BeautifulSoup的基本用法

前言
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
它是一个灵活又方便的网页解析库,处理高效,支持多种解析器。
利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
通常人们把 beautifulSoup 叫作“美味的汤,绿色的浓汤”,简称:美丽(味)汤
它的官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html (中)
https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (英)
安装
快速安装
pip install beautifulsoup4 或 easy_install BeautifulSoup4
解析库
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
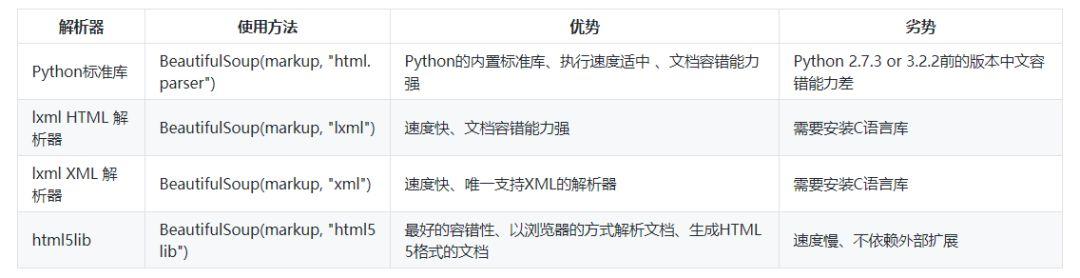
基本使用
from bs4 import BeautifulSoup html = """ <html><head><title>haha,The Dormouse\'s story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse\'s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html,\'lxml\') # print(soup.prettify()) # 格式化 print(soup.title) print(soup.title.name) print(soup.title.string) print(soup.title.parent.name) print(soup.p) # p标签 print(soup.p["class"]) print(soup.a) print(soup.find_all(\'a\')) print(soup.find(id=\'link3\')) <title>haha,The Dormouse\'s story</title>title haha,The Dormouse\'s story head <p class="title" name="dromouse"><b>The Dormouse\'s story</b></p> [\'title\'] <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a> [<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
View Code
标签选择器获取内容
html = """ <html><head><title>The Dormouse\'s story</title></head> <body> <p clss="title" name="dromouse"><b>The Dormouse\'s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.p.string) The Dormouse\'s story
View Code
嵌套内容
html = """ <html><head><title>The Dormouse\'s story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse\'s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.head.title.string) The Dormouse\'s story
View Code
子节点与子孙节点
html = """ <html> <head> <title>The Dormouse\'s story</title> </head> <body> <p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.p.contents) 略 from bs4 import BeautifulSoup string = \'\'\'<p class="title" name="dromouse"><b>The Dormouse\'s story</b></p>\'\'\' soup = BeautifulSoup(string, \'lxml\') print(soup.p.contents) [<b>The Dormouse\'s story</b>]
View Code
父节点和祖先节点
html = """ <html> <head> <title>The Dormouse\'s story</title> </head> <body> <p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.a.parent) 略 html = """ <html> <head> <title>The Dormouse\'s story</title> </head> <body> <p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(list(enumerate(soup.a.parents))) # 所有父节点 略
View Code
兄弟节点
html = """ <html> <head> <title>The Dormouse\'s story</title> </head> <body> <p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(list(enumerate(soup.a.next_siblings))) print(list(enumerate(soup.a.previous_siblings))) 略
View Code
标准选择器
可根据标签名、属性、内容查找文档
find_all( name , attrs , recursive , text , **kwargs )
name
html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.find_all(\'ul\')) print(type(soup.find_all(\'ul\')[0])) [<ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li></ul>, <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li></ul>] <class \'bs4.element.Tag\'> html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') for ul in soup.find_all(\'ul\'): print(ul.find_all(\'li\')) [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]
View Code
attrs
html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.find_all(attrs={\'id\': \'list-1\'})) print(soup.find_all(attrs={\'name\': \'elements\'})) [<ul class="list" id="list-1" name="elements"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul>] [<ul class="list" id="list-1" name="elements"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul>] html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.find_all(id=\'list-1\')) print(soup.find_all(class_=\'element\')) [<ul class="list" id="list-1"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul>] [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
View Code
text
html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.find_all(text=\'Foo\')) [\'Foo\', \'Foo\']
View Code
find_parents() find_parent()
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings() find_next_sibling()
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。
find_previous_siblings() find_previous_sibling()
find_previous_siblings()返回前面所有兄弟节点, find_previous_sibling()返回前面第一个兄弟节点。
find_all_next() find_next()
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点
find_all_previous() 和 find_previous()
find_all_previous()返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点
CSS选择器
使用十分的简单,通过select()直接传入CSS选择器即可完成选择
html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') print(soup.select(\'.panel .panel-heading\')) print(soup.select(\'ul li\')) print(soup.select(\'#list-2 .element\')) print(type(soup.select(\'ul\')[0])) [<div class="panel-heading"><h4>Hello</h4></div>] [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]<class \'bs4.element.Tag\'> html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') for ul in soup.select(\'ul\'): print(ul.select(\'li\')) [<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]
View Code
获取属性
html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') for ul in soup.select(\'ul\'): print(ul[\'id\']) print(ul.attrs[\'id\']) list-1 list-1 list-2 list-2 # 可以看出两种方式获取属性的效果一样
View Code
获取内容
html=\'\'\' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> \'\'\' from bs4 import BeautifulSoup soup = BeautifulSoup(html, \'lxml\') for li in soup.select(\'li\'): print(li.get_text()) Foo Bar Jay Foo Bar
View Code
总结
-
推荐使用lxml解析库,必要时使用html.parser
-
标签选择筛选功能弱但是速度快建议使用find()、find_all()
-
查询匹配单个结果或者多个结果如果对CSS选择器熟悉建议使用select()
-
记住常用的获取属性和文本值的方法
荐读:
版权声明:本文为lisen10原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。