拓端tecdat|Python代写中用PyTorch机器学习分类预测银行客户流失模型
Python中用PyTorch机器学习分类预测银行客户流失模型
原文链接:http://tecdat.cn/?p=8522
分类问题属于机器学习问题的类别,其中给定一组功能,任务是预测离散值。分类问题的一些常见示例是,预测肿瘤是否为癌症,或者学生是否可能通过考试。
在本文中,鉴于银行客户的某些特征,我们将预测客户在6个月后是否可能离开银行。客户离开组织的现象也称为客户流失。因此,我们的任务是根据各种客户特征预测客户流失。
$ pip install pytorch
数据集
让我们将所需的库和数据集导入到我们的Python应用程序中:
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
我们可以使用库的read_csv()方法pandas来导入包含我们的数据集的CSV文件。
dataset = pd.read_csv(r\'E:Datasets\customer_data.csv\')
让我们打印数据集 :
dataset.shape
输出:
(10000, 14)
输出显示该数据集具有1万条记录和14列。
我们可以使用head()pandas数据框的方法来打印数据集的前五行。
dataset.head()
输出:
您可以在我们的数据集中看到14列。根据前13列,我们的任务是预测第14列的值,即Exited。
探索性数据分析
让我们对数据集进行一些探索性数据分析。我们将首先预测6个月后实际离开银行并使用饼图进行可视化的客户比例。
让我们首先增加图形的默认绘图大小:
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 10
fig_size[1] = 8
plt.rcParams["figure.figsize"] = fig_size
以下脚本绘制该Exited列的饼图。
dataset.Exited.value_counts().plot(kind=\'pie\', autopct=\'%1.0f%%\', colors=[\'skyblue\', \'orange\'], explode=(0.05, 0.05))
输出:
输出显示,在我们的数据集中,有20%的客户离开了银行。这里1代表客户离开银行的情况,0代表客户没有离开银行的情况。
让我们绘制数据集中所有地理位置的客户数量:
输出显示,几乎一半的客户来自法国,而西班牙和德国的客户比例分别为25%。
现在,让我们绘制来自每个唯一地理位置的客户数量以及客户流失信息。我们可以使用库中的countplot()函数seaborn来执行此操作。
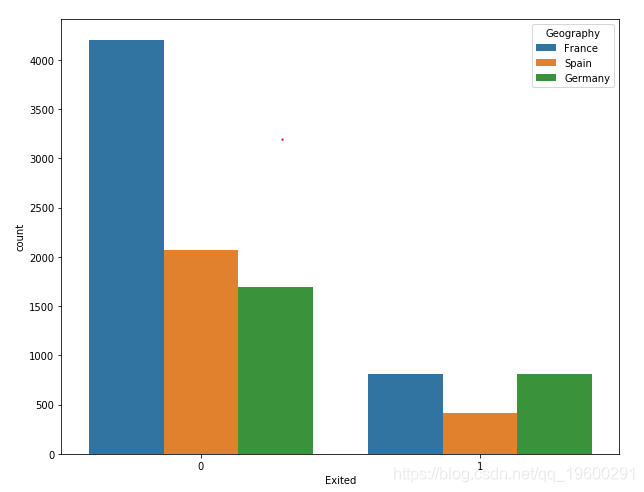
输出显示,尽管法国客户总数是西班牙和德国客户总数的两倍,但法国和德国客户离开银行的客户比例是相同的。同样,德国和西班牙客户的总数相同,但是离开银行的德国客户数量是西班牙客户的两倍,这表明德国客户在6个月后离开银行的可能性更大。
数据预处理
在训练PyTorch模型之前,我们需要预处理数据。如果查看数据集,您将看到它具有两种类型的列:数值列和分类列。数字列包含数字信息。CreditScore,Balance,Age等。类似地,Geography和Gender是分类列,因为它们含有分类信息,如客户的位置和性别。有几列可以视为数字列和类别列。例如,该HasCrCard列的值可以为1或0。但是,那HasCrCard列包含有关客户是否拥有信用卡的信息。 但是,这完全取决于数据集的领域知识。
让我们再次输出数据集中的所有列,并找出哪些列可以视为数字列,哪些列应该视为类别列。columns数据框的属性显示所有列名称:
Index([\'RowNumber\', \'CustomerId\', \'Surname\', \'CreditScore\', \'Geography\',
\'Gender\', \'Age\', \'Tenure\', \'Balance\', \'NumOfProducts\', \'HasCrCard\',
\'IsActiveMember\', \'EstimatedSalary\', \'Exited\'],
dtype=\'object\')
从我们的数据列,我们将不使用的RowNumber,CustomerId以及Surname列,因为这些列的值是完全随机的,并与输出无关。例如,客户的姓氏对客户是否离开银行没有影响。其中列的其余部分,Geography,Gender,HasCrCard,和IsActiveMember列可以被视为类别列。让我们创建这些列的列表:
除该列外,其余所有列均可视为数字列。
numerical_columns = [\'CreditScore\', \'Age\', \'Tenure\', \'Balance\', \'NumOfProducts\', \'EstimatedSalary\']
最后,输出(Exited列中的值)存储在outputs变量中。
我们已经创建了分类,数字和输出列的列表。但是,目前,分类列的类型不是分类的。您可以使用以下脚本检查数据集中所有列的类型:
输出:
RowNumber int64
CustomerId int64
Surname object
CreditScore int64
Geography object
Gender object
Age int64
Tenure int64
Balance float64
NumOfProducts int64
HasCrCard int64
IsActiveMember int64
EstimatedSalary float64
Exited int64
dtype: object
您可以看到Geographyand Gender列的类型是object,HasCrCardand IsActive列的类型是int64。我们需要将分类列的类型转换为category。我们可以使用astype()函数来做到这一点,如下所示:
现在,如果再次绘制数据集中各列的类型,您将看到以下结果:
输出量
RowNumber int64
CustomerId int64
Surname object
CreditScore int64
Geography category
Gender category
Age int64
Tenure int64
Balance float64
NumOfProducts int64
HasCrCard category
IsActiveMember category
EstimatedSalary float64
Exited int64
dtype: object
现在让我们查看Geography列中的所有类别:
输出:
Index([\'France\', \'Germany\', \'Spain\'], dtype=\'object\')
当您将列的数据类型更改为类别时,该列中的每个类别都会分配一个唯一的代码。例如,让我们绘制列的前五行,Geography并打印前五行的代码值:
输出:
0 France
1 Spain
2 France
3 France
4 Spain
Name: Geography, dtype: category
Categories (3, object): [France, Germany, Spain]
以下脚本在该列的前五行中绘制了值的代码Geography:
输出:
0 0
1 2
2 0
3 0
4 2
dtype: int8
输出显示法国已编码为0,西班牙已编码为2。
将分类列与数字列分开的基本目的是,可以将数字列中的值直接输入到神经网络中。但是,必须首先将类别列的值转换为数字类型。分类列中的值的编码部分地解决了分类列的数值转换的任务。
由于我们将使用PyTorch进行模型训练,因此需要将分类列和数值列转换为张量。
首先让我们将分类列转换为张量。在PyTorch中,可以通过numpy数组创建张量。我们将首先将四个分类列中的数据转换为numpy数组,然后将所有列水平堆叠,如以下脚本所示:
geo = dataset[\'Geography\'].cat.codes.values
...上面的脚本打印出分类列中前十条记录,这些记录是水平堆叠的。输出如下:
输出:
array([[0, 0, 1, 1],
[2, 0, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 0],
[2, 0, 1, 1],
[2, 1, 1, 0],
[0, 1, 1, 1],
[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 1, 1, 1]], dtype=int8)
现在要从上述numpy数组创建张量,您只需将数组传递给模块的tensor类torch。
输出:
tensor([[0, 0, 1, 1],
[2, 0, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 0],
[2, 0, 1, 1],
[2, 1, 1, 0],
[0, 1, 1, 1],
[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 1, 1, 1]])
在输出中,您可以看到类别数据的numpy数组现在已转换为tensor对象。
同样,我们可以将数值列转换为张量:
numerical_data = np.stack([dataset[col].values for col in numerical_columns], 1)
...输出:
tensor([[6.1900e+02, 4.2000e+01, 2.0000e+00, 0.0000e+00, 1.0000e+00, 1.0135e+05],
[6.0800e+02, 4.1000e+01, 1.0000e+00, 8.3808e+04, 1.0000e+00, 1.1254e+05],
[5.0200e+02, 4.2000e+01, 8.0000e+00, 1.5966e+05, 3.0000e+00, 1.1393e+05],
[6.9900e+02, 3.9000e+01, 1.0000e+00, 0.0000e+00, 2.0000e+00, 9.3827e+04],
[8.5000e+02, 4.3000e+01, 2.0000e+00, 1.2551e+05, 1.0000e+00, 7.9084e+04]])
在输出中,您可以看到前五行,其中包含我们数据集中六个数字列的值。
最后一步是将输出的numpy数组转换为tensor对象。
...输出:
tensor([1, 0, 1, 0, 0])
现在,让我们绘制分类数据,数值数据和相应输出的形状:
...
输出:
torch.Size([10000, 4])
torch.Size([10000, 6])
torch.Size([10000])
在训练模型之前,有一个非常重要的步骤。我们将分类列转换为数值,其中唯一值由单个整数表示。例如,在该Geography列中,我们看到法国用0表示,德国用1表示。我们可以使用这些值来训练我们的模型。但是,更好的方法是以N维向量的形式表示分类列中的值,而不是单个整数。
我们需要为所有分类列定义嵌入尺寸(矢量尺寸)。关于维数没有严格的规定。定义列的嵌入大小的一个好的经验法则是将列中唯一值的数量除以2(但不超过50)。例如,对于该Geography列,唯一值的数量为3。该Geography列的相应嵌入大小将为3/2 = 1.5 = 2(四舍五入)。
以下脚本创建一个元组,其中包含所有类别列的唯一值数量和维度大小:
categorical_column_sizes = [len(dataset[column].cat.categories) for column in categorical_columns]
...输出:
[(3, 2), (2, 1), (2, 1), (2, 1)]
使用训练数据对监督型深度学习模型(例如我们在本文中开发的模型)进行训练,并在测试数据集上评估模型的性能。因此,我们需要将数据集分为训练集和测试集,如以下脚本所示:
total_records = 10000
....我们的数据集中有1万条记录,其中80%的记录(即8000条记录)将用于训练模型,而其余20%的记录将用于评估模型的性能。注意,在上面的脚本中,分类和数字数据以及输出已分为训练集和测试集。
为了验证我们已正确地将数据分为训练和测试集:
print(len(categorical_train_data))
print(len(numerical_train_data))
print(len(train_outputs))
print(len(categorical_test_data))
print(len(numerical_test_data))
print(len(test_outputs))
输出:
8000
8000
8000
2000
2000
2000
创建预测模型
我们将数据分为训练集和测试集,现在是时候定义训练模型了。为此,我们可以定义一个名为的类Model,该类将用于训练模型。看下面的脚本:
class Model(nn.Module):
def __init__(self, embedding_size, num_numerical_cols, output_size, layers, p=0.4):
super().__init__()
self.all_embeddings = nn.ModuleList([nn.Embedding(ni, nf) for ni, nf in embedding_size])
self.embedding_dropout = nn.Dropout(p)
self.batch_norm_num = nn.BatchNorm1d(num_numerical_cols)
...
return x
接下来,要查找输入层的大小,将类别列和数字列的数量加在一起并存储在input_size变量中。之后,for循环迭代,并将相应的层添加到all_layers列表中。添加的层是:
-
Linear:用于计算输入和权重矩阵之间的点积 -
ReLu:用作激活功能 -
BatchNorm1d:用于对数字列应用批量归一化 -
Dropout:用于避免过度拟合
在后for循环中,输出层被附加到的层的列表。由于我们希望神经网络中的所有层都按顺序执行,因此将层列表传递给nn.Sequential该类。
接下来,在该forward方法中,将类别列和数字列都作为输入传递。类别列的嵌入在以下几行中进行。
embeddings = []
...数字列的批量归一化可通过以下脚本应用:
x_numerical = self.batch_norm_num(x_numerical)
最后,将嵌入的分类列x和数字列x_numerical连接在一起,并传递给sequence layers。
训练模型
要训练模型,首先我们必须创建Model在上一节中定义的类的对象。
...
您可以看到我们传递了分类列的嵌入大小,数字列的数量,输出大小(在我们的例子中为2)以及隐藏层中的神经元。您可以看到我们有三个分别具有200、100和50个神经元的隐藏层。您可以根据需要选择其他尺寸。
让我们打印模型并查看:
print(model)
输出:
Model(
(all_embeddings): ModuleList(
...
)
)
您可以看到,在第一线性层中,in_features变量的值为11,因为我们有6个数字列,并且类别列的嵌入维数之和为5,因此6 + 5 = 11。out_features的值为2,因为我们只有2个可能的输出。
在实际训练模型之前,我们需要定义损失函数和将用于训练模型的优化器。
以下脚本定义了损失函数和优化器:
loss_function = nn.CrossEntropyLoss()
...现在,我们拥有训练模型所需的一切。以下脚本训练模型:
epochs = 300
aggregated_losses = []
for i in range(epochs):
...
print(f\'epoch: {i:3} loss: {single_loss.item():10.10f}\')
神经元元数设置为300,这意味着要训练模型,完整的数据集将使用300次。for为300倍和在每次迭代期间循环的执行方式,损失是使用损耗函数来计算。每次迭代过程中的损失将添加到aggregated_loss列表中。要更新权重,将backward()调用single_loss对象的功能。最后,函数的step()方法optimizer更新渐变。
上面脚本的输出如下:
epoch: 1 loss: 0.71847951
epoch: 26 loss: 0.57145703
epoch: 51 loss: 0.48110831
epoch: 76 loss: 0.42529839
epoch: 101 loss: 0.39972275
epoch: 126 loss: 0.37837571
epoch: 151 loss: 0.37133673
epoch: 176 loss: 0.36773482
epoch: 201 loss: 0.36305946
epoch: 226 loss: 0.36079505
epoch: 251 loss: 0.35350436
epoch: 276 loss: 0.35540250
epoch: 300 loss: 0.3465710580
以下脚本绘制了各个时期的损失:
plt.plot(range(epochs), aggregated_losses)
plt.ylabel(\'Loss\')
plt.xlabel(\'epoch\');
输出:
输出显示,最初损耗迅速降低。在第250个时代之后,损失几乎没有减少。
做出预测
最后一步是对测试数据进行预测。为此,我们只需要将categorical_test_data和传递numerical_test_data给model该类。然后可以将返回的值与实际测试输出值进行比较。以下脚本对测试类进行预测,并打印测试数据的交叉熵损失。
with torch.no_grad():
...输出:
Loss: 0.36855841
测试集上的损失为0.3685,比训练集上获得的0.3465略多,这表明我们的模型有些过拟合。
由于我们指定输出层将包含2个神经元,因此每个预测将包含2个值。例如,前5个预测值如下所示:
print(y_val[:5])
输出:
tensor([[ 1.2045, -1.3857],
[ 1.3911, -1.5957],
[ 1.2781, -1.3598],
[ 0.6261, -0.5429],
[ 2.5430, -1.9991]])
这种预测的思想是,如果实际输出为0,则索引0处的值应大于索引1处的值,反之亦然。我们可以使用以下脚本检索列表中最大值的索引:
y_val = np.argmax(y_val, axis=1)
输出:
现在让我们再次打印y_val列表的前五个值:
print(y_val[:5])
输出:
tensor([0, 0, 0, 0, 0])
由于在最初预测的输出列表中,对于前五个记录,零索引处的值大于第一索引处的值,因此可以在已处理输出的前五行中看到0。
最后,我们可以使用confusion_matrix,accuracy_score以及classification_report类从sklearn.metrics模块找到了准确度,精密度和召回值测试集,与混淆矩阵一起。
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
print(confusion_matrix(test_outputs,y_val))
print(classification_report(test_outputs,y_val))
print(accuracy_score(test_outputs, y_val))
输出:
[[1527 83]
[ 224 166]]
precision recall f1-score support
0 0.87 0.95 0.91 1610
1 0.67 0.43 0.52 390
micro avg 0.85 0.85 0.85 2000
macro avg 0.77 0.69 0.71 2000
weighted avg 0.83 0.85 0.83 2000
0.8465
输出结果表明,我们的模型达到了84.65%的精度,考虑到我们随机选择神经网络模型的所有参数这一事实,这非常令人印象深刻。我建议您尝试更改模型参数,例如训练/测试比例,隐藏层的数量和大小等,以查看是否可以获得更好的结果。
结论
PyTorch是Facebook开发的常用深度学习库,可用于各种任务,例如分类,回归和聚类。本文介绍了如何使用PyTorch库对表格数据进行分类。