手把手教你在Modelarts平台上进行视频推理
摘要:为了方便小伙伴们进行视频场景的AI应用开发,Modelarts推理平台将视频推理场景中一些通用的流程抽取出来预置在基础镜像中,小伙伴们只需要简单地编写预处理及后处理脚本,便可以像开发图片类型的AI服务一样开发视频类型的AI服务了。
本文分享自华为云社区《在Modelarts平台上进行视频推理》,原文作者:HW007。
熟悉Modelarts推理的小伙伴都知道,在Modelarts平台上可以通过简单地定制模型的预处理、推理及后处理脚本,就可以轻松的部署一个AI服务,对图片、文本、音视频等输入进行推理。但是对于视频类型的推理,之前需要用户在自己的脚本中进行视频文件下载、视频解码、并自己将处理后的文件传到OBS中。为了方便小伙伴们进行视频场景的AI应用开发,Modelarts推理平台将视频推理场景中一些通用的流程抽取出来预置在基础镜像中,小伙伴们只需要简单地编写预处理及后处理脚本,便可以像开发图片类型的AI服务一样开发视频类型的AI服务了。
一、总体设计说明
提取视频场景的通用推理流程如下:
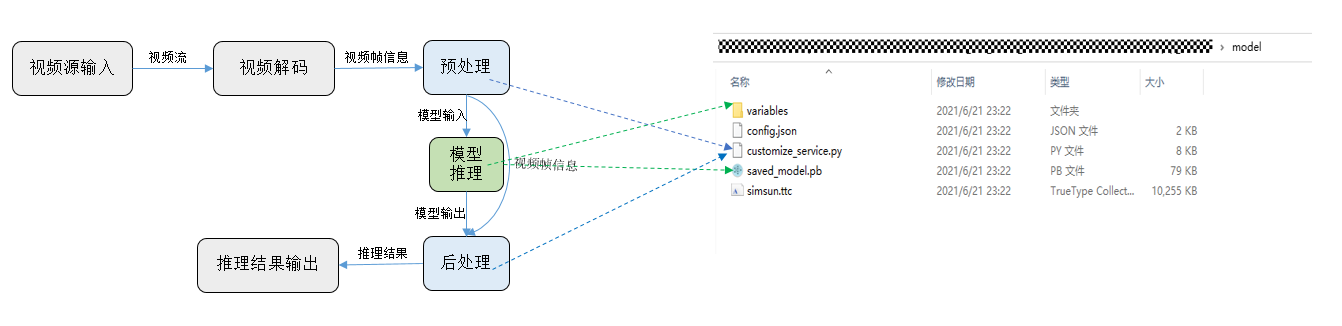
如上图,视频处理场景的流程可分为“视频源输入”、“视频解码”、“预处理”、“模型推理”、“后处理”、“推理结果输出”六个部分。其中“视频源输入”、“视频解码”、“推理结果输出”三个灰色的部分Modelarts已经提前准备好。“预处理”、“模型推理”、“后处理”三个部分可由用户自由定制,具体定制方法如下:
1)定制模型:Modelarts已经提供好模型加载的方法,用户只需要将自己“saved_model”格式的模型放置到指定的model目录即可。
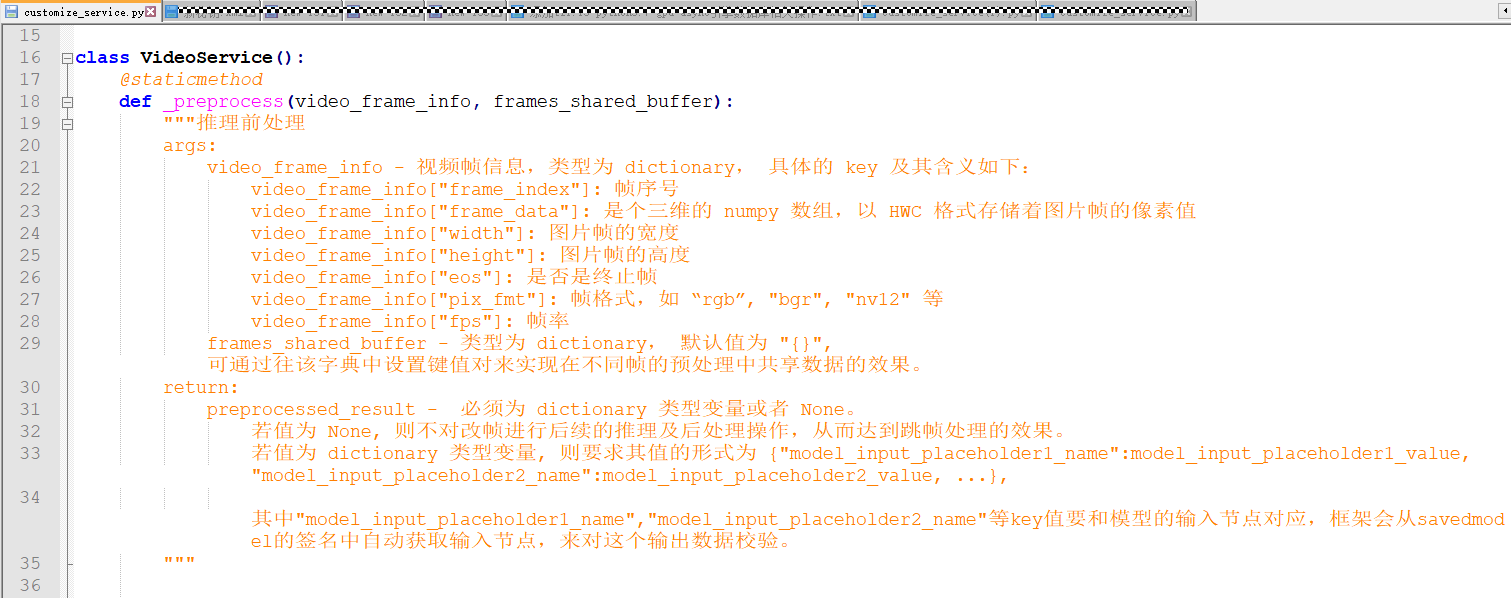
2)定制预处理:Modelarts会将解码后的视频帧数据提供给用户,用户只需通过重写“customize_service.py”中“VideoService”类的静态方法“_preprocess”便好,“_preprocess”函数的入参以及对出参的约束如下:
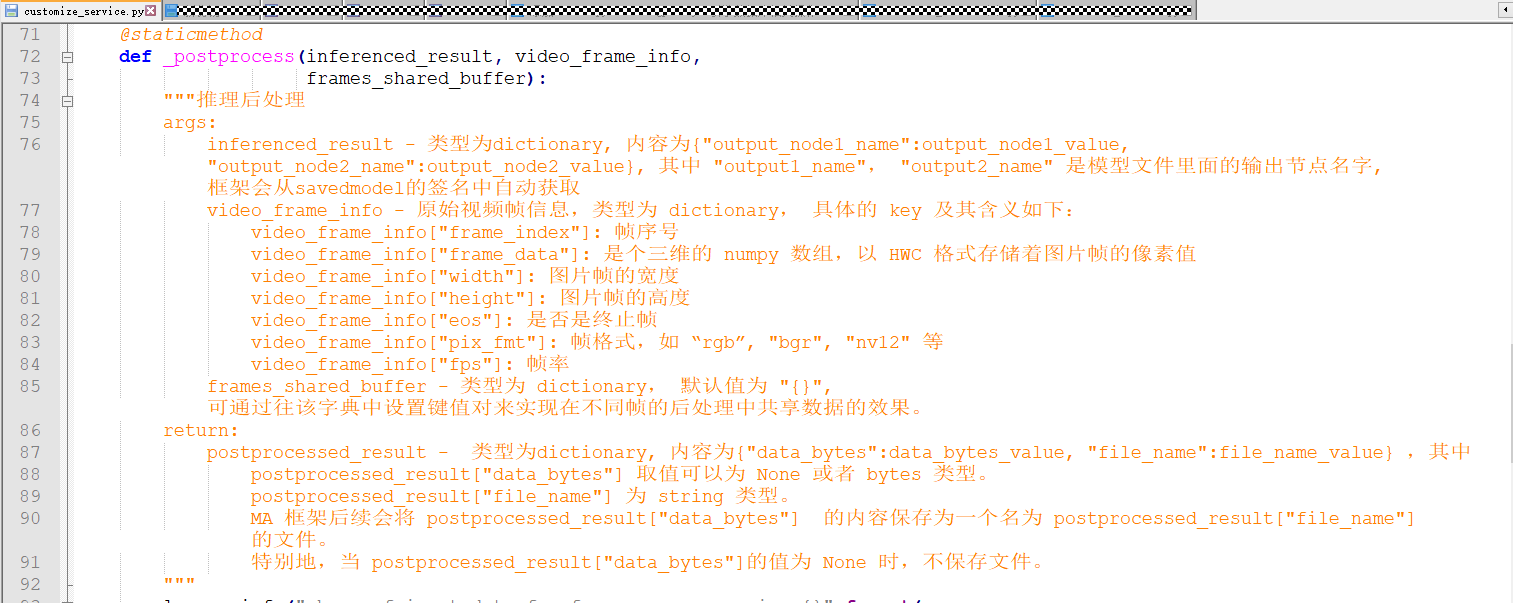
3)定制后处理:Modelarts会将模型推理后的输出及解码后的视频帧数据提供给用户,用户只需通过重写“customize_service.py”中“VideoService”类