【决战西二旗】|快速排序的优化
1.前言
前面的一篇文章https://www.cnblogs.com/backnullptr/p/11934841.html讲了快速排序的基本概念、核心思想、基础版本代码实现等,让我们对快速排序有了一个充分的认识,但还无法达到面试中对快速排序灵活应对的程度。
快速排序是图领奖得主发明的算法,被誉为20世纪最重要的十大算法之一,快速排序为了可以在多种数据集都有出色的表现,进行了非常多的优化,因此对我们来说要深入理解一种算法的最有效的手段就是不断优化提高性能。
通过本文你将了解到以下内容:
- 快速排序和归并排序的分治过程对比
- 快速排序分区不均匀的影响
- 快速排序的随机化基准值
- 快速排序的三分区模式
- 快速排序和插入排序的混合
2.快速排序的分区过程
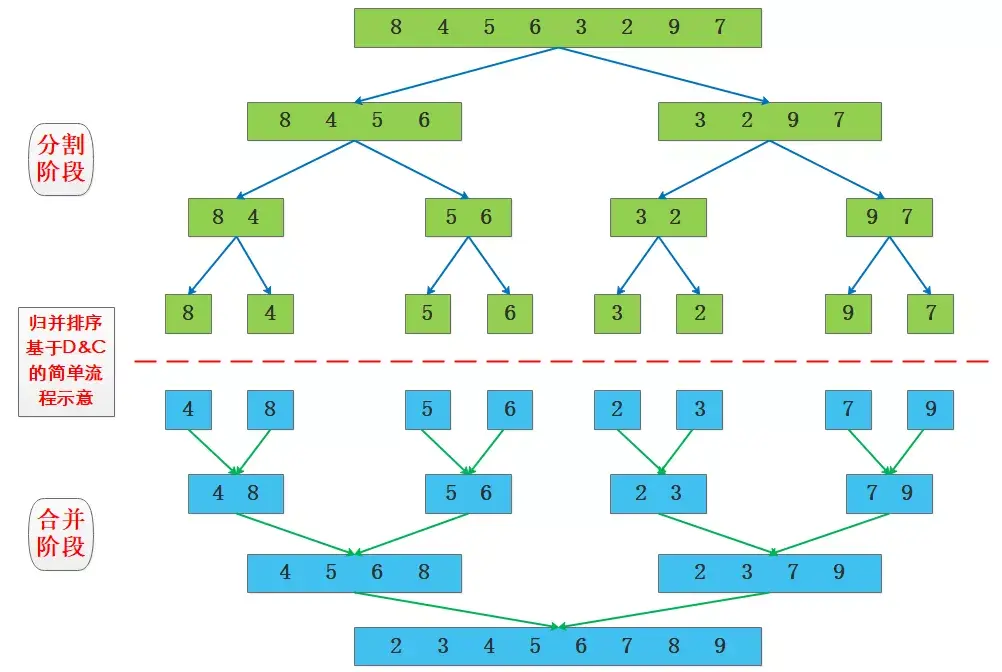
快速排序和归并排序采用的基本思想都是分治思想Divide&Conquer,从D&C思想来看最主要的部分就是分割和合并,两种算法在使用D&C时侧重点有一些差异:
- 归并排序在分割时处理很简单,在合并时处理比较多,重点在合并。
- 快速排序在分割时处理比较复杂,由于交换的存在递归结束时就相当于合并完成了,重点在分割。
2.1 归并排序分治示意图
2.2 快速排序分治示意图
注:快排的过程就不写具体的数字了 仅为达意 点到即可。
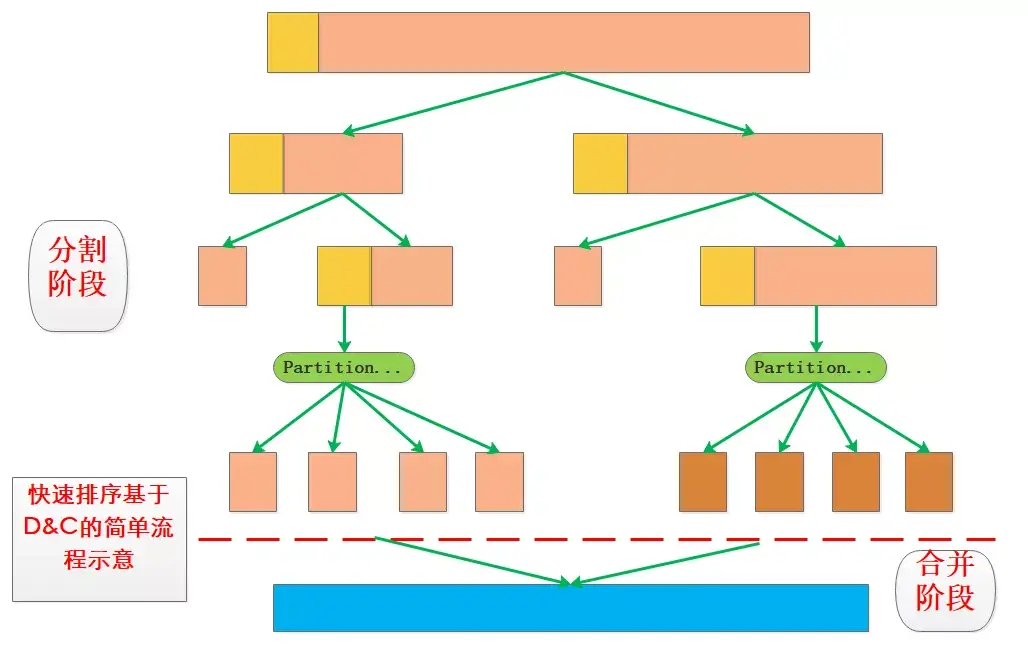
可以明显看出来,快速排序在选择基准值时对整个分治过程影响很大,因为下一个环节的分治是基于前一环节的分割结果进行的。
2.3 快速排序划分不均匀情况
考虑一种极端的情况下,如果基准值选取的不合理,比如是最大的或者最小的,那么将导致只有一边有数据,对于已经排序或者近乎有序的数据集合来说就可能出现这种极端情况,还是来画个图看下:
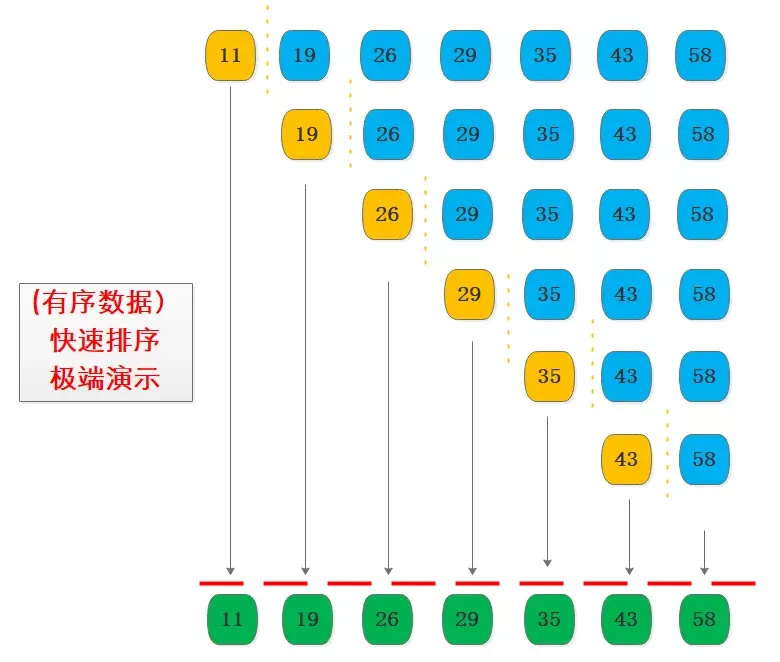
图中展示了每次分治都选择第一个元素作为基准值,但是每次的基准值都是最小值,导致每次基准值左侧没有子序列,除了基准值之外全部元素都在右子序列。
2.4 概率和复杂度计算
每次分割排序之后,只能在有序序列中增加1个元素递归树变成了单支树并且递归深度变大,极端情况的出现概率和最坏复杂度计算如下:

极端情况概率就是每次在剩余所有元素中挑出最小的,这样每次的概率都是1/(n-i),所以组合起来就是1/(n!),所以随机数据集合出现最差情况的概率非常低,但是有序数据下固定基准值选择就可能造成极端情况的出现。
最坏复杂度相当于每次从n-i个元素中只找到1个数据,将所有情况累加也就达到了O(n^2)级别,并不是递归过程全都挑选了最值作为基准值才会出现O(n^2)的复杂度,复杂度是一个概率化的期望值,具体的系数不同影响也很大。
3. 快速排序基准值选取优化
3.1 分割越均匀速度越快
从上面的几张图可以清晰看到基准值的不同对于D&C过程的分割会产生很大的影响,为了保证快速排序的在通用数据集的效率,因此我们需要在基准值的选取上做一些决策,换句话说就是让选取的基准值每次都可以尽可能均匀地分割数据集,这样的效率是最高的。
3.2 随机选取基准值
网上有很多选择方法比如固定选取第一个、固定选取最后一个、固定选择中间值、三值平均选取等,不过个人觉得每一次都随机选取某个位置的数据作为基准值,然后与第一个值互换,这样就相当于每次的基准值都是随机选择的,就将固定index带来的问题,大大降低了。
3.3 随机vs固定对比试验
接下来做一组对比试验,生成一个0-100000的有序数组,代码增加了很多选择项和时间测量代码,测试代码如下:
- #include<iostream>
- #include<sys/time.h>
- #include<stdlib.h>
- #define SIZE 100000
- using namespace std;
- //获取从[start-end)之间的随机index
- int getrandom(int start,int end){
- srand((unsigned int)time(NULL));
- return (rand()%(end-start))+start;
- }
- //获得毫秒时间戳
- long getCurrentTime() {
- struct timeval tv;
- gettimeofday(&tv,NULL);
- return tv.tv_sec*1000 + tv.tv_usec/1000;
- }
- template <typename T>
- void quick_sort_recursive(T arr[], int start, int end, string& method) {
