女生的特征,我们指示出,哪些男生哪些是女生,然后让计算机进行学习,计算机要通过学习,才能具有识别各种事物和现象的能力。
用来进行学习的材料,就是【与被识别对象】属于同类的有限数量样本,在本例子中指的是那些选择的男生女生。
除此之外,监督学习中在给予计算机学习样本的同时,还告诉计算各个样本所属的具体类别。
- 训练集
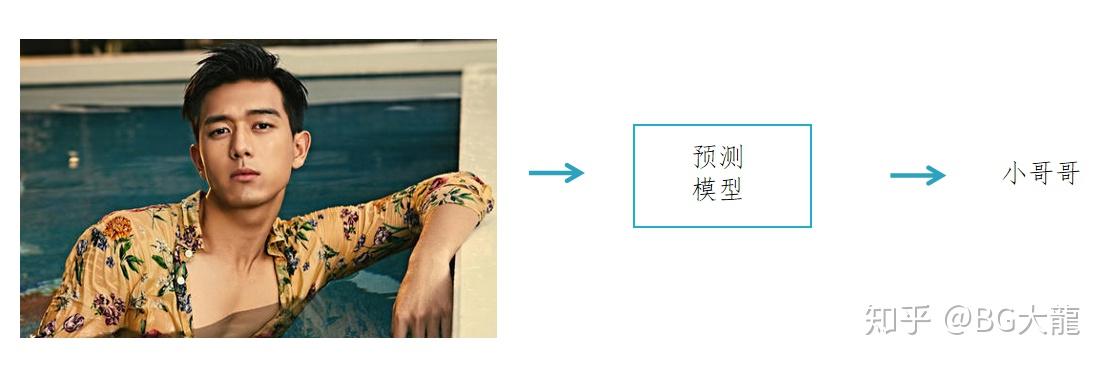
当再次给出一个特征图片的时候,就可以通过预测模型进行判断。
如下图判断【李现】,输出是 小哥哥。
- 测试集
用最通俗的话说,我们先来定义所谓的【对 / 错】,从而建立一个标准。
监督学习就是标明一些数据是对的,另一些数据是错的,然后让程序预测新的数据是对的还是错的。
所以说,有监督学习,必须是有标签的。而这个标签,就是“某种标准”。
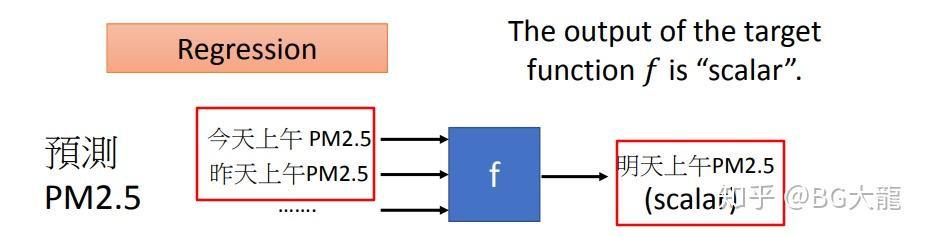
4.1.1 监督学习Supervised Learning-> 回归Regression
举个例子: 预测PM2.5,进行天气预报
核心思想就是:连续函数下进行预测。
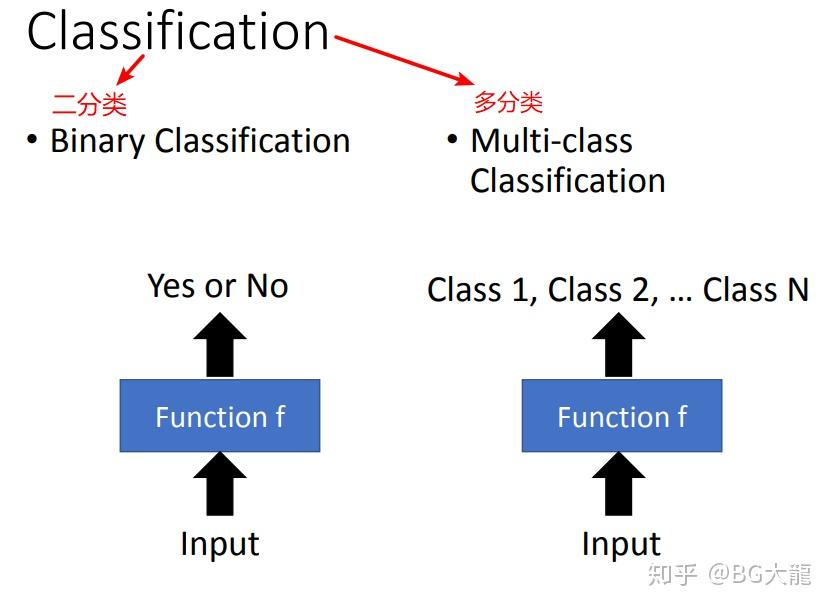
4.1.2 监督学习Supervised Learning-> 分类Classification
分类问题有两种情景。
二分类Binary Classification 输出是或否,多分类Multi-class Classification输出多个类型。
