6种常见的地标识别算法整理和总结
摘要:地标识别,基于深度学习及大规模图像训练,支持上千种物体识别及场景识别,广泛应用于拍照识图、幼教科普、图片分类等场景。本文将为大家带来6种关于地标识的算法整理和总结。
地标识别,基于深度学习及大规模图像训练,支持上千种物体识别及场景识别,广泛应用于拍照识图、幼教科普、图片分类等场景。本文将为大家带来6种关于地标识的算法。
一、《1st Place Solution to Google Landmark Retrieval 2020》
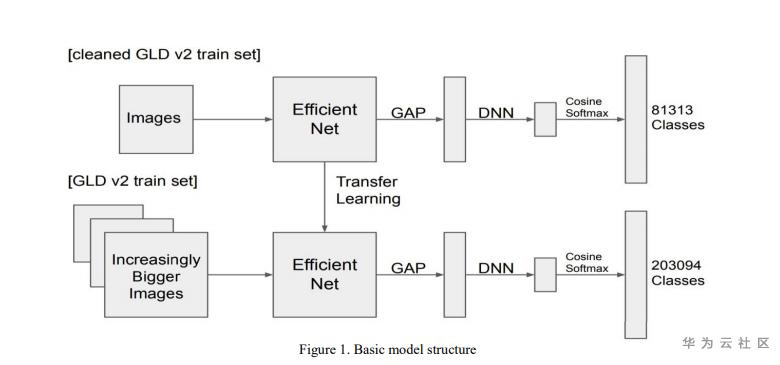
算法思路:
Step1:使用清洗过的GLDv2数据集训练初始embedding模型。
Step2:使用全量GLDv2数据基于Step1得到的模型进行迁移学习。
Step3:逐步扩大训练图片的尺度(512*512,640*640,736*736),模型性能得到进一步提升。
Step4:增加清洗后的数据的训练loss权重,进一步训练模型。
Step5:模型融合。
Notes:
1、Backbone模型为Efficientnet+global average pooling,训练使用了cosine softmax loss。
2、为了处理类别不均衡问题,使用了weighted cross entropy。
经验总结:
1、清洗后的数据有利于模型快速收敛。
2、全量大数据集有利于模型学习到更好的特征表示。
3、增加训练分辨率能提升模型性能。



二、《3rd Place Solution to “Google Landmark Retrieval 2020》
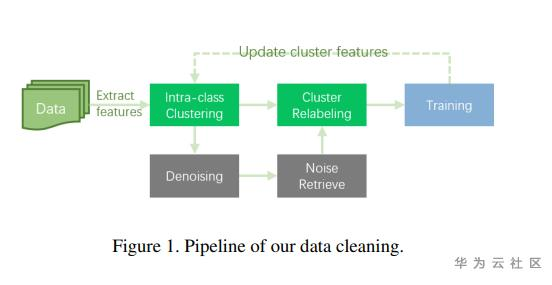

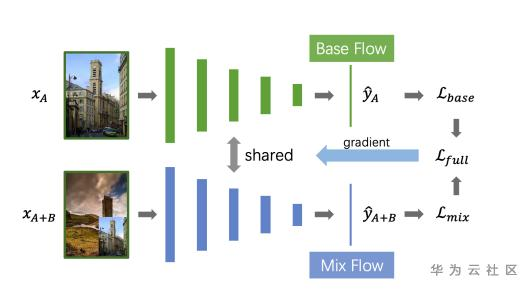
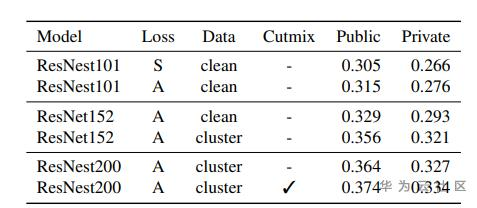
算法思路:
Step1:使用CGLDv2训练基础模型用于提取GLDv2全量图片特征,使用DBSCAN聚类方法更新图像类别,进行数据清洗。
Step2:使用了Corner-Cutmix的图像增广方法,进行模型训练。
Notes:
1、backbone为ResNest200和ResNet152,GAP池化,1*1卷积降维到512维,损失函数为cross entropy loss。
三、《Two-stage Discriminative Re-ranking for Large-scale Landmark Retrieval》
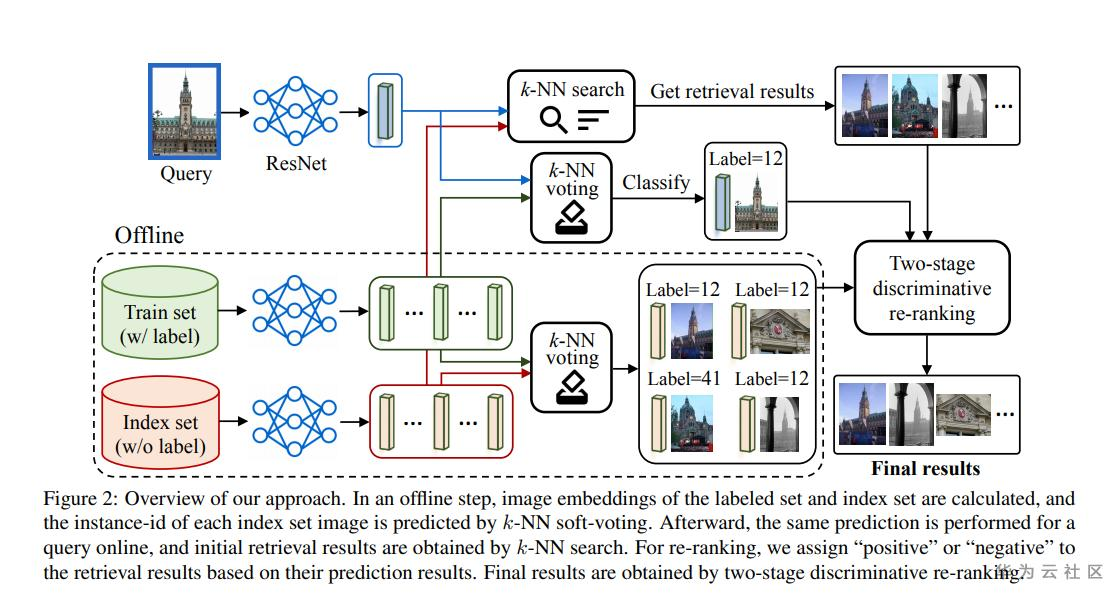
算法思路:
Step1:使用CNN特征进行KNN搜索,获取相似图片。
Step2:插入Step1遗漏的图片进行重新排序。
Notes:
1、Backbone模型为ResNet-101+Generalized Mean (GeM)-pooling,训练loss为ArcFace loss。
2、使用全局特征+局部特征对GLd-v2数据集进行清洗,用于后续模型训练。
四、《2nd Place and 2nd Place Solution to Kaggle Landmark Recognition and Retrieval Competition 2019》
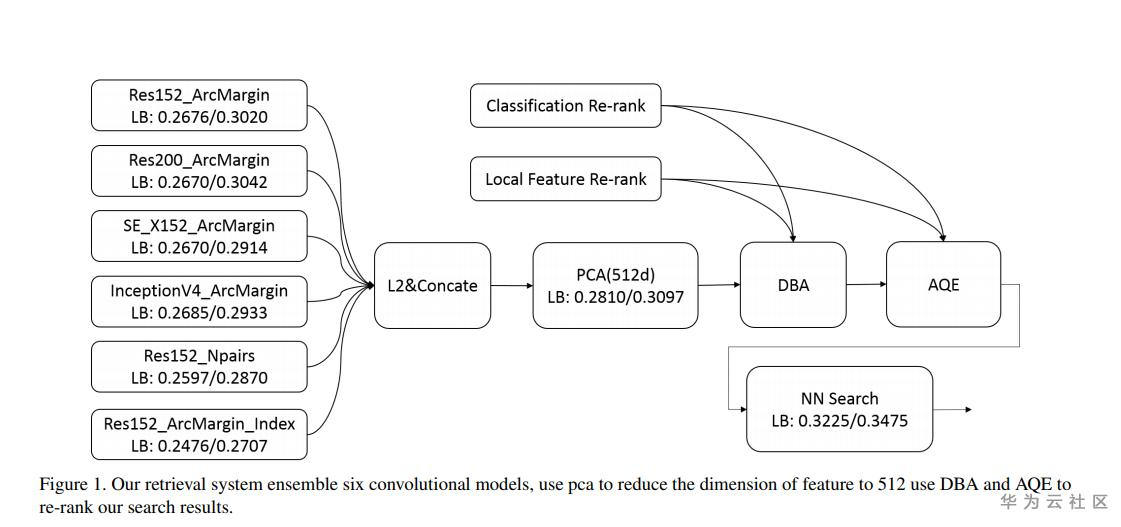
算法思路:
1、使用GLD-v2全量数据分别训练Resnet152、ResNet200等模型,训练loss为ArcFace loss、Npairs loss,拼接各个backbone的特征,使用PCA降到512维,作为图像的全局特征。
2、使用全局特征进行KNN搜索,对搜索结果使用SURF、Hassian-Affine 和root sift局部特征进行再排序,并且使用了DBA和AQE。
五、《Detect-to-Retrieve: Efficient Regional Aggregation for Image Search》
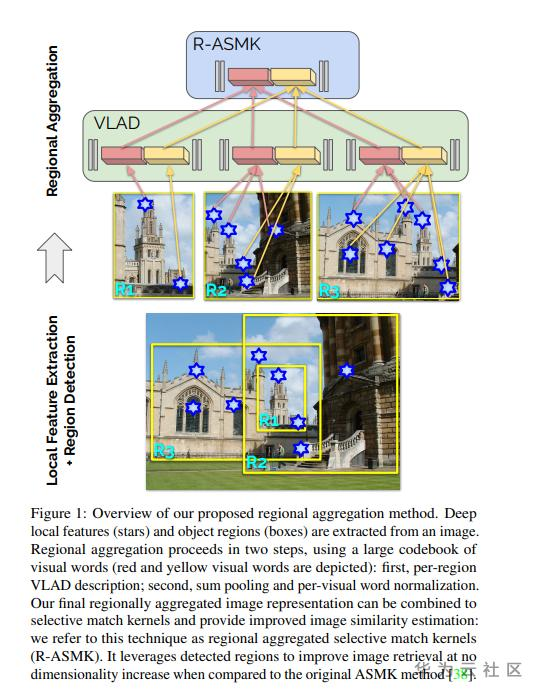
算法思路:
Step1:使用GLD的带bbox数据集,训练Faster-RCNN或SSD检测模型,用于地标框的提取。
Step2:提出了D2R-R-ASMK方法,用于检测框内的局部特征提取与特征聚合。
Step3:使用聚合后特征在database中进行搜索。
Notes:
1、D2R-R-ASMK基于DELF局部特征抽取和ASMK特征聚合方法实现。
2、每张图片提取4.05个region的时候效果最好,search的内存占用会有相应增加。
六、《Unifying Deep Local and Global Features for Image Search》
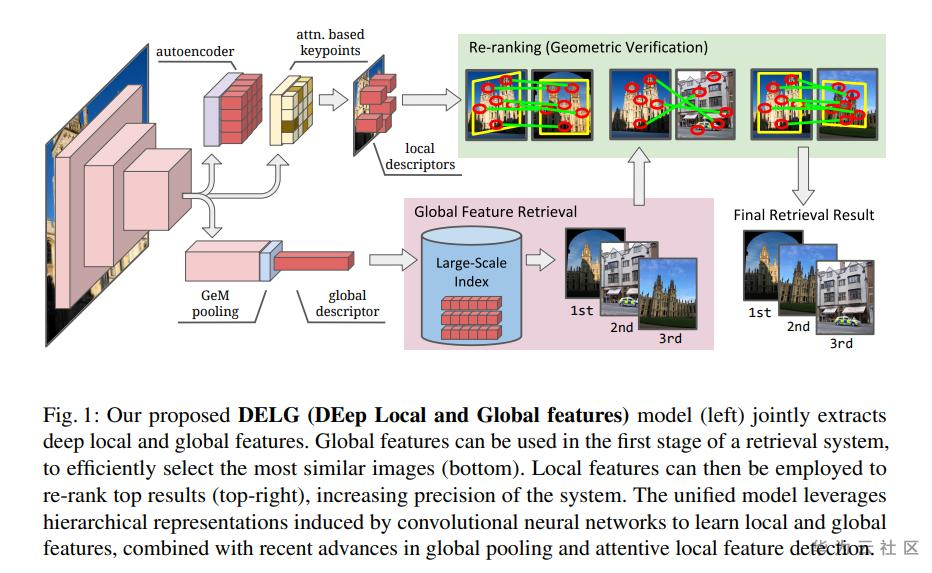
算法思路:
Step1:统一在同一个网络中提取全局和局部特征
Step2:使用全局特征搜索top100的相似图片
Step3:使用局部特征对搜索结果进行重排序
Notes:
1、全局特征使用GeM池化和ArcFace loss。
2、局部特征匹配使用Ransac方法。
本文分享自华为云社区《地标识别算法》,原文作者:阿杜 。