L1正则化和L2正则化的理解
机器学习中,如果参数过多,模型过于复杂,容易造成过拟合(overfit)。即模型在训练样本数据上表现的很好,但在实际测试样本上表现的较差,不具备良好的泛化能力。为了避免过拟合,最常用的一种方法是使用使用正则化,例如 L1 和 L2 正则化。但是,正则化项是如何得来的?其背后的数学原理是什么?L1 正则化和 L2 正则化之间有何区别?本文将给出直观的解释。
1. L2 正则化直观解释
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:
其中,Ein 是未包含正则化项的训练样本误差,λ 是正则化参数,可调。但是正则化项是如何推导的?接下来,我将详细介绍其中的物理意义。
我们知道,正则化的目的是限制参数过多或者过大,避免模型更加复杂。例如,使用多项式模型,如果使用 10 阶多项式,模型可能过于复杂,容易发生过拟合。所以,为了防止过拟合,我们可以将其高阶部分的权重 w 限制为 0,这样,就相当于从高阶的形式转换为低阶。
为了达到这一目的,最直观的方法就是限制 w 的个数,但是这类条件属于 NP-hard 问题,求解非常困难。所以,一般的做法是寻找更宽松的限定条件:
上式是对 w 的平方和做数值上界限定,即所有w 的平方和不超过参数 C。这时候,我们的目标就转换为:最小化训练样本误差 Ein,但是要遵循 w 平方和小于 C 的条件。
下面,我用一张图来说明如何在限定条件下,对 Ein 进行最小化的优化。
如上图所示,蓝色椭圆区域是最小化 Ein 区域,红色圆圈是 w 的限定条件区域。在没有限定条件的情况下,一般使用梯度下降算法,在蓝色椭圆区域内会一直沿着 w 梯度的反方向前进,直到找到全局最优值 wlin。例如空间中有一点 w(图中紫色点),此时 w 会沿着 -∇Ein 的方向移动,如图中蓝色箭头所示。但是,由于存在限定条件,w 不能离开红色圆形区域,最多只能位于圆上边缘位置,沿着切线方向。w 的方向如图中红色箭头所示。
那么问题来了,存在限定条件,w 最终会在什么位置取得最优解呢?也就是说在满足限定条件的基础上,尽量让 Ein 最小。
我们来看,w 是沿着圆的切线方向运动,如上图绿色箭头所示。运动方向与 w 的方向(红色箭头方向)垂直。运动过程中,根据向量知识,只要 -∇Ein 与运行方向有夹角,不垂直,则表明 -∇Ein 仍会在 w 切线方向上产生分量,那么 w 就会继续运动,寻找下一步最优解。只有当 -∇Ein 与 w 的切线方向垂直时,-∇Ein在 w 的切线方向才没有分量,这时候 w 才会停止更新,到达最接近 wlin 的位置,且同时满足限定条件。

-∇Ein 与 w 的切线方向垂直,即 -∇Ein 与 w 的方向平行。如上图所示,蓝色箭头和红色箭头互相平行。这样,根据平行关系得到:
移项,得:
这样,我们就把优化目标和限定条件整合在一个式子中了。也就是说只要在优化 Ein 的过程中满足上式,就能实现正则化目标。
接下来,重点来了!根据最优化算法的思想:梯度为 0 的时候,函数取得最优值。已知 ∇Ein 是 Ein 的梯度,观察上式,λw 是否也能看成是某个表达式的梯度呢?
