微软看上的Rust 语言,安全性真的很可靠吗
摘要:近几年,Rust语言以极快的增长速度获得了大量关注。其特点是在保证高安全性的同时,获得不输C/C++的性能。在Rust被很多项目使用以后,其实际安全性表现到底如何呢?
近几年,Rust语言以极快的增长速度获得了大量关注。其特点是在保证高安全性的同时,获得不输C/C++的性能,让系统编程领域难得的出现了充满希望的新选择。在Rust被很多项目使用以后,其实际安全性表现到底如何呢?今年6月份,来自3所大学的5位学者在ACM SIGPLAN国际会议(PLDI’20)上发表了一篇研究成果,针对近几年使用Rust语言的开源项目中的安全缺陷进行了全面的调查。
这项研究调查了5个使用Rust语言开发的软件系统,5个被广泛使用的Rust库,以及两个漏洞数据库。调查总共涉及了850处unsafe代码使用、70个内存安全缺陷、100个线程安全缺陷。

在调查中,研究员不光查看了所有漏洞数据库中报告的缺陷和软件公开报告的缺陷,还查看了所有开源软件代码仓库中的提交记录。通过人工的分析,他们界定出提交所修复的BUG类型,并将其归类到相应的内存安全/线程安全问题中。所有被调查过的问题都被整理到了公开的Git仓库中:https://github.com/system-pclub/rust-study
内存安全问题的分析
这项研究调查了70个内存安全问题。针对于每个问题,研究者仔细的分析了问题出现的根因(cause)和问题导致的效果(effect)。问题根因是通过修改问题时提交的patch代码来界定的——即编码的错误发生在哪儿;问题的效果是指代码运行造成可观察的错误的位置,比如出现缓冲区溢出的代码位置。由于从根因到效果有个传递过程,这两者有时候是相隔很远的。根据根因和效果所在的代码区域不同,研究者将错误分为了4类:safe -> safe、safe -> unsafe、unsafe -> safe、unsafe -> unsafe。比如:如果编码错误出现在safe代码中,但造成的效果体现在unsafe代码中,那么就归类为safe -> unsafe。
另一方面,按照传统的内存问题分类,问题又可以分为空间内存安全(Wrong Access)和时间内存安全(Lifetime Violation)两大类,进一步可细分为缓冲区溢出(Buffer overflow)、解引用空指针(Null pointer dereferencing)、访问未初始化内存(Reading uninitialized memory)、错误释放(Invalid free)、释放后使用(Use after free)、重复释放(Double free)等几个小类。根据这两种分类维度,问题的统计数据如下:

从统计结果中可以看出,完全不涉及unsafe代码的内存安全问题只有一个。进一步调查发现这个问题出现在Rust早期的v0.3版本中,之后的稳定版本编译器已经能拦截这个问题。因此可以说:Rust语言的safe代码机制能非常有效的避免内存安全问题,所有稳定版本中发现的内存安全问题都和unsafe代码有关。
然而,这并不意味着我们只要检查所有unsafe代码段就能有效发现问题。因为有时候问题根因会出现在safe代码中,只是效果产生在unsafe代码段。论文中举了一个例子:(hi3ms没有Rust代码编辑功能,只能拿其他语言凑合下了)
Css 代码
pub fn sign(data: Option<&[u8]>) { let p = match data { Some(data) => BioSlice::new(data).as_ptr(), None => ptr::null_mut(), }; unsafe { let cms = cvt_p(CMS_sign(p)); } }
在这段代码中,p是raw pointer类型,在safe代码中,当data含有值(Some分支)时,分支里试图创建一个BioSlice对象,并将对象指针赋给p。然而,根据Rust的生命周期规则,新创建的BioSlice对象在match表达式结束时就被释放了,p在传给CMS_sign函数时是一个野指针。这个例子中的unsafe代码段没有任何问题,如果只检视unsafe代码,不可能发现这个释放后使用的错误。对此问题修改后的代码如下:
Css 代码
pub fn sign(data: Option<&[u8]>) { let bio = match data { Some(data) => Some(BioSlice::new(data)), None => None, }; let p = bio.map_or(ptr::null_mut(),|p| p.as_ptr()); unsafe { let cms = cvt_p(CMS_sign(p)); } }
修改后的代码正确的延长了bio的生命周期。所有的修改都只发生在safe代码段,没有改动unsafe代码。
既然问题都会涉及unsafe代码,那么把unsafe代码消除掉是否可以避免问题?研究者进一步的调查了所有BUG修改的策略,发现大部分的修改涉及了unsafe代码,但是只有很少的一部分修改完全移除了unsafe代码。这说明unsafe代码是不可能完全避免的。
unsafe的价值是什么?为什么不可能完全去除?研究者对600处unsafe的使用目的进行了调查,发现其中42%是为了复用已有代码(比如从现有C代码转换成的Rust代码,或者调用C库函数),22%是为了改进性能,剩下的14%是为了实现功能而绕过Rust编译器的各种校验。
进一步的研究表明,使用unsafe的方法来访问偏移的内存(如slice::get_unchecked()),和使用safe的下标方式访问相比,unsafe的速度可以快4~5倍。这是因为Rust对缓冲区越界的运行时校验所带来的,因此在某些性能关键区域,unsafe的作用不可缺少。
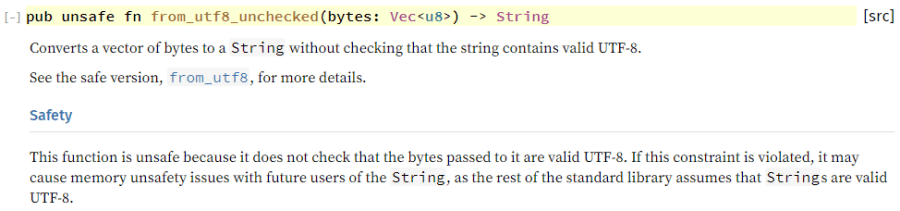
需要注意的是,unsafe代码段并不见得包含unsafe的操作。研究者发现有5处unsafe代码,即使去掉unsafe标签也不会有任何编译错误——也就是说,从编译器角度它完全可以作为safe代码。将其标为unsafe代码是为了给使用者提示关键的调用契约,这些契约不可能被编译器检查。一个典型的例子是Rust标准库中的String::from_utf8_unchecked()函数,这个函数内部并没有任何unsafe操作,但是却被标为了unsafe。其原因是这个函数直接从用户提供的一片内存来构造String对象,但并没有对内容是否为合法的UTF-8编码进行检查,而Rust要求所有的String对象都必须是合法的UTF-8编码字符串。也就是说,String::from_utf8_unchecked()函数的unsafe标签只是用来传递逻辑上的调用契约,这种契约和内存安全没有直接关系,但是如果违反契约,却可能导致其他地方(有可能是safe代码)的内存安全问题。这种unsafe标签是不能去除的。
即便如此,在可能的情况下,消除unsafe代码段确实是个有效的安全改进方法。研究者调查了130个去掉unsafe的修改记录,发现其中43个通过代码的重构把unsafe代码段彻底改为了safe代码,剩下的87个则通过将unsafe代码封装出safe的接口来保证了安全性。
线程安全问题的分析
这项研究调查了100个线程安全问题。问题被分为了两类:阻塞式问题(造成死锁)和非阻塞式问题(造成数据竞争),其中阻塞式问题有59个,之中55个都和同步原语(Mutex和Condvar)有关:

虽然Rust号称可以进行“无畏并发”的编程,并且提供了精心设计的同步原语以避免并发问题。然而,仅仅用safe代码就可能导致重复加锁造成的死锁,更糟糕的是,有些问题甚至是Rust的特有设计所带来的,在其他语言中反而不会出现。论文中给出了一个例子:
Css 代码
fn do_request() { //client: Arc<RwLock<Inner>> match connect(client.read().unwrap().m) { Ok(_) => { let mut inner = client.write().unwrap(); inner.m = mbrs; } Err(_) => {} }; }
这段代码中,client变量被一个读写锁(RwLock)保护。RwLock的方法read()和write()会自动对变量加锁,并返回LockResult对象,在LockResult对象生命周期结束时,自动解锁。
显然,该段代码的作者以为client.read()返回的临时LockResult对象在match内部的匹配分支之前就被释放并解锁了,因此在match分支中可以再次用client.write()对其加锁。但是,Rust语言的生命周期规则使得client.read()返回的对象的实际生命周期被延长到了match语句结束,所以该段代码实际结果是在read()的锁还没有释放时又尝试获取write()锁,导致死锁。
这种临时对象生命周期规则在Rust语言中是一个非常晦涩的规则,对其的详细解释可以参见这篇文章。