举个例子:
Binary Classification:
Spam filtering(垃圾邮件过滤),判断是垃圾邮件或不是垃圾邮件。
Multi-classification:
Document Classification(文件分类),将文件分为政治、经济、体育等多个大类。
4.1.3 分类Classification-> 线性模型Linear Model 与 非线性模型Non-Linear Model
Linear Model : 能做的事有限,一些简单的模型可以用它来做。
但遇到复杂问题就力不从心。但作用不可忽视,线性模型是非线性模型的基础,很多非线性模型都是在线性模型的基础上变换而来的。
Non-linear Model : 非线性模型=传统模型(SVM,KNN,决策树等)+深度学习模型
- 例1,深度学习的application
- 分类案例-图片识别
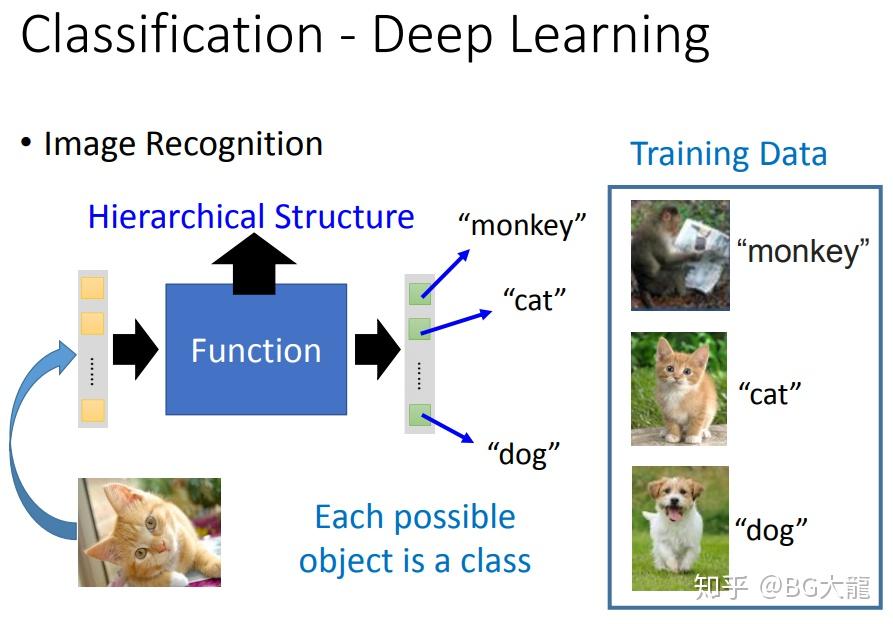
- Classification-Image Recognition:输入一个图片,通过一个很复杂的卷积神经网络(CNN)的模型,判断是猫是狗还是猴子,每个可能的物种是class。
- 例2,深度学习的application
- 分类案例-阿法狗
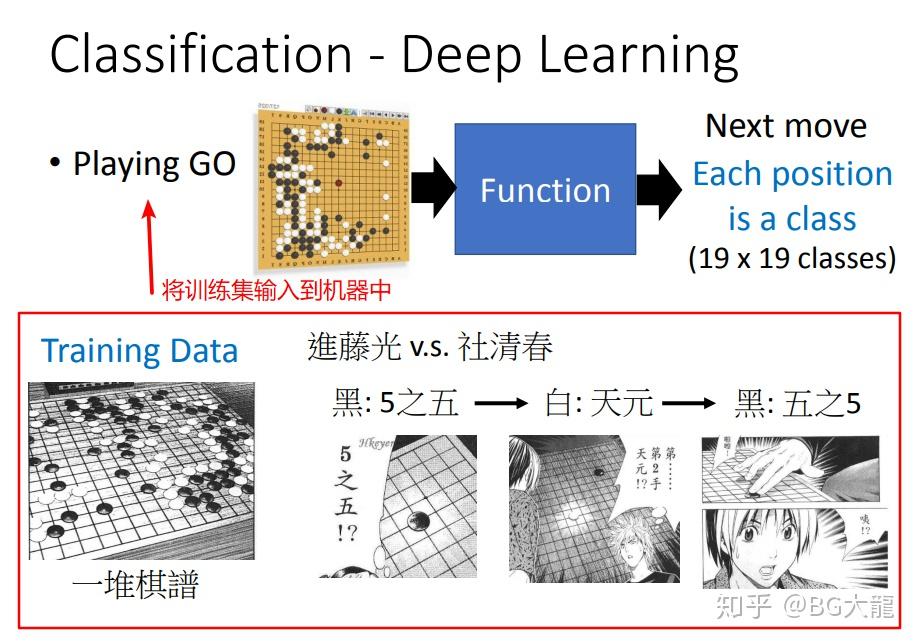
- Classification-Playing Go:输入棋谱,让Playing Go学习分析棋盘上的局势,判断下一个落子的位置,每一个可能的落子位置就是一个class。
4.1.4 结构化学习Structuerd Learning
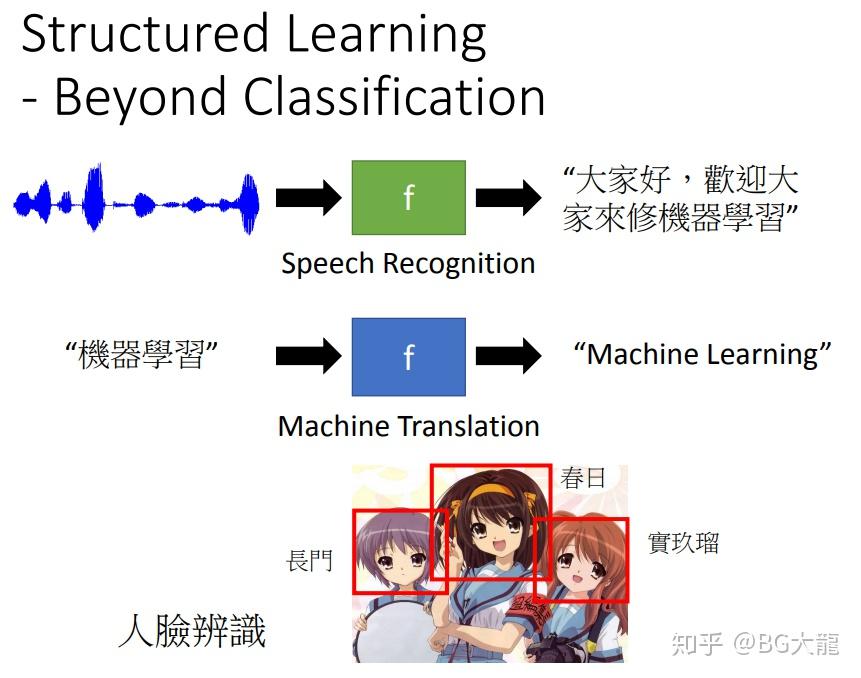
在实际运用中,常常会遇到Beyond Classification的情况。
比如【语音识别】,【人脸识别】,【语言翻译】等,是结构化输出。
此类问题,常配合强化学习Reinforcement Learning 解决。
===================这是一条有“灵魂”的分割线=================
4.2【解读】 无监督学习(Un-supervised Learning)-(聚类)
无监督学习常常被用于数据挖掘,用于在大量无标签数据中发现些什么。
它的训练数据是无标签的,训练目标是能对【观察值】进行分类或者区分。
无监督主要有三种:聚类、离散点检测和降维。我们主要讲聚类。
- 聚类就是将观察值聚成一个一个的组,每一个组都含有一个或者几个特征。
- 可以想象,恰当地提取特征是无监督最为关键的环节。
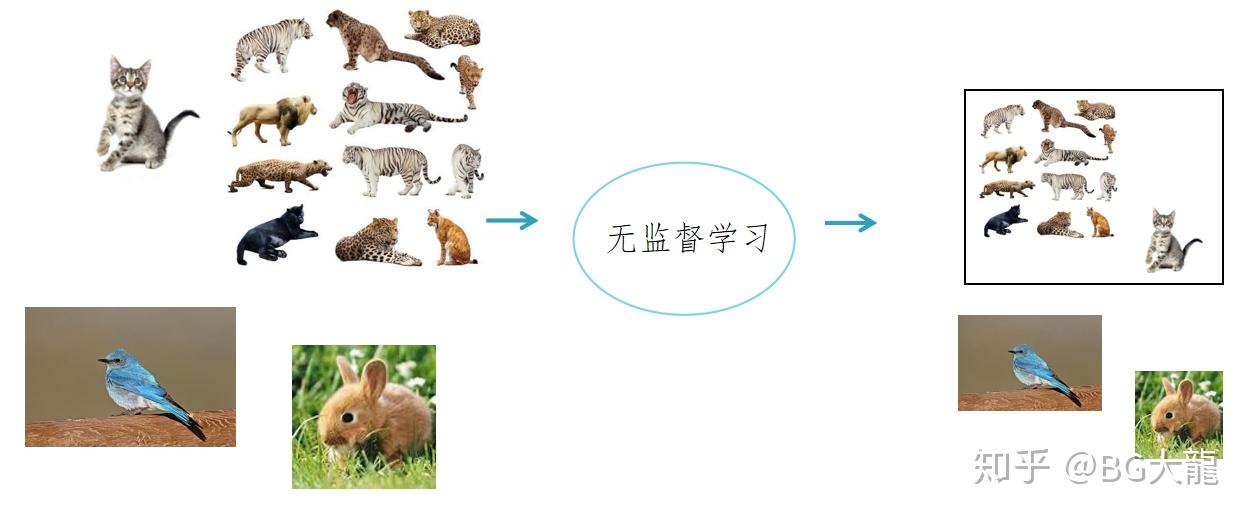
例如,在猫的识别中,我们来尝试提取猫的特征:皮毛、四肢、耳朵、眼睛、胡须、牙齿、舌头等等。通过对特征相同的动物的聚类,可以将猫或者猫科动物聚成一类。
但是此时,我们不知道这群毛茸茸的东西是什么,我们只知道,这团东西属于一类,兔子不在这个类(耳朵不符合),鸟也不在这个类(有翅膀)。
值得注意:聚类中,特征有效性直接决定着算法有效性。如果我们拿体重来聚类,而忽略体态特征,恐怕就很难区分出兔子和猫了。
简单地说,无监督学习,能在不给任何额外提示的情况下,让机器自动去判断,哪些数据比较有共同特征,或者说哪些数据应该归成一类。
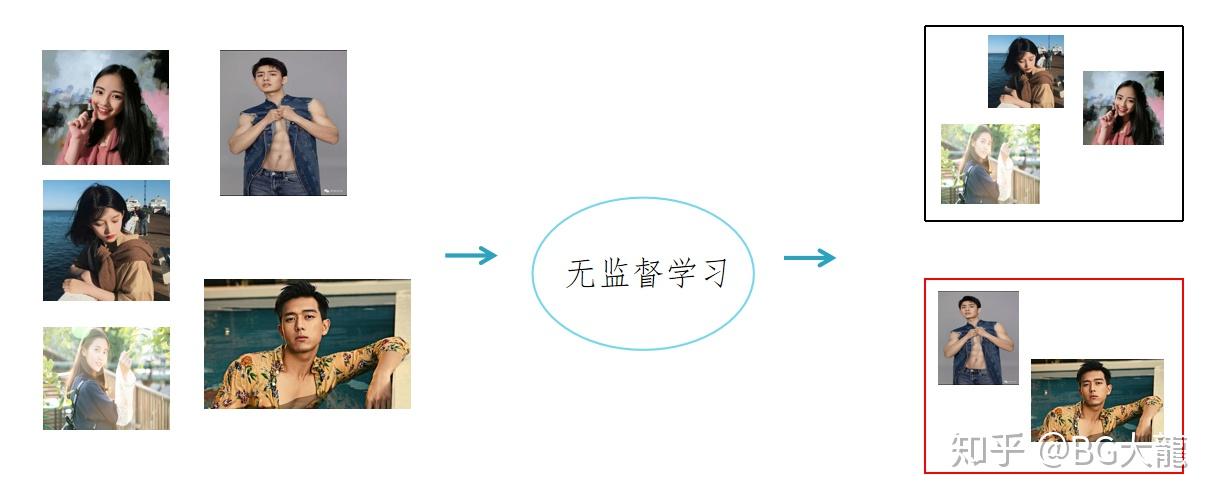
例1: 让机器学会阅读。希望机器自己在网络上爬去很多文章,自己理解其中的意思,进而取得人类的一些理解,掌握阅读的技巧,这就是无监督学习要做的。
我们知道,做machine Learning就是要找一个function。在“学会阅读”这个系统里,我们给系统input一个“apple”词汇,然后让机器看懂。
而在Unsupervised Learning 中没有人告诉机器每个词汇表示什么意思,只有大量text喂给机器。

例2:要让机器学会自主绘画。
我们只给机器呈现显示世界中的景象并不做标识,机器要从中提炼绘画风格与内容,学会通过绘画表达自己。
===================这是一条有“灵魂”的分割线=================
4.3【解读】半监督学习(Semi-supervised Learning)
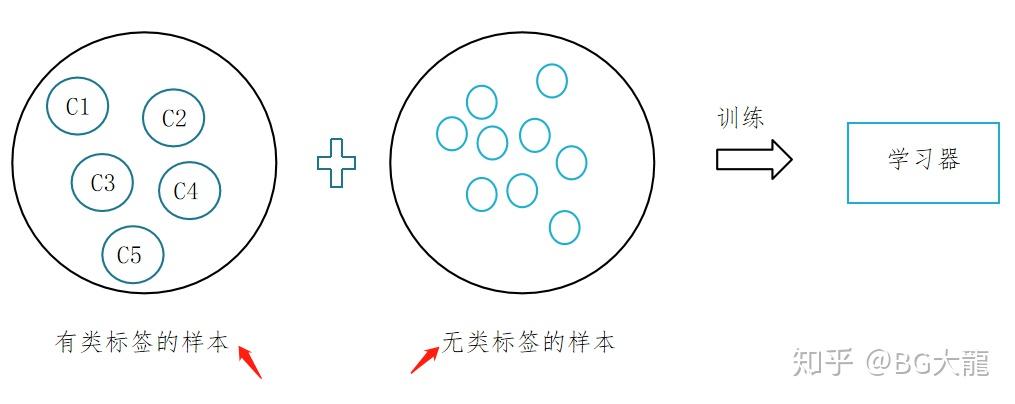
