技术揭秘:华为云DLI背后的核心计算引擎
摘要:介绍隐藏在华为云数据湖探索服务背后的核心计算引擎Spark,玩转DLI,,轻松完成大数据的分析处理。
本文主要给大家介绍隐藏在华为云数据湖探索服务(后文简称DLI)背后的核心计算引擎——Spark。
DLI团队在Spark之上做了大量的性能优化与服务化改造,但其本质还是脱离不了Spark的核心概念与思想,因此笔者从以下几点阐述,让读者快速对Spark有一个直观的认识,玩转DLI。
Spark的诞生及优势
2009年,Spark诞生于伯克利大学AMPLab,诞生之初是属于伯克利大学的研究性项目。于2010年开源,2013年成为Apache开源项目,经过几年的发展逐渐取代了Hadoop,成为了开源社区炙手可热的大数据处理平台。
Spark官方的解释:“Spark是用于大规模数据处理的统一分析引擎”,把关键词拆开来看,“大规模数据”指的是Spark的使用场景是大数据场景;“统一”主要体现在将大数据的编程模型进行了归一化,同时满足多种类型的大数据处理场景(批处理、流处理、机器学习等),降低学习和维护不同大数据引擎的成本;“分析引擎”表明Spark聚焦在计算分析,对标的是Hadoop中的MapReduce,对其模型进行优化与扩展。
Spark为了解决MapReduce模型的优化和扩展,那么我们先探讨一下MapReduce存在的问题,然后分析Spark在MapReduce之上的改进。
(1)MapReduce中间结果落盘,计算效率低下
随着业务数据不断增多,业务逻辑不断多样化,很多ETL和数据预处理的工作需要多个MapReduce作业才能完成,但是MapReduce作业之间的数据交换需要通过写入外部存储才能完成,这样会导致频繁地磁盘读写,降低作业执行效率。
Spark设计之初,就想要解决频繁落盘问题。Spark只在需要交换数据的Shuffle阶段(Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算)才会写磁盘,其它阶段,数据都是按流式的方式进行并行处理。
(2)编程模型单一,场景表达能力有限
MapReduce模型只有Map和Reduce两个算子,计算场景的表达能力有限,这会导致用户在编写复杂的逻辑(例如join)时,需要自己写关联的逻辑,如果逻辑写得不够高效,还会影响性能。
与MapReduce不同,Spark将所有的逻辑业务流程都抽象成是对数据集合的操作,并提供了丰富的操作算子,如:join、sortBy、groupByKey等,用户只需要像编写单机程序一样去编写分布式程序,而不用关心底层Spark是如何将对数据集合的操作转换成分布式并行计算任务,极大的简化了编程模型
Spark的核心概念:RDD
Spark中最核心的概念是RDD(Resilient Distributed Dataset)——弹性分布式数据集,顾名思义,它是一个逻辑上统一、物理上分布的数据集合,Spark通过对RDD的一系列转换操作来表达业务逻辑流程,就像数学中对一个向量的一系列函数转换。
Spark通过RDD的转换依赖关系生成对任务的调度执行的有向无环图,并通过任务调度器将任务提交到计算节点上执行,任务的划分与调度是对业务逻辑透明的,极大的简化了分布式编程模型,RDD也丰富了分布式并行计算的表达能力。
RDD上的操作分为Transformation算子和Action算子。Transformation算子用于编写数据的变换过程,是指逻辑上组成变换过程。Action算子放在程序的最后一步,用于对结果进行操作,例如:将结果汇总到Driver端(collect)、将结果输出到HDFS(saveAsTextFile)等,这一步会真正地触发执行。