的静态方法“_postprocess”便好,“_postprocess”函数的入参以及对出参的约束如下:
二、Demo体验
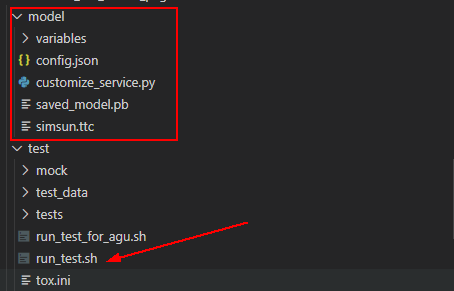
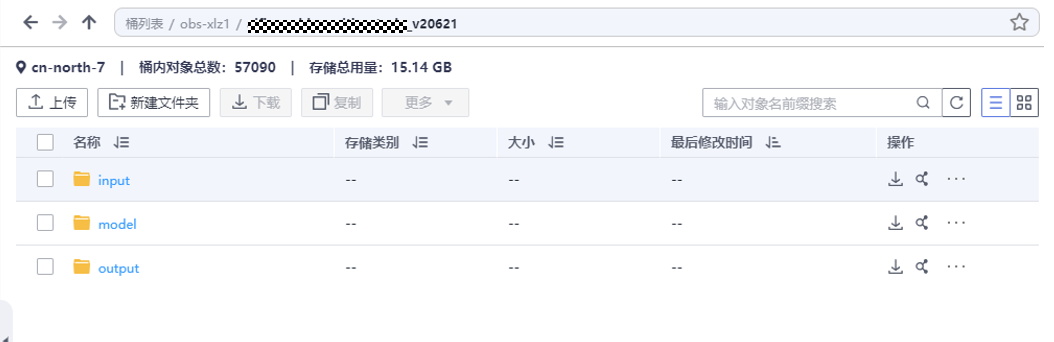
1)下载本文附件,如下图,附件提供了一个已调试OK的视频推理模型包“model”文件夹,同时也提供了基于tox框架写好的验证用例,供用户线下调试自己模型包是否OK。
2)将附件包中的“model”文件夹传到华为云OBS中。
将附件包中的“test/test_data/input”、“test/test_data/output”文件夹放到华为云OBS与之前“model”文件夹放置同级的目录下。