根据生命周期的正确用法,该段代码后来被修改成了这样:
Css 代码
fn do_request() { //client: Arc<RwLock<Inner>> let result = connect(client.read().unwrap().m); match result { Ok(_) => { let mut inner = client.write().unwrap(); inner.m = mbrs; } Err(_) => {} }; }
修改以后,client.read()返回的临时对象在该行语句结束后即被释放,不会一直加锁到match语句内部。
对于41个非阻塞式问题,其中38个都是因为对共享资源的保护不当而导致的。根据对共享资源的不同保护方法,以及代码是否为safe,这些问题进一步被分类如下:

38个问题中,有23个发生在unsafe代码,15个发生在safe代码。尽管Rust设置了严格的数据借用和访问规则,但由于并发编程依赖于程序的逻辑和语义,即使是safe代码也不可能完全避免数据竞争问题。论文中给出了一个例子:
Css 代码
impl Engine for AuthorityRound { fn generate_seal(&self) -> Seal { if self.proposed.load() { return Seal::None; } self.proposed.store(true); return Seal::Regular(...); } }
这段代码中,AuthorityRound结构的proposed成员是一个boolean类型的原子变量,load()会读取变量的值,store()会设置变量的值。显然,这段代码希望在并发操作时,只返回一次Seal::Regular(…),之后都返回Seal::None。但是,这里对原子变量的操作方法没有正确的处理。如果有两个线程同时执行到if语句,并同时读取到false结果,该方法可能给两个线程都返回Seal::Regular(…)。
对该问题进行修改后的代码如下,这里使用了compare_and_swap()方法,保证了对原子变量的读和写在一个不可抢占的原子操作中一起完成。
Css 代码
impl Engine for AuthorityRound { fn generate_seal(&self) -> Seal { if !self.proposed.compare_and_swap(false, true) { return Seal::Regular(...); } return Seal::None; } }
这种数据竞争问题没有涉及任何unsafe代码,所有操作都在safe代码中完成。这也说明了即使Rust语言设置了严格的并发检查规则,程序员仍然要在编码中人工保证并发访问的正确性
对Rust缺陷检查工具的建议
显然,从前面的调查可知,光凭Rust编译器本身的检查并不足以避免所有的问题,甚至某些晦涩的生命周期还可能触发新的问题。研究者们建议对Rust语言增加以下的检查工具:
1. 改进IDE。当程序员选中某个变量时,自动显示其生命周期范围,尤其是对于lock()方法返回的对象的生命周期。这可以有效的解决因为对生命周期理解不当而产生的编码问题。
2. 对内存安全进行静态检查。研究者们实现了一个静态扫描工具,对于释放后使用的内存安全问题进行检查。在对参与研究的Rust项目进行扫描后,工具新发现了4个之前没有被发现的内存安全问题。说明这种静态检查工具是有必要的。
3. 对重复加锁问题进行静态检查。研究者们实现了一个静态扫描工具,通过分析lock()方法返回的变量生命周期内是否再次加锁,来检测重复加锁问题。在对参与研究的Rust项目进行扫描后,工具新发现了6个之前没有被发现的死锁问题。
论文还对动态检测、fuzzing测试等方法的应用提出了建议。
结论
1. Rust语言的safe代码对于空间和时间内存安全问题的检查非常有效,所有稳定版本中出现的内存安全问题都和unsafe代码有关。
2. 虽然内存安全问题都和unsafe代码有关,但大量的问题同时也和safe代码有关。有些问题甚至源于safe代码的编码错误,而不是unsafe代码。
3. 线程安全问题,无论阻塞还是非阻塞,都可以在safe代码中发生,即使代码完全符合Rust语言的规则。
4. 大量问题的产生是由于编码人员没有正确理解Rust语言的生命周期规则导致的。
5. 有必要针对Rust语言中的典型问题,建立新的缺陷检测工具。