通俗易懂讲解Word2vec的本质
本文首发于微信公众号「对白的算法屋」,来一起学AI叭
一、Word2vec
CBOW(Continuous Bag-of-Words):每个词的含义都由相邻词决定。
Skip-gram:依据分布的相似性,一个词的含义可以通过上下文获得。
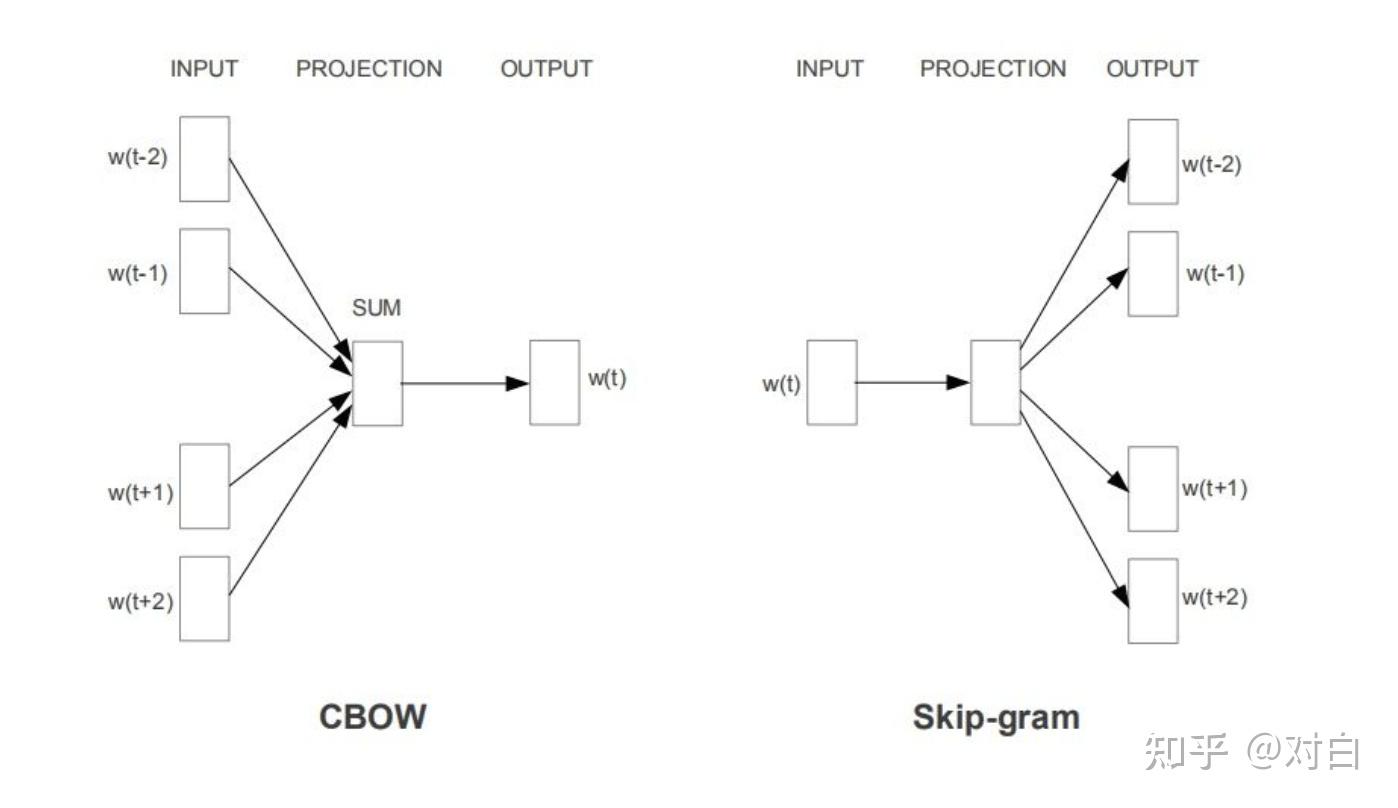
注:Skip-gram 是预测一个词的上下文,而 CBOW 是用上下文预测这个词
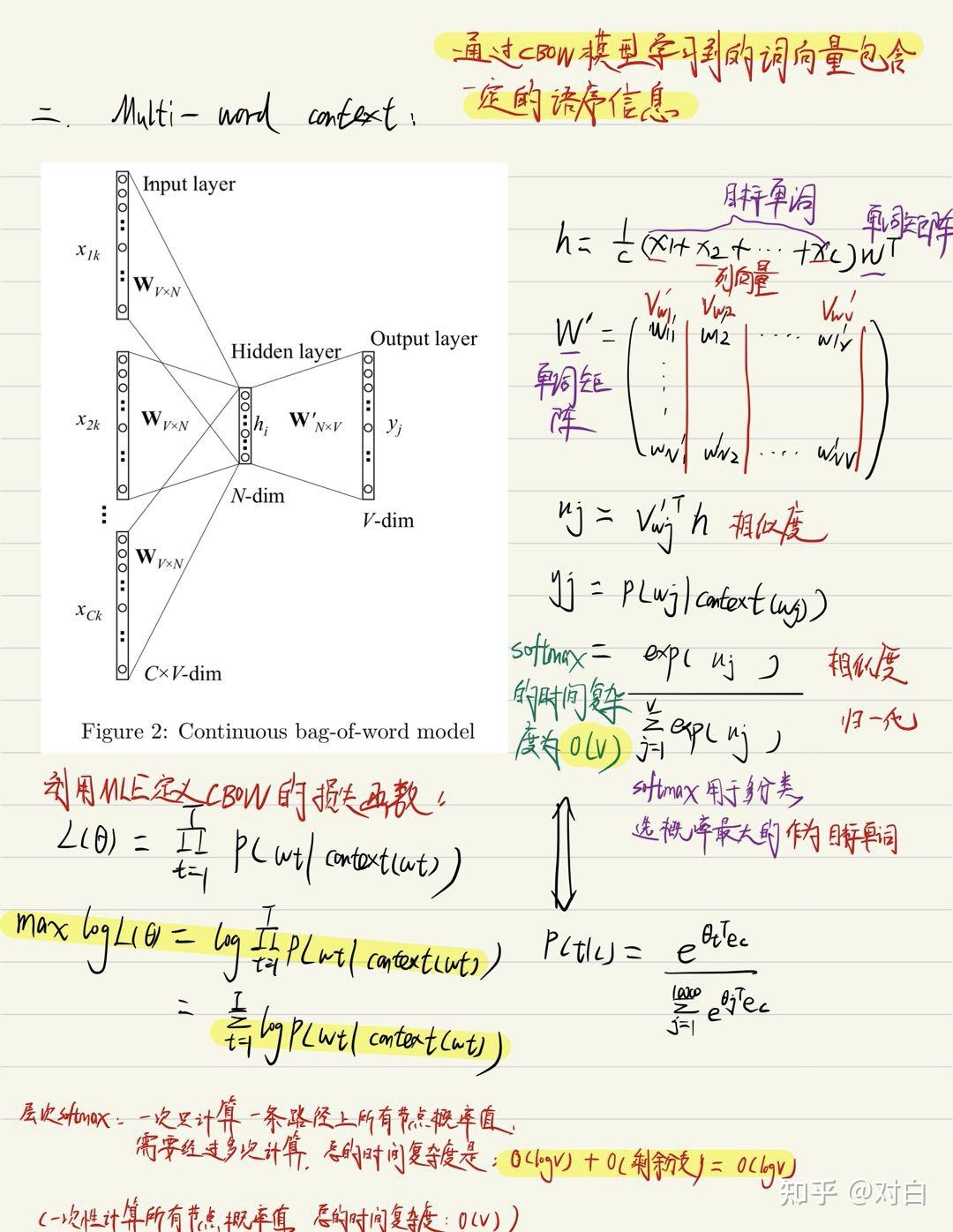
1.1 CBOW (one-word context):

1.2 CBOW (Multi-word context):
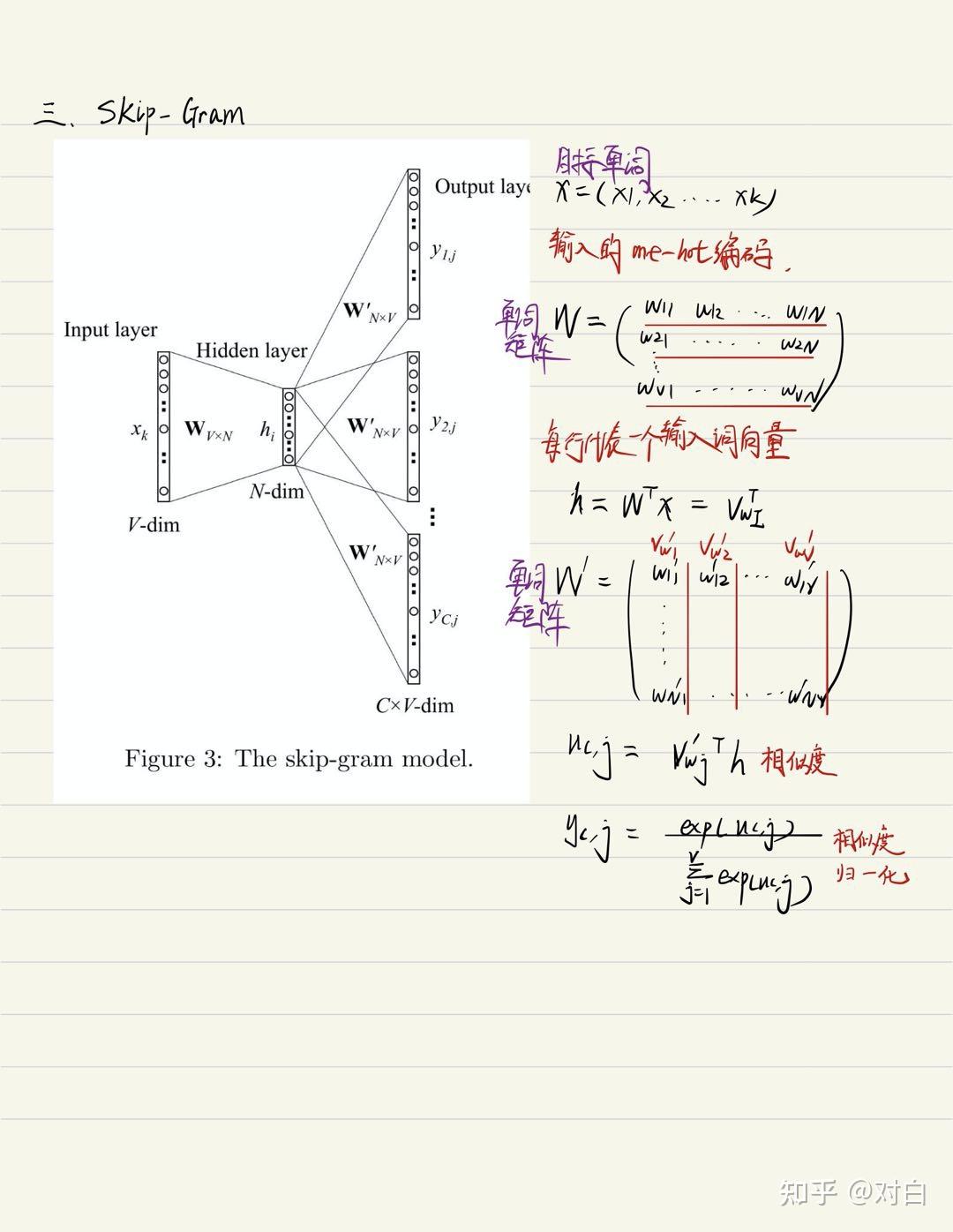
1.3 Skip-gram:
二、计算效率优化技术
2.1 Hierarchical Softmax技术:
诞生背景:word2vec为什么不用现成的DNN模型,要继续优化出新方法呢?最主要的问题是DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。
优化思路:使用哈夫曼树来代替隐藏层和输出层的神经元,哈夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大。 而内部节点则起到隐藏层神经元的作用。

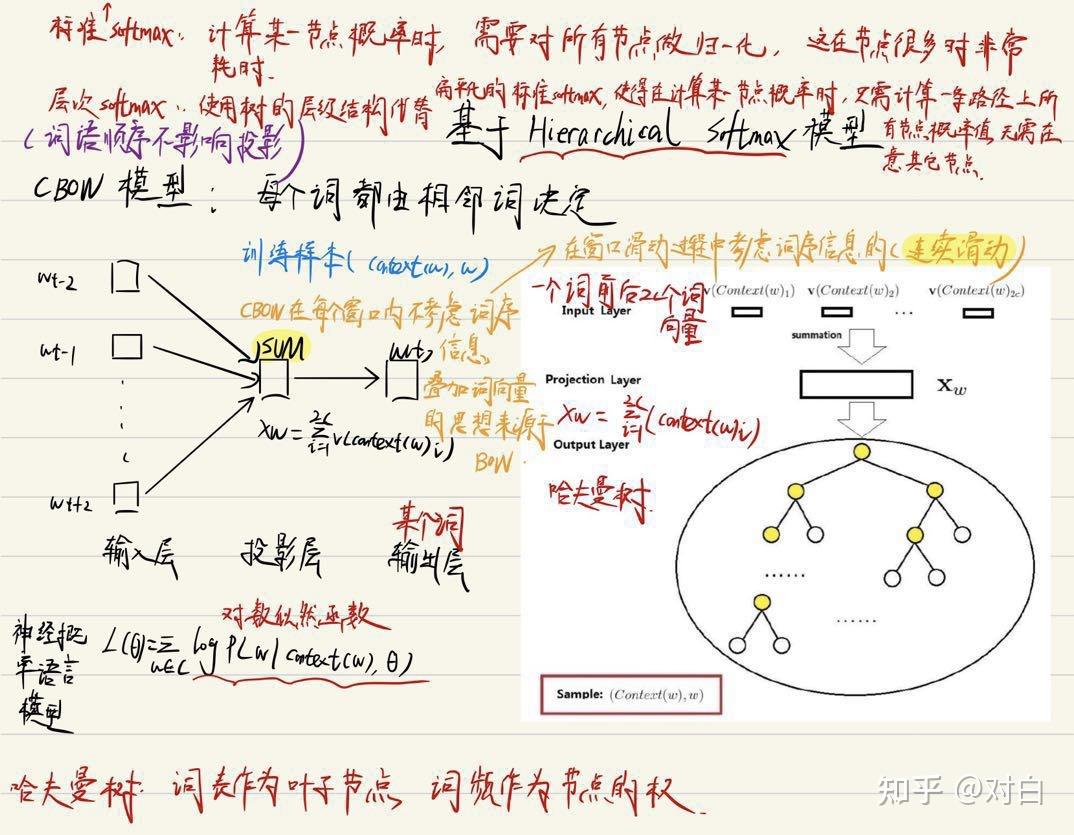
由于我们把之前所有都要计算的从输出softmax层的概率计算变成了一颗二叉哈夫曼树,那么我们的softmax概率计算只需要沿着树形结构进行就可以了。在哈夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着哈夫曼树一步步完成的,因此这种softmax取名为”Hierarchical Softmax”。
现在有一句话:“我喜欢观看足球世界杯”,我们需要通过Hierarchical Softmax获得“足球”的词向量,则哈夫曼树结构如下所示:
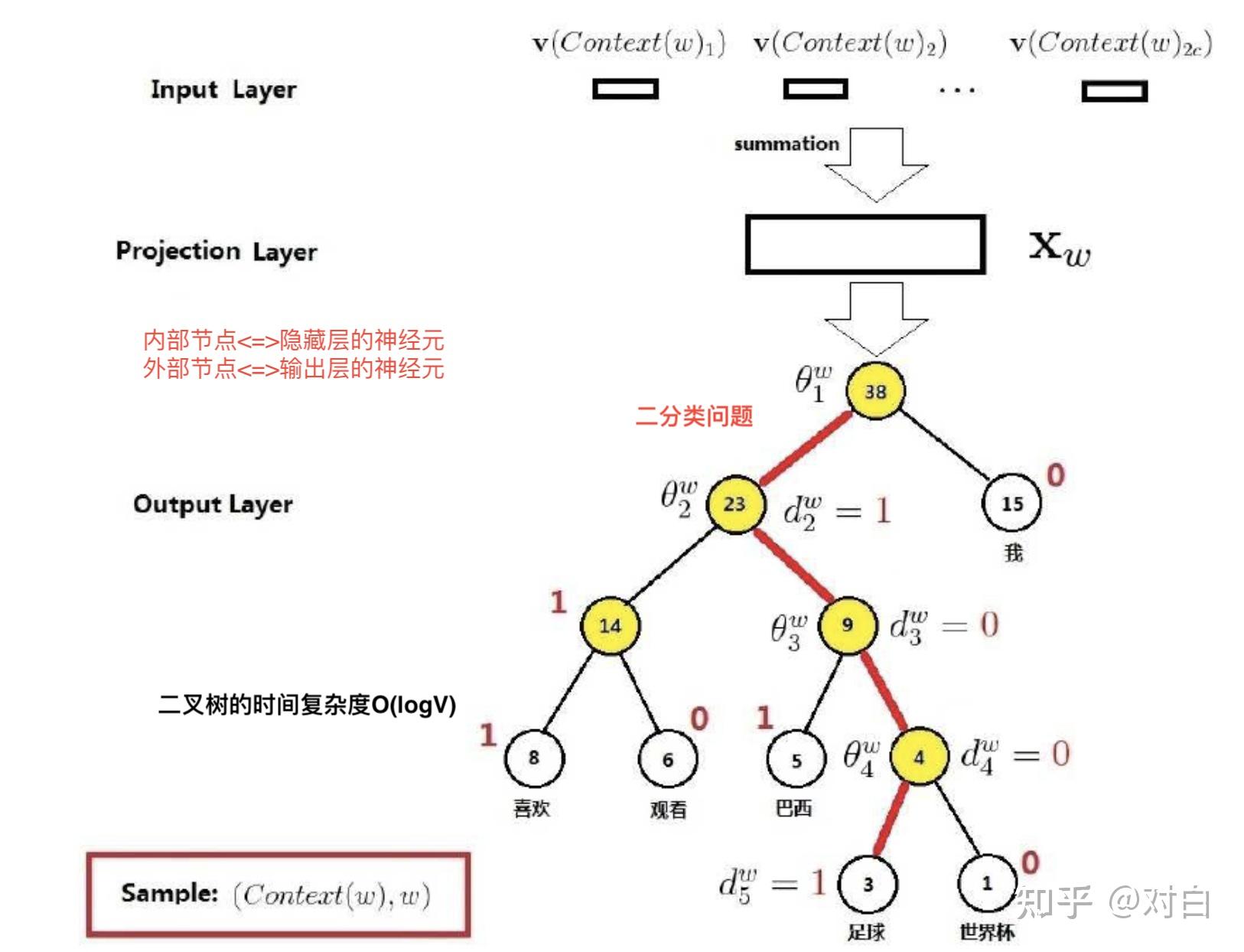
以图中ω=“足球”为例,从根节点出发到达“足球”这个叶子节点,中间共经历了4次分支(每条红色的边对应一次分支),而每一次分支都可视为进行了一次二分类。
既然是从二分类的角度来考虑问题,那么对于每一个非叶子节点,就需要为其左右孩子结点指定一个类别,即哪个是正类(标签为1),哪个是负类(标签为0)。
Word2vec定义编码为0是正类,编码为1是负类。
根据逻辑回归,易知一个结点被分为正类的概率是
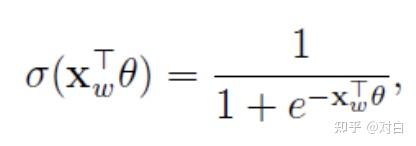
被分为负类的概率是:
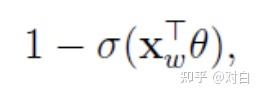
对于从根节点出发到达“足球”这个叶子节点所经历的4次二分类,将每次分类结果的概率写出来是:
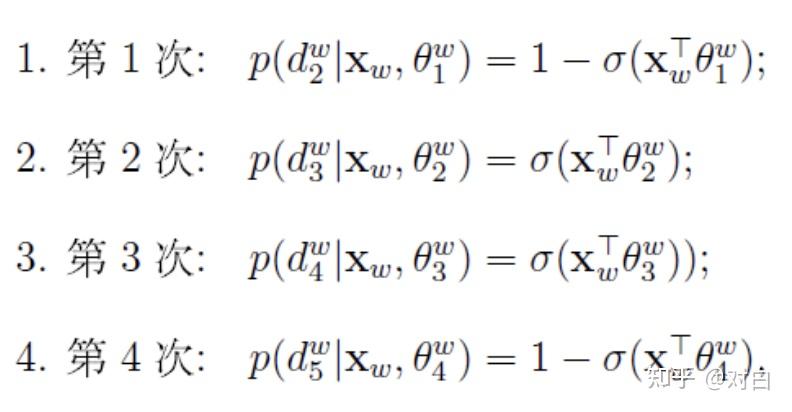
但是,我们要求的是P(足球|Contex(足球)),它跟着4个概率值有什么关系呢?关系就是
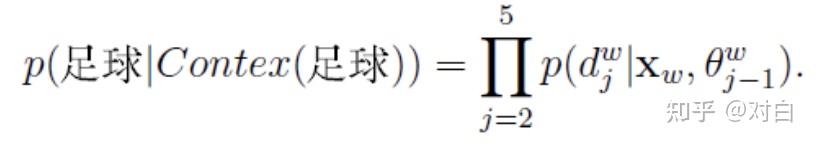
至此,通过w=“足球”这个例子,Hierarchical Softmax的基本思想其实就已经介绍完了。
总结:对于词典中任意词ω,哈夫曼树中必存在一条从根节点到词w对应结点的路径pω(且这条路径是唯一的)。路径pω上存在lω-1个分支,将每个分支看做一次二分类,每一次分类就产生一个概率,将这些概率连乘起来,就是所需的P(ω|Context(ω))。
条件概率P(ω|Context(ω))的一般公式可写为:
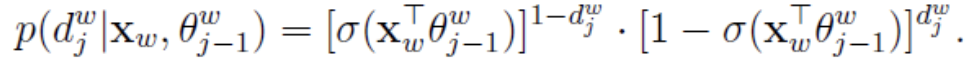
将上式代入对数似然函数便得:
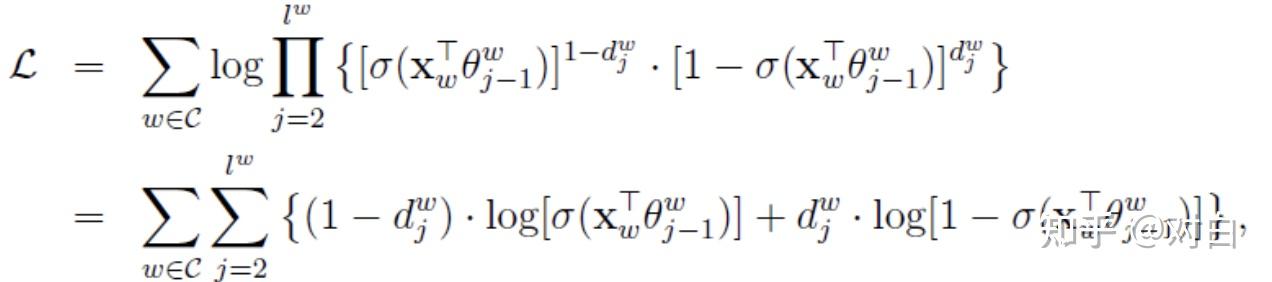
为下面梯度推导方便起见,将上式中双重求和符号下花括号里的内容简记为:
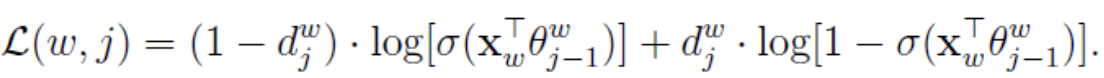
以上就是CBOW模型的目标函数。在word2vec中,由于使用的是随机梯度上升法,所以并没有把所有样本的似然乘起来得到真正的训练集最大似然,仅仅每次只用一个样本更新梯度,这样做的目的是减少梯度计算量。
要得到模型中 词向量和内部节点的模型参数 , 我们使用梯度上升法即可。首先我们求模型参数 的梯度:
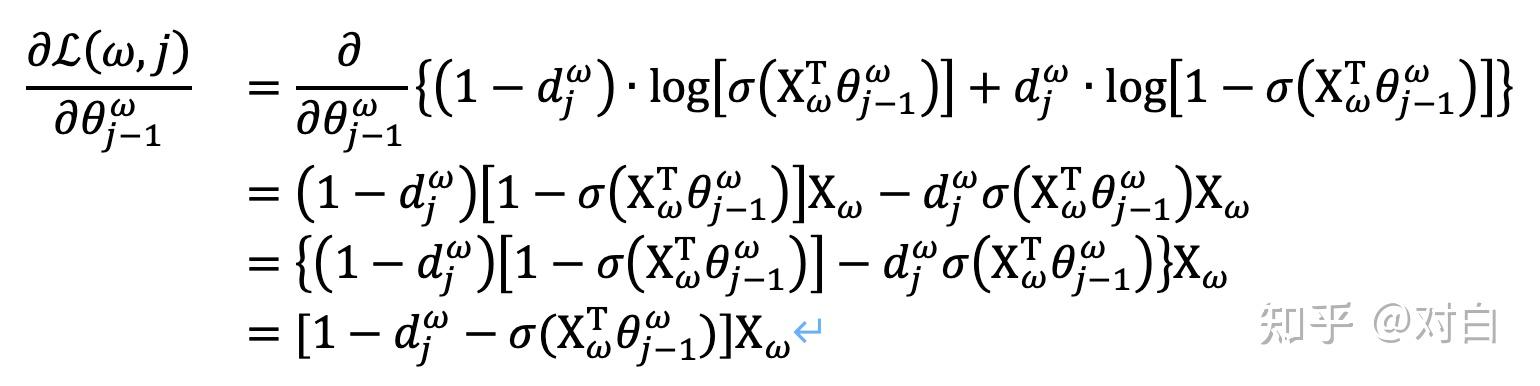
同样的方法,可以求出 的梯度表达式如下:
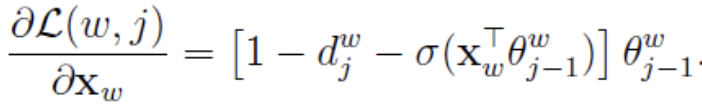
有了梯度表达式,我们就可以用梯度上升法进行迭代来一步步的求解我们需要的所有的 −1和 。
Hierarchical Softmax的优缺点:
优点:将softmax问题转化为多层二分类问题。
缺点:当目标词是一个生僻词时,从根节点到叶子节点的路径将会非常长,这无疑增加了计算量。
2.2 Negative Sampling技术:
Negative Sampling是NCE(Noise Contrastive Estimation)的一个简化版本,目的是用来提高训练速度并改善词向量的质量(低频词)。与Hierarchical Softmax相比,NEG不再使用复杂的哈夫曼树,而是利用相对简单的随机负采样,能大幅提高性能,因而可作为Hierarchical Softmax的一种替代。
2.2.1 CBOW模型:
在CBOW模型中,已知词ω的上下文Context(ω),需要预测ω,因此,对于给定的Context(ω),词ω就是一个正样本,其它词就是负样本了。



2.2.2 负采样构建训练集的方法:


最后欢迎大家关注我的微信公众号:对白的算法屋(duibainotes),跟踪NLP、推荐系统和对比学习等机器学习领域前沿。
想进一步交流的同学也可以通过公众号加我的微信一同探讨技术问题,谢谢。