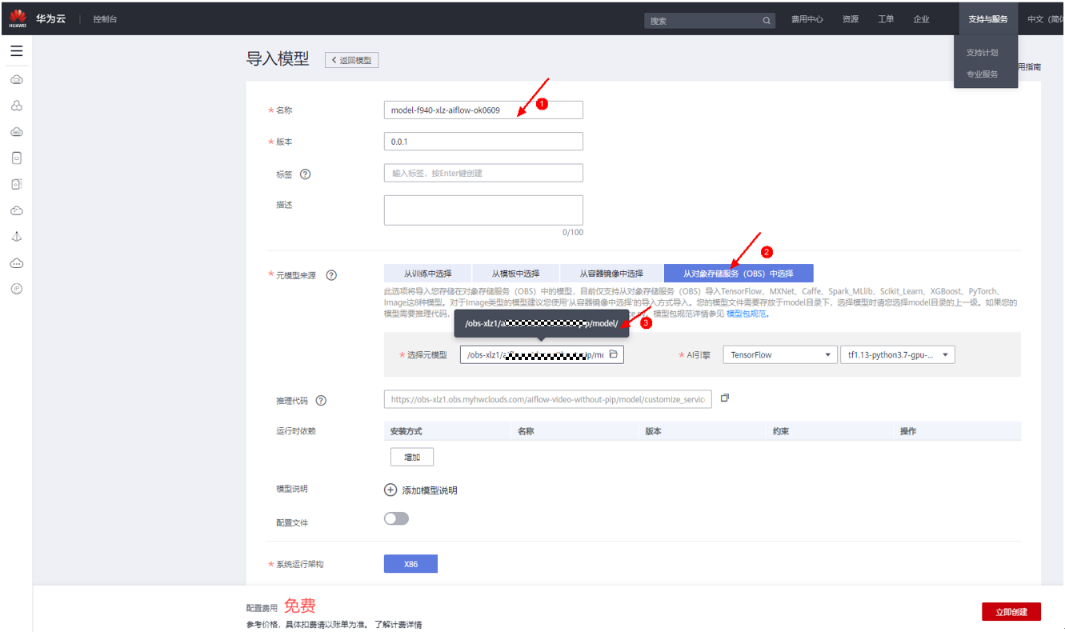
3)导入模型:在Modelarts导入模型界面,选择从OBS导入,选择刚才传到OBS中的model目录。如下图所示:
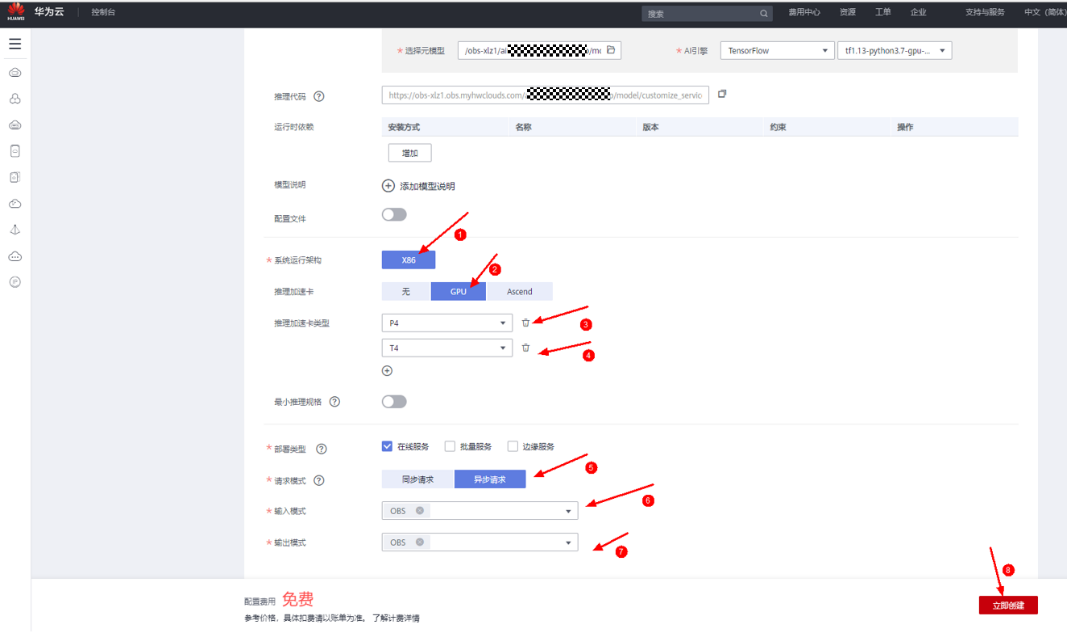
按下面操作配置好模型的各个配置后点击创建模型:
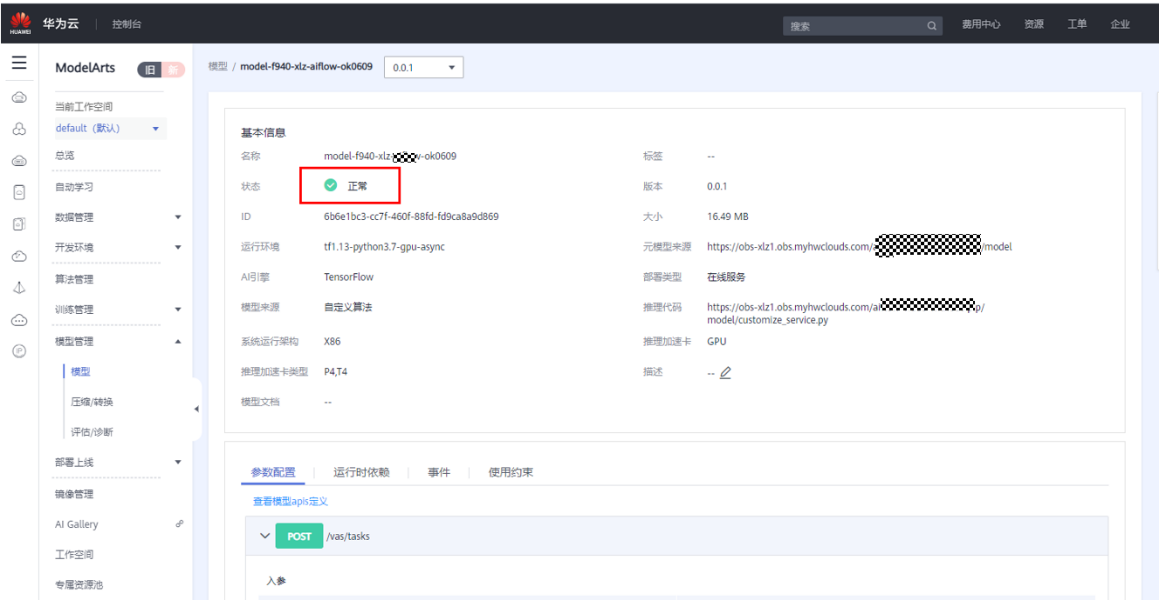
可以看到模型创建成功:
4).部署服务,将上述模型部署为在线服务,部署中要选择有GPU的资源节点(公共池和专属池都可以):
可以看到服务已经部署成功:
5)创建作业:在服务界面选择创建作业
选择输入视频,选到步骤2)中上传到OBS中的input文件夹中的视频文件如下:
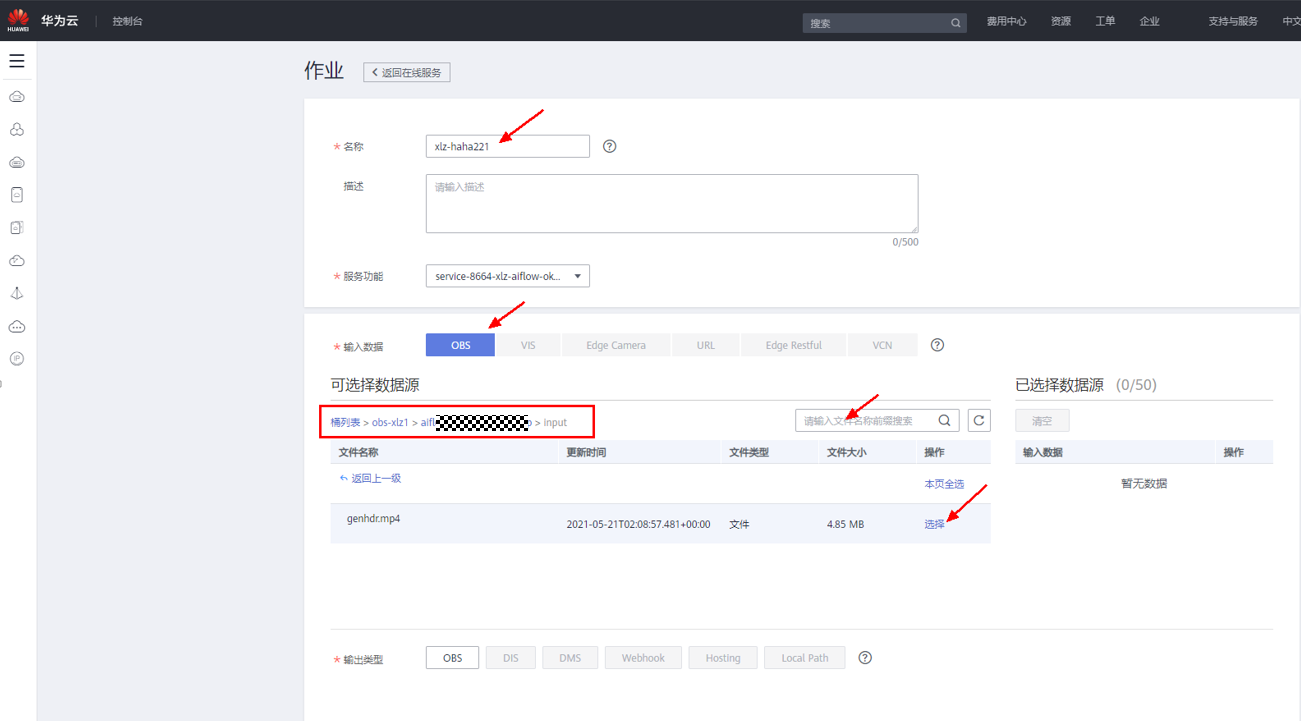
选择输出路径,选到步骤2)中上传到OBS中的output文件夹如下:
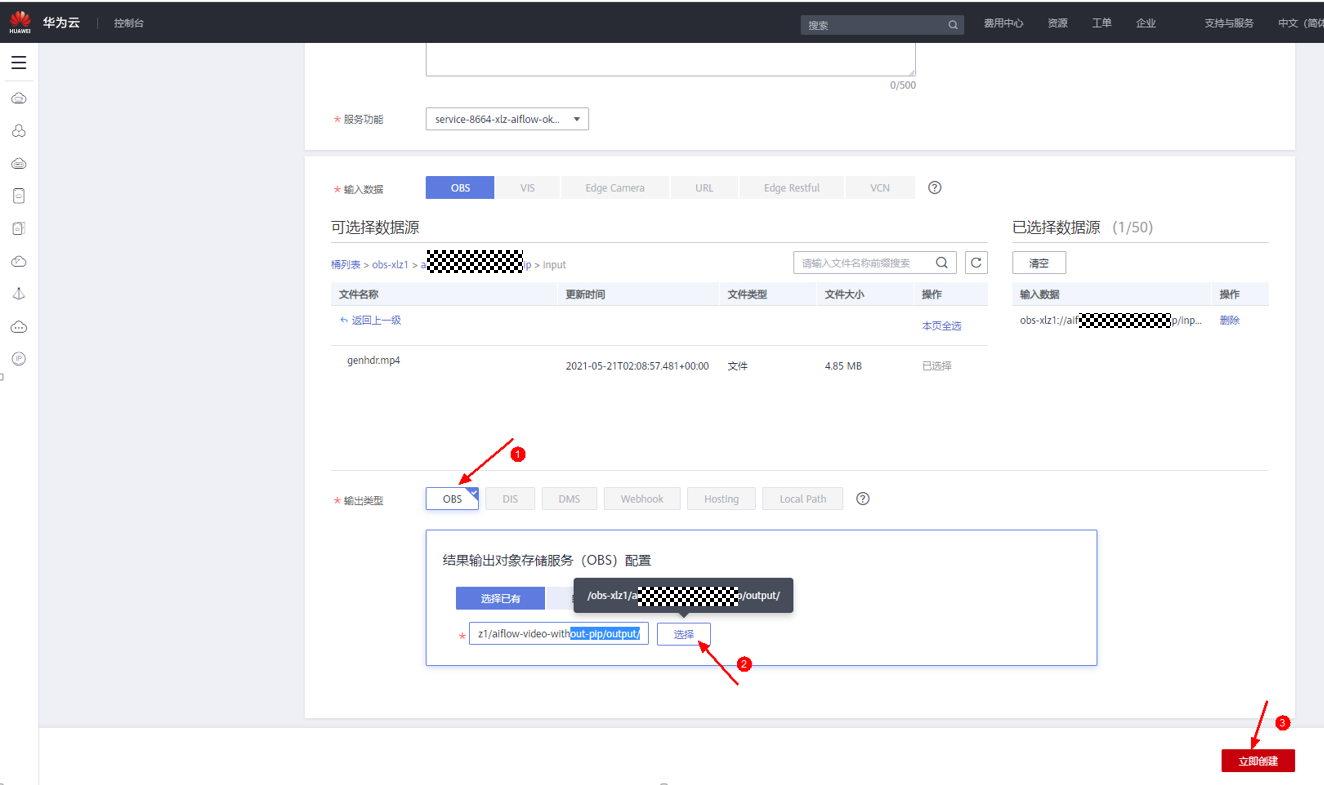
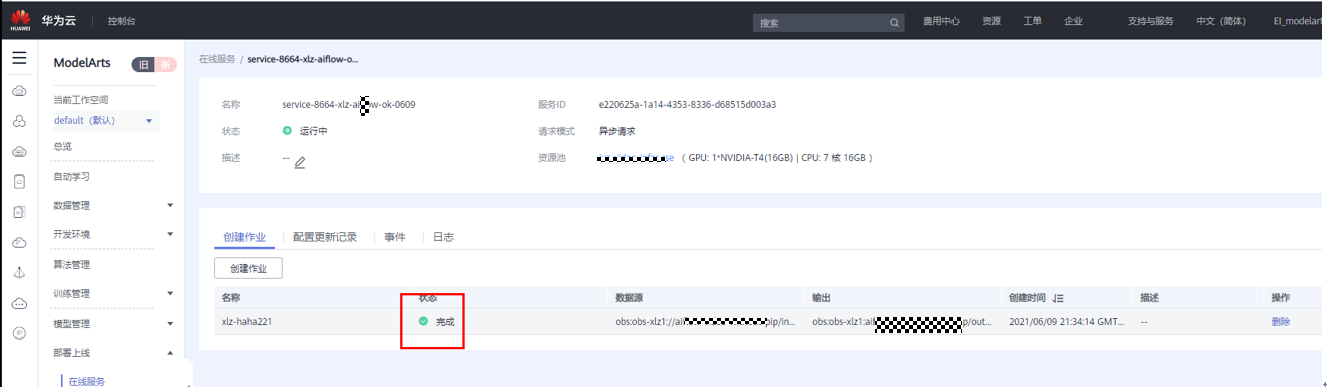
6)等待视频处理完成:
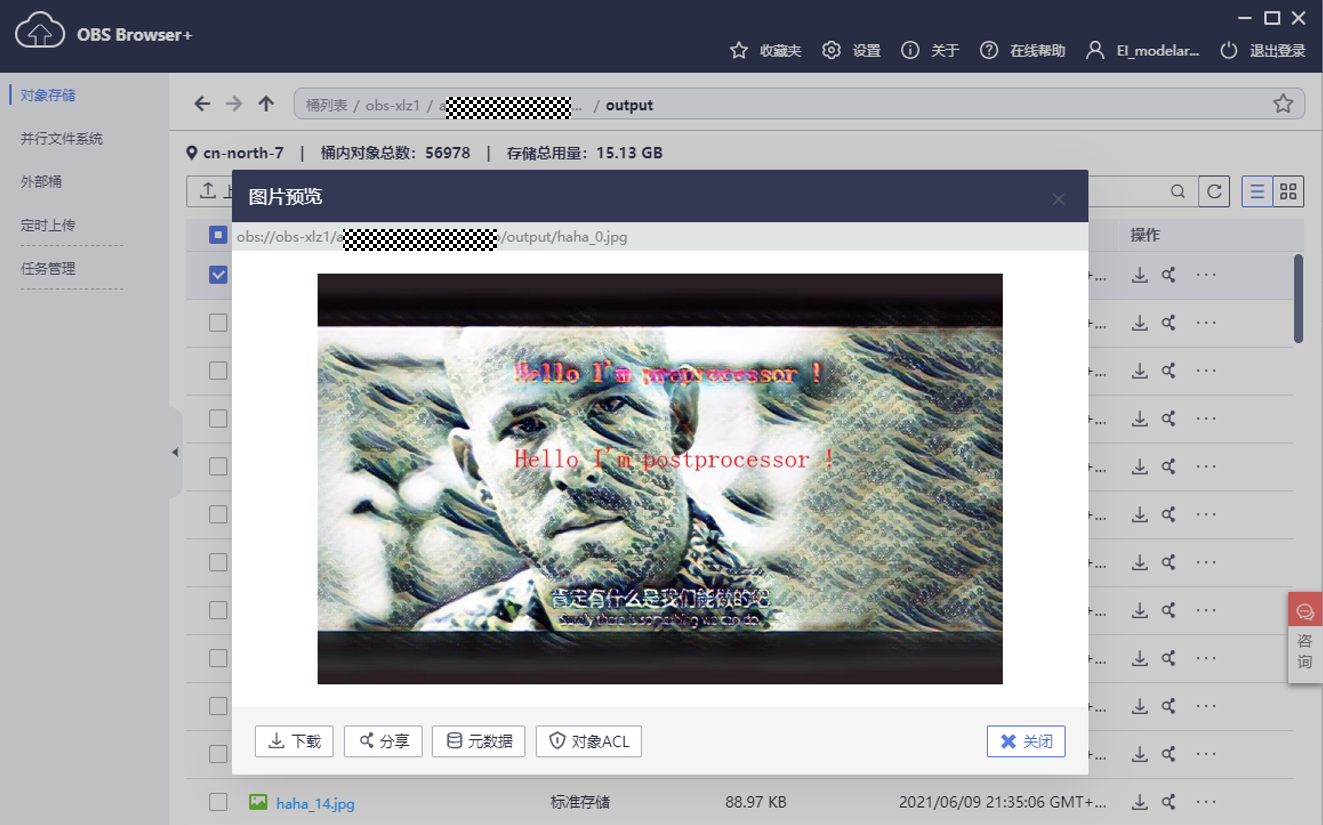
查看OBS中的output文件夹,可看到视频已被拆成图片后的推理结果了。
7)用户根据自己需要,更换model文件夹下的“saved_model”格式的模型文件,并修改“customize_service.py”中的“_preprocess”和“_postprocess”函数来完成自己的业务逻辑。修改完后可以先运行“test/run_test.sh”来提前验证下修改后的模型包是否能正常推理,待线下调试好,可正常推理后再按上述步骤将模型包提交到OBS中部署成Modelarts服务。
其中,视频推理的模型包要求如下:
模型包结构要求:
└── model
├── config.json (必须,Modelarts推理相关的配置文件)
├── customize_service.py (必须,推理文件)
├── saved_model.pb (必须,SavedModel格式的模型文件)
└── variables (必须,SavedModel格式的模型文件)
├── variables.data-00000-of-00001
└── variables.index
其中config.json 文件的格式遵循Modelarts的规范,https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0092.html
目前,只有tensorflow的“tf1.13-python3.7-gpu-async”runtime支持视频推理,即config.json文件中的”model_type”字段必须为”TensorFlow”, “runtime”字段必须为 “tf1.13-python3.7-gpu-async”。
“customize_service.py”文中必须有一个“VideoService”类,“VideoService”类必须有两个静态方法“_preprocess”和“_postprocess”,相应的函数签名约束如下: