Python爬取电影天堂激情动作片!
前言:
本文非常浅显易懂,可以说是零基础也可快速掌握。如有疑问,欢迎留言,小编会第一时间回复。
这里多说一句,小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以进裙609616831领取。
一、爬虫的重要性:
如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,一直循环下去,直到把整个网站所有的网页都抓取完为止。
二、实践:爬取电影天堂电影详情页
1、网页分析及爬取第一页的详情页url
从电影天堂最新电影界面。可以看到其第一页url为 www.ygdy8.net/html/gndy/d… ,第二页为www.ygdy8.net/html/gndy/d…,第三第四页也类似
from lxml import etree
import requests
url = \'http://www.ygdy8.net/html/gndy/dyzz/list_23_1.html\'
headers = {
\'User_Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\',
}
response = requests.get(url,headers=headers)
# response.text 是系统自己默认判断。但很遗憾判断错误,导致乱码出现。我们可以采取另外方式 response.content。自己指定格式解码
# print(response.text)
# print(response.content.decode(\'gbk\'))
print(response.content.decode(encoding="gbk", errors="ignore"))
先以第一页为例,打印数据如下:
分析电影天堂 html 源代码,可以得出每个 table 标签就是一个电影
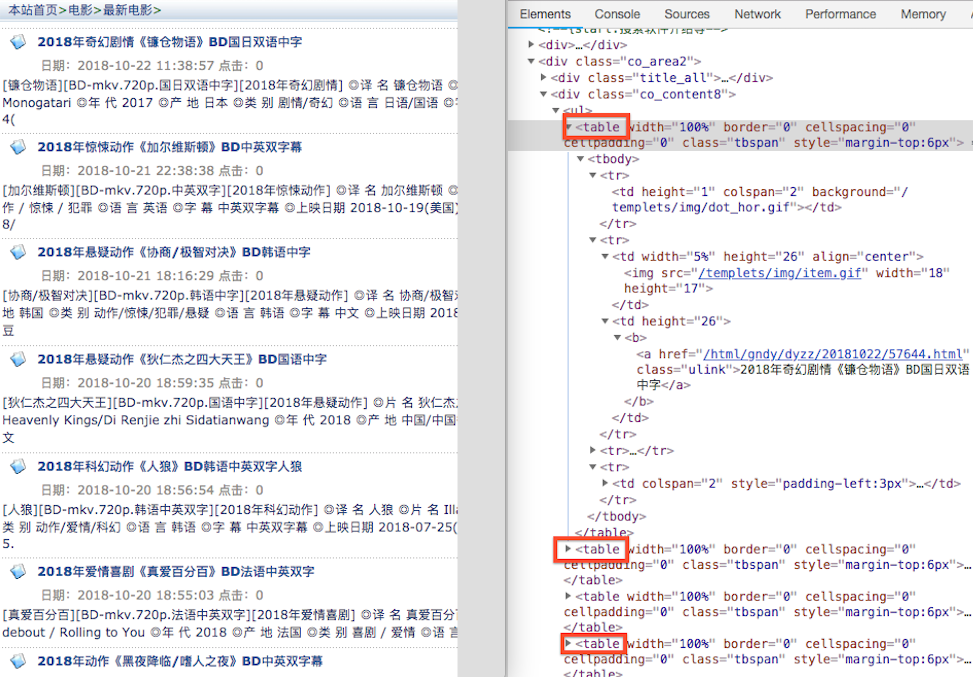
通过 xpath 拿到每个电影的详情url
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class=\'tbspan\']//a/@href")
for detail_url in detail_urls:
print(detail_url) #加上域名即为详情 url
结果如下:
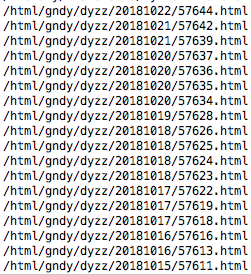
2、整理代码并爬取前7页的电影列表url
from lxml import etree
import requests
# 域名
BASE_DOMAIN = \'http://www.ygdy8.net\'
# url = \'http://www.ygdy8.net/html/gndy/dyzz/list_23_1.html\'
HEADERS = {
\'User_Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\',
}
def spider():
base_url = \'http://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html\'
for x in range(1,8):
url = base_url.format(x)
print(url) # 求出每一页电影列表的url eg: http://www.ygdy8.net/html/gndy/dyzz/list_23_1.html
if __name__ == \'__main__\':
spider()
3、爬取每一部电影的详情页地址
def get_detail_urls(url):
response = requests.get(url, headers=HEADERS)
# response.text 是系统自己默认判断。但很遗憾判断错误,导致乱码出现。我们可以采取另外方式 response.content。自己指定格式解码
# print(response.text)
# print(response.content.decode(\'gbk\'))
# print(response.content.decode(encoding="gbk", errors="ignore"))
text = response.content.decode(encoding="gbk", errors="ignore")
# 通过 xpath 拿到每个电影的详情url
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class=\'tbspan\']//a/@href")
detail_urls = map(lambda url:BASE_DOMAIN+url,detail_urls) #这句意思相当于下面一段代码:替换列表中的每一个url
# def abc(url):
# return BASE_DOMAIN+url
# index = 1
# for detail_url in detail_urls:
# detail_url = abc(detail_url)
# detail_urls[index] = detail_url
# index+1
return detail_urls
4、抓取电影详情页的数据
# 解析详情页面
def parse_detail_page(url):
movie = {}
response = requests.get(url,headers = HEADERS)
text = response.content.decode(\'gbk\', errors=\'ignore\')
html = etree.HTML(text)
# title = html.xpath("//div[@class=\'title_all\']//font[@color=\'#07519a\']") # 本行47行,下面已修改
# 打印出 [<Element font at 0x10cb422c8>, <Element font at 0x10cb42308>]
# print(title)
# 为了显示,我们需要转一下编码
# for x in title:
# print(etree.tostring(x,encoding=\'utf-8\').decode(\'utf-8\'))
# 我们是为了取得文字,所以修改47行
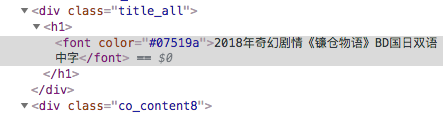
title = html.xpath("//div[@class=\'title_all\']//font[@color=\'#07519a\']/text()")[0]
movie[\'title\'] = title
zoomE = html.xpath("//div[@id=\'Zoom\']") [0] # 求出共同的顶级容器,方便后面求职
imgs = zoomE.xpath(".//img/@src") # 求出海报和截图
cover = imgs[0]
if len(imgs) > 1:
screenshot = imgs[1]
movie[\'screenshot\'] = screenshot
# print(cover)
movie[\'cover\'] = cover
infos = zoomE.xpath(".//text()")
for index,info in enumerate(infos):
if info.startswith(\'◎年  代\'):
info = info.replace("◎年  代", "").strip() # strip 去掉空格
movie[\'year\'] = info
elif info.startswith("◎产  地"):
info = info.replace("◎产  地", "").strip()
movie["country"] = info
elif info.startswith("◎类  别"):
info = info.replace("◎类  别", "").strip()
movie["category"] = info
elif info.startswith("◎豆瓣评分"):
info = info.replace("◎豆瓣评分", "").strip()
movie["douban_rating"] = info
elif info.startswith("◎片  长"):
info = info.replace("◎片  长","").strip()
movie["duration"] = info
elif info.startswith("◎导  演"):
info = info.replace("◎导  演", "").strip()
movie["director"] = info
elif info.startswith("◎主  演"):
actors = []
actor = info.replace("◎主  演", "").strip()
actors.append(actor)
# 因为主演有很多个,再加上其在电影天堂中元素的特殊性,需要遍历一遍,在分别求出每一个演员
for x in range(index+1,len(infos)): # 从演员 infos 开始遍历,求出每一个演员
actor = infos[x].strip()
if actor.startswith("◎"): # 也就是到了标签 的 ◎ 就退出
break
actors.append(actor)
movie[\'actor\'] = actors
elif info.startswith(\'◎简  介 \'):
# info = info.replace(\'◎简  介 \',"").strip()
for x in range(index+1,len(infos)):
if infos[x].startswith("◎获奖情况"):
break
profile = infos[x].strip()
movie[\'profile\'] = profile
# print(movie)
elif info.startswith(\'◎获奖情况 \'):
awards = []
# info = info.replace("◎获奖情况 ", "").strip()
for x in range(index+1,len(infos)):
if infos[x].startswith("【下载地址】"):
break
award = infos[x].strip()
awards.append(award)
movie[\'awards\'] = awards
# print(awards)
download_url = html.xpath("//td[@bgcolor=\'#fdfddf\']/a/@href")[0]
movie[\'download_url\'] = download_url
return movie
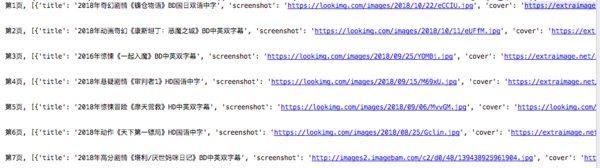
上述代码爬取了电影的每一个数据。为了让读者方便对照格式,笔者已经下载了写此篇文章时的html—— “movie.html”,放于github 中
最后结果:
在这里还是要推荐下我自己建的Python学习群:609616831,群里都是学Python的,如果你想学或者正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2020最新的Python进阶资料和零基础教学,欢迎进阶中和对Python感兴趣的小伙伴加入!