半监督学习,是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。
半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。
事实上,无标记样本虽未包含标记信息,但它们与有标记样本一样都是从总体中独立同分布采样得到,因此它们所包含的数据分布信息对学习器的训练大有裨益。
如何让学习过程不依赖外界的咨询交互,自动利用未标记样本所包含的分布信息的方法便是半监督学习(semi-supervised learning)
通过下图来进行举例。
训练集同时包含有标记样本数据和未标记样本数据。
当新样本进来的时候,就会对它的特征进行判断,也就是:
是否是某类进行判断,是否需要归为相同的类。
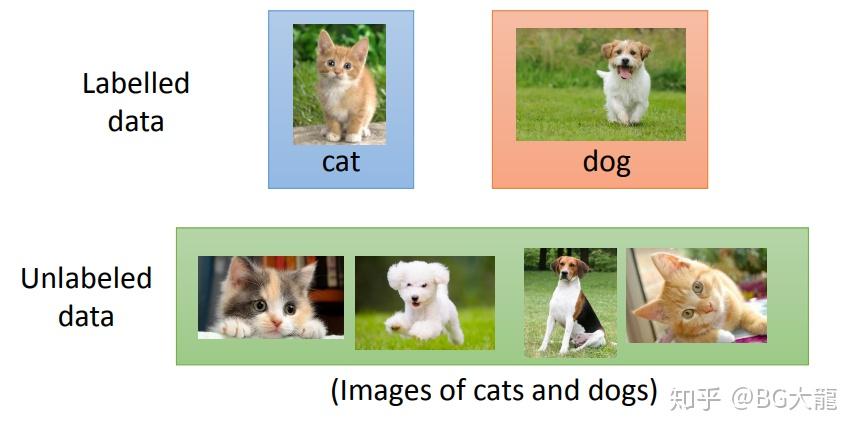
例如:一个辨识猫与狗的系统。
手上有一部分Labelled data(已经标记好的猫狗图片),和一部分Unlabeled data(未做过标记的猫狗图片)
那么Semi-supervised Learning做的就是利用Unlabeled data优化function
也常用于数据不足时进行学习
===================这是一条有“灵魂”的分割线=================
4.4【解读】迁移学习Transfer Learning
迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。
学习迁移是指一种学习对另一种学习的影响,或习得的经验对完成其他活动的影响
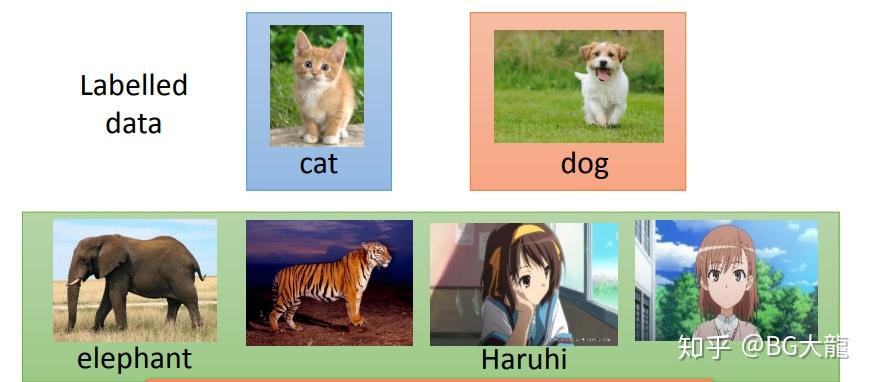
例如:还是建立辨识猫与狗的系统。
手上有一部分Labelled data(已经标记好的猫狗图片),和另一部分与猫狗没有关系的图片(比如狮子老虎,标未标记都可),那么Transfer Learning就是利用这些data优化function
PS:如果想深入了解【迁移学习】,我觉得这个链接不错的一个介绍。
迁移学习简介 – 夜尽天明00 – 博客园www.cnblogs.com
===================这是一条有“灵魂”的分割线=================
4.5【解读】强化学习(Reinforcement Learning)
在实际运用中,以上方法并不能解决全部问题,常常会遇到Beyond Classification的情况,比如语音识别,人脸识别,语言翻译等,那么就要通过强化学习来解决问题。
1 强化学习的核心是这样一个概念,即最佳的行为或行动是由积极的回报来强化的。
机器使用强化学习算法,通过【以环境的反馈为基础】来确定理想行为。 强化学习算法可以在必要时随时间保持适应环境,以便长期获得最大的回报。
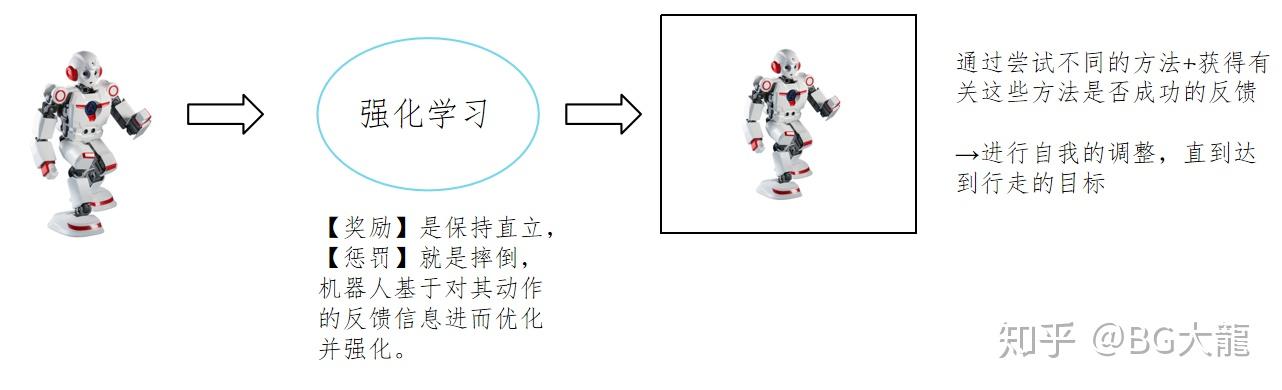
例如:行走的机器人