- if (start >= end)
- return;
- //产生随机索引 并与end交换 之后与原来的处理一致
- if(method=="random"){
- int randindex = getrandom(0,end-start);
- std::swap(arr[end],arr[randindex]);
- }
- T mid = arr[end];
- int left = start, right = end - 1;
- //在整个范围内搜寻比枢纽元值小或大的元素,然后将左侧元素与右侧元素交换
- while (left < right) {
- //试图在左侧找到一个比枢纽元更大的元素
- while (arr[left] < mid && left < right)
- left++;
- //试图在右侧找到一个比枢纽元更小的元素
- while (arr[right] >= mid && left < right)
- right--;
- //交换元素
- std::swap(arr[left], arr[right]);
- }
- if (arr[left] >= arr[end])
- std::swap(arr[left], arr[end]);
- else
- left++;
- quick_sort_recursive(arr, start, left-1, method);
- quick_sort_recursive(arr, left+1, end, method);
- }
- //模板化
- template <typename T>
- void quick_sort(T arr[], int len, string& method) {
- quick_sort_recursive(arr, 0, len-1, method);
- }
- int main(int argc,char *argv[])
- {
- if(argc < 2){
- cout<<"give me a method:fix or random"<<endl;
- return -1;
- }
- string method = string(argv[1]);
- cout<<method<<endl;