常见的Transformation算子包括:map、filter、groupByKey、join等,这里面又可以分为Shuffle算子和非Shuffle算子,Shuffle算子是指处理过程需要对数据进行重新分布的算子,如:groupByKey、join、sortBy等。常见的Action算子如:count、collect、saveAsTextFile等
如下是使用Spark编程模型编写经典的WordCount程序:

该程序通过RDD的算子对文本进行拆分、统计、汇总与输出。
Spark程序中涉及到几个概念,Application、Job、Stage、Task。每一个用户写的程序对应于一个Application,每一个Action生成一个Job(默认包含一个Stage),每一个Shuffle算子生成一个新的Stage,每一个Stage中会有N个Task(N取决于数据量或用户指定值)。
Spark的架构设计
前面讲述了Spark 核心逻辑概念,那么Spark的任务是如何运行在分布式计算环境的呢?接下来我们来看看开源框架Spark的架构设计。
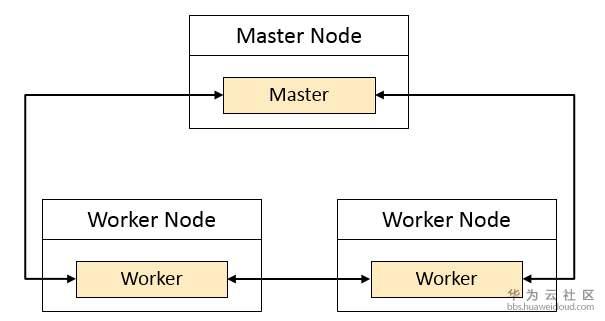
(注:涂色表示进程)
Spark是典型的主从(Master- Worker)架构,Master 节点上常驻 Master守护进程,负责管理全部的 Worker 节点。Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 Executor。
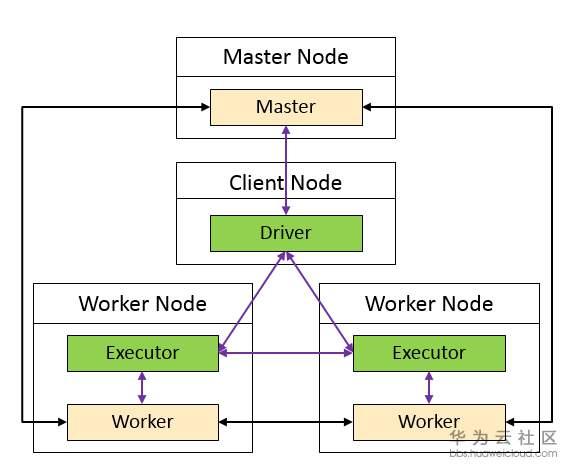
(注:橙色和绿色表示进程)
Spark程序在客户端提交时,会在Application的进程中启动一个Driver。看一下官方对Driver的解释“The process running the main() function of the application and creating the SparkContext”。
我们可以把Master和Worker看成是生产部总部老大(负责全局统一调度资源、协调生产任务)和生产部分部部长(负责分配、上报分部的资源,接收总部的命令,协调员工执行任务),把Driver和Executor看成是项目经理(负责分配任务和管理任务进度)和普通员工(负责执行任务、向项目经理汇报任务执行进度)。
项目经理D to 总部老大M:Hi,老大,我刚接了一个大项目,需要你通知下面的分部部长W安排一些员工组成联合工作小组。
总部老大M to 分部部长W:最近项目经理D接了一个大项目,你们几个部长都安排几个员工,跟项目经理D一起组成一个联合工作小组。
分部部长W to 员工E:今天把大家叫到一起,是有个大项目需要各位配合项目经理D去一起完成,稍后会成立联合工作小组,任务的分配和进度都直接汇报给项目经理D。
项目经理D to 员工E:从今天开始,我们会一起在这个联合工作小组工作一段时间,希望我们好好配合,把项目做好。好,现在开始分配任务…
员工E to 项目经理D:你分配的xxx任务已完成,请分配其它任务。
项目所有任务都完成后,项目经理D to 总部老大M:Hi,老大,项目所有的任务都已经完成了,联合工作小组可以解散了,感谢老大的支持。
以上就是Spark的基本框架,基于Apache Spark/Flink生态,DLI提供了完全托管的大数据处理分析服务。借助DLI服务,你只需要关注应用的处理逻辑,提供构建好的应用程序包,就可以轻松完成你的大规模数据处理分析任务,即开即用,按需计费。
华为云828企业上云节期间,购买数据湖探索DLI优惠更多。