一个通过强化学习来学习行走的机器人,将通过尝试不同的方法,获得有关这些方式成功的反馈,然后进行自我的调整直到达到行走的目标。大步伐会让机器人摔倒,通过调整步距来判断这是否是保持直立的原因,通过不同的变化持续学习,最终能够行走。
以上说明,【奖励】是保持直立,【惩罚】就是摔倒,机器人基于对其动作的反馈信息进而优化并强化。
强化学习Reinforcement VS 监督学习Supervised
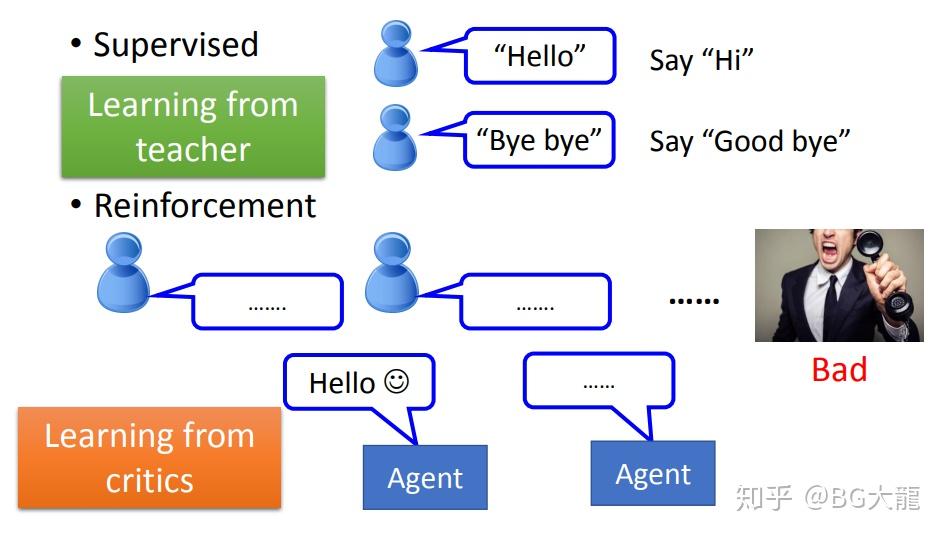
强化学习与监督学习有什么区别呢?
例1:语音识别。
Supervised 就像给了机器一个点读机,机器听到一句话时可以看到其含义,每一句话都有标签,就像有一个手把手教他的老师。
Reinforcement 就像跟老朋友对话,他反复讲来回讲很多句话你却无言以对,直到老朋友愤然离去。
机器唯一可以知道的就是他做的好还是不好=【根据评价去学习】,除此之外没有任何information。
而这,更像人类现实生活中的学习过程,必须自己知道哪里做得好做得不够好,怎么修正。
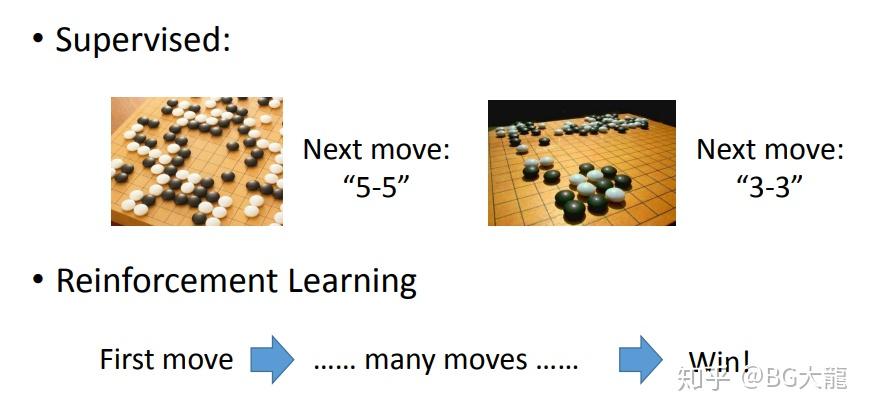
例2:下围棋。
supervised: 给机器一堆棋谱,告诉机器,情况a则落子在“5-5”处,情况b则落子在“3-3”处,…….
Reinforcement : 让机器自己下棋,下过几百手之后,机器只知道自己赢了还是输了,下的好还是不好,机器必须自己想办法做提高