- int a[SIZE]={};
- //产生有序数据
- for(int i=0;i<100000;i++)
- a[i]=i+1;
- int len = sizeof(a)/sizeof(int);
- long start = getCurrentTime();
- quick_sort(a,len-1,method);
- long end = getCurrentTime();
- cout<<len<<"有序数据耗时统计:"<<endl;
- cout<<"START@:"<<start<<"ms"<<endl;
- cout<<"END@:"<<end<<"ms"<<endl;
- cout<<"COST:"<<end-start<<"ms"<<endl;
- }
笔者使用相同的数据集在fix和random模式下,后者的耗时只有前者的大约1/10,不过在我的电脑上上面的代码耗时比我预期大很多,还是存在优化空间,所以某些场景下随机化带来的性能提升很明显,是一个惯用的优化方法。
4. 快速排序的三分区模式原理
前面的路子都是以基准值为准分为小于子序列和大于子序列,考虑一种特殊的数据集,数据集中有大量重复元素,这种情况下使用两分区递归会对大量重复元素进行处理。
一个优化的方向就是使用三分区模式:小于区间、等于区间、大于区间,这样在后续的处理中则只需要处理小于区和大于区,降低了等于基准值区间元素的重复处理,加速排序过程。
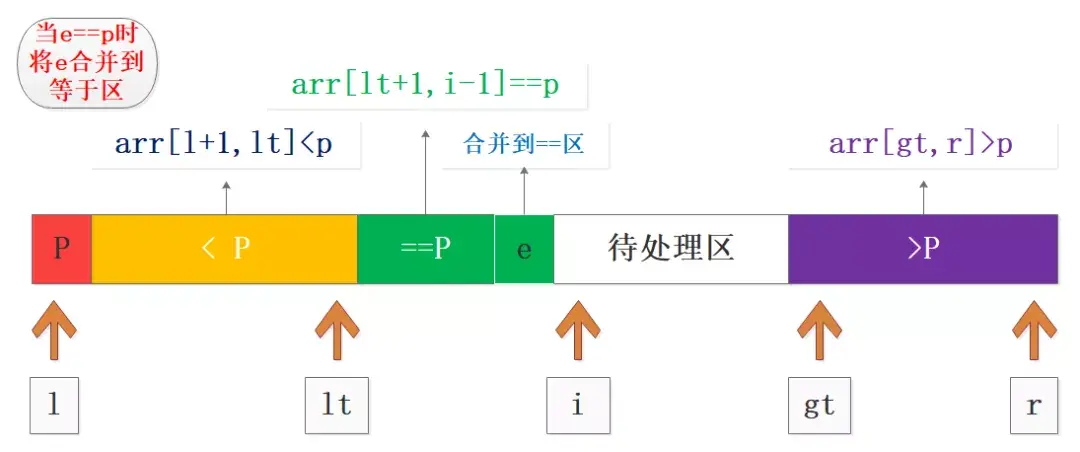
如图为三分区模式中某个时刻的快照,其中展示了几个关键点和区间,包括基准值、小于区、等于区、处理值、待处理区、大于区。
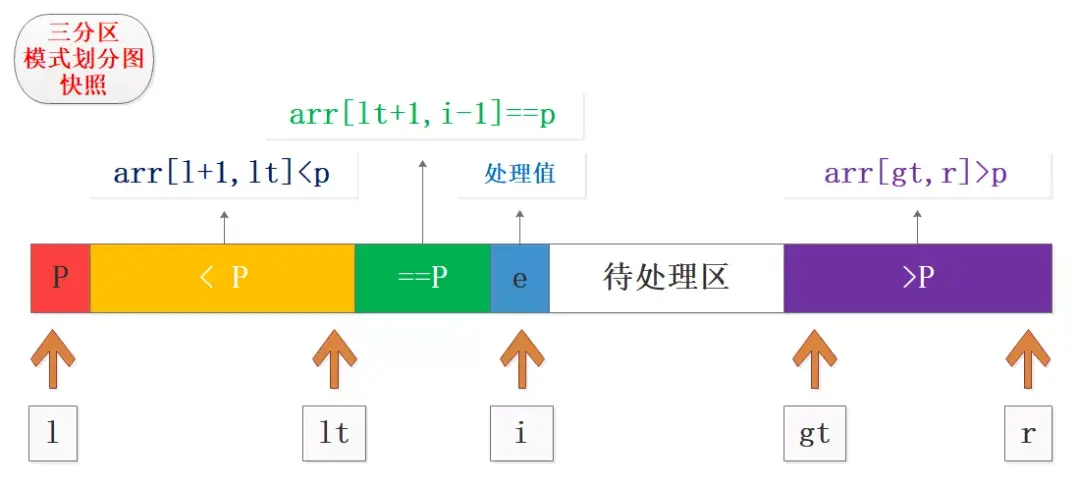
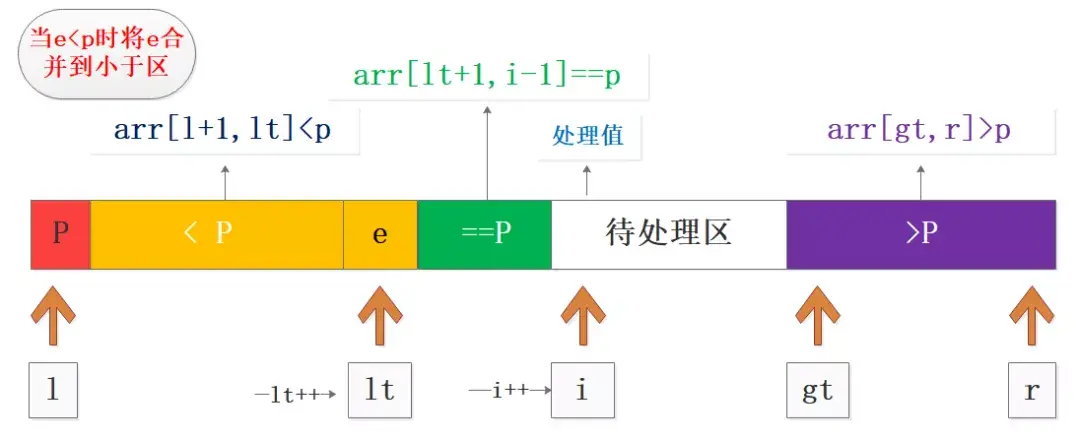
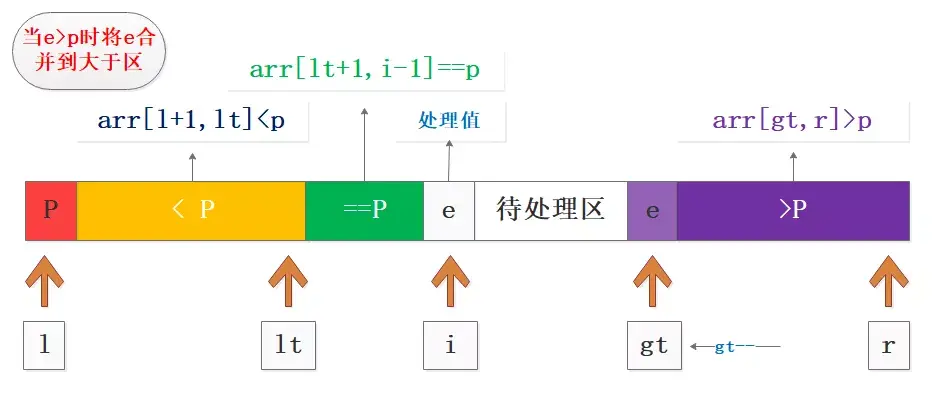
在实际过程中根据处理值与基准值的大小关系,进行相应分区合并和交换,再进行下标移动就可以了,实际中分三种情况,这也是写代码的依据:
- 处理值e==p,将e合并到等于区,i++;
- 处理值e<p,将e与(lt+1)位置的数据交换,扩展小于区lt++,等于区长度不变,相当于整体平移;
- 处理值e>p,将e与(gt-1)位置的数据交换,扩展大于区gt–,此时i不变,交换后的值是之前待处理区的尾部数据;
- e==p的合并
- e<p的合并
- e>p的合并
- 分区最终调整
处理完待处理区的全部数据之后的调整也非常重要,主要是将基准值P与lt位置的数据交换,从而实现最终的三分区,如图所示:
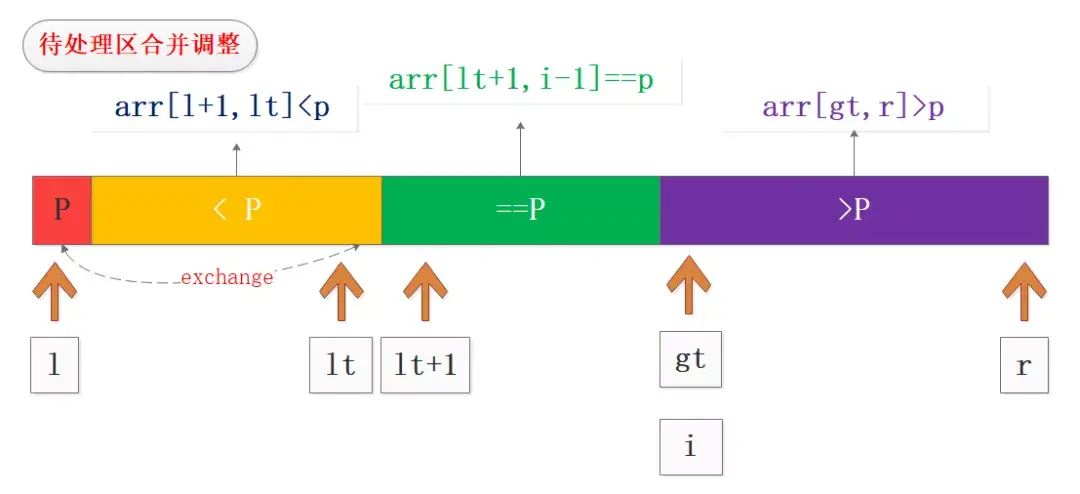
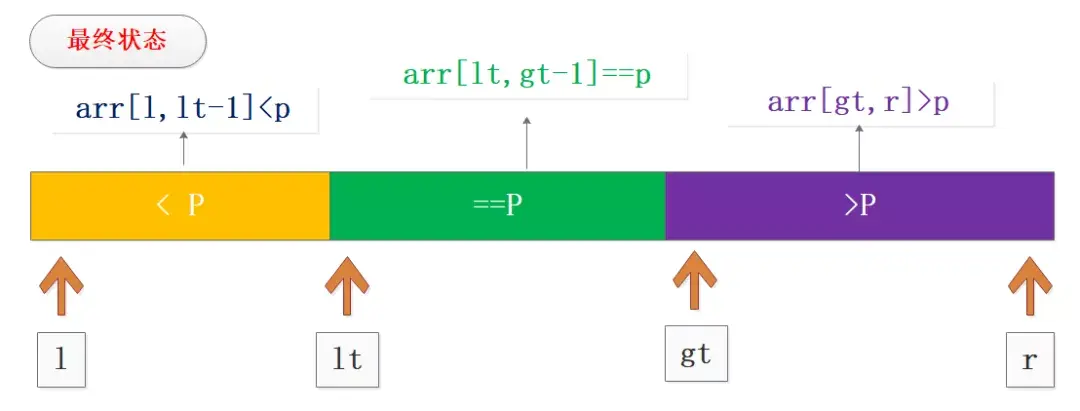
从最终的分区可以看到,我们下一次的循环可以不处理等于区的数据而只处理两端分区数据,这样在大量重复场景下优化效果会非常明显。
4. 三分区模式代码试验
- #include<iostream>
- #include <ctime>
- #include<stdlib.h>
- #include<sys/time.h>
- using namespace std;
- #define SIZE 1000000
- void quickSort3Way(int arr[], int l, int r) {
- if (l >= r)
- return;
- //随机选择要做比较的值
- swap(arr[l], arr[rand() % (r - l + 1) + l]);
- int v = arr[l];
- int i = l + 1;
- int lt=l;
- int gt = r;
- while (i<gt+1) {
- //处理值小于基准值 合并到小于区
- if (arr[i] < v) {
- swap(arr[i], arr[lt+1]);
- lt++;
- i++;
- }
- //处理值大于基准值 合并到大于区
- else if (arr[i] > v) {
- swap(arr[i], arr[gt]);
- gt--;
- }
- //处理值等于基准值 合并到等于区
- else{
- i++;
- }
- }
- //最终调整
- swap(arr[l], arr[lt]);
- //获取下一次处理的左右边界 小于区右边界lt-1 大于区左边界gt
- quickSort3Way(arr, l, lt-1 );
- quickSort3Way(arr, gt, r);
- }
- //获得毫秒时间戳
- long getCurrentTime() {
- struct timeval tv;
- gettimeofday(&tv,NULL);
- return tv.tv_sec*1000 + tv.tv_usec/1000;
- }
- int main()
- {
- int arr[SIZE]={};
- for(int i=0;i<SIZE;i++)
- arr[i]=i%10;
- long start = getCurrentTime();
- quickSort3Way(arr,0,SIZE-1);
- long end = getCurrentTime();
- int len = sizeof(arr)/sizeof(int);
- cout<<len<<"有序数据耗时统计:"<<endl;
- cout<<"START@:"<<start<<"ms"<<endl;
- cout<<"END@:"<<end<<"ms"<<endl;
- cout<<"COST:"<<end-start<<"ms"<<endl;
- return 0;
- }
代码测试了100w数据,数据是0-10的循环重复,测试耗时如下:
- 1000000有序数据耗时统计:
- START@:1575212629852ms
- END@:1575212629878ms
- COST:26ms
笔者使用相同的数据集在二分区模式下测试10w数据规模耗时大约是1800ms,数据集减少10倍耗时却增大了几十倍,或许二分区代码还是存在优化空间,不过这个对比可以看到存在大量重复元素时三分区性能还是很不错的。
5. 快速排序和插入排序混合
插入排序在数据集近乎有序的前提下效率可以到达O(n),快速排序在递归到末尾时当序列的元素数较少时,可以用插入排序来代替后续的递归处理过程,从而结合二者的优点进行加速,写一段简单的伪代码表示:
- //当序列中的数据数量小于15时 采用插入排序
- if(r-l < 15){
- insertsort(arr,l,r)
- }
6. 总结
快速排序是基于D&C思想实现的,最核心的部分就是分区Partition的过程,该过程可以有很多写法。
对快速排序的优化主要体现在基准值选取、数据集分割、递归子序列选取、其他排序算法混合等方面,换句话说就是让每次的分区尽量均匀且没有重复被处理的元素,这样才能保证每次递归都是高效简洁的。