当然可以!λw 可以看成是 1/2λw*w 的梯度:
这样,我们根据平行关系求得的公式,构造一个新的损失函数:
之所以这样定义,是因为对 Eaug 求导,正好得到上面所求的平行关系式。上式中等式右边第二项就是 L2 正则化项。
这样, 我们从图像化的角度,分析了 L2 正则化的物理意义,解释了带 L2 正则化项的损失函数是如何推导而来的。
2. L1 正则化直观解释
L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值:
我仍然用一张图来说明如何在 L1 正则化下,对 Ein 进行最小化的优化。
Ein 优化算法不变,L1 正则化限定了 w 的有效区域是一个正方形,且满足 |w| < C。空间中的点 w 沿着 -∇Ein 的方向移动。但是,w 不能离开红色正方形区域,最多只能位于正方形边缘位置。其推导过程与 L2 类似,此处不再赘述。
3. L1 与 L2 解的稀疏性
介绍完 L1 和 L2 正则化的物理解释和数学推导之后,我们再来看看它们解的分布性。
以二维情况讨论,上图左边是 L2 正则化,右边是 L1 正则化。从另一个方面来看,满足正则化条件,实际上是求解蓝色区域与黄色区域的交点,即同时满足限定条件和 Ein 最小化。对于 L2 来说,限定区域是圆,这样,得到的解 w1 或 w2 为 0 的概率很小,很大概率是非零的。
对于 L1 来说,限定区域是正方形,方形与蓝色区域相交的交点是顶点的概率很大,这从视觉和常识上来看是很容易理解的。也就是说,方形的凸点会更接近 Ein 最优解对应的 wlin 位置,而凸点处必有 w1 或 w2 为 0。这样,得到的解 w1 或 w2 为零的概率就很大了。所以,L1 正则化的解具有稀疏性。
扩展到高维,同样的道理,L2 的限定区域是平滑的,与中心点等距;而 L1 的限定区域是包含凸点的,尖锐的。这些凸点更接近 Ein 的最优解位置,而在这些凸点上,很多 wj 为 0。
关于 L1 更容易得到稀疏解的原因,有一个很棒的解释,请见下面的链接:
https://www.zhihu.com/question/37096933/answer/70507353
4. 正则化参数 λ
正则化是结构风险最小化的一种策略实现,能够有效降低过拟合。损失函数实际上包含了两个方面:一个是训练样本误差。一个是正则化项。其中,参数 λ 起到了权衡的作用。
以 L2 为例,若 λ 很小,对应上文中的 C 值就很大。这时候,圆形区域很大,能够让 w 更接近 Ein 最优解的位置。若 λ 近似为 0,相当于圆形区域覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。相反,若 λ 很大,对应上文中的 C 值就很小。这时候,圆形区域很小,w 离 Ein 最优解的位置较远。w 被限制在一个很小的区域内变化,w 普遍较小且接近 0,起到了正则化的效果。但是,λ 过大容易造成欠拟合。欠拟合和过拟合是两种对立的状态。
转自:微信公众号红色的石头
作者:魏晋
链接:https://www.zhihu.com/question/26485586/answer/89215997
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
L1 Norm 和L2 Norm的区别(核心:L2对大数,对outlier更敏感!):
考虑一个很简单的最小Norm的优化问题:
MINIMIZE ∥x∥ WITH RESPECT TO Ax=b
假设Ax=b有无数可行解,那么再假设a=(0.5,0.5)和b=(-1,0)都是可行解,那么计算这个两个向量的L1和L2 Norm,
||a||1=1, ||b||1=1; ||a||2=1/squre(2), ||b||2=1。很明显,a和b L1 Norm相同,而但是b的L2 Norm却大于a的L2 Norm。
L2 Norm对大数的惩罚比小数大! 因为使用L2 Norm求出来的解是比较均匀的,而L1 Norm常常产生稀疏解。
再从统计概率的角度来看,L1 Norm和L2 Norm其实对向量中值的分布有着不同的先验假设:
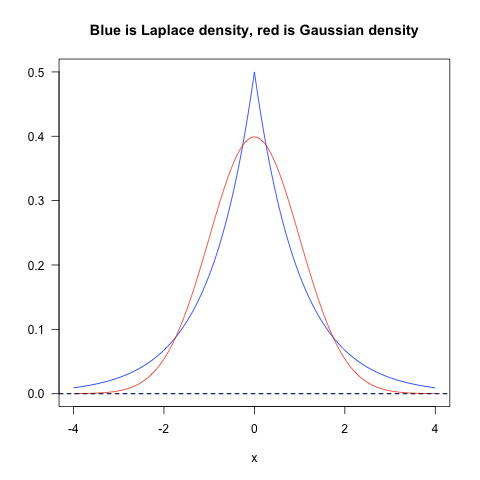
L1是蓝色的线,L2是红色的线,很明显,L1的分布对极端值更能容忍。
那么如果数据损失项使用L1 Norm,很明显,L1 Norm对outlier没有L2 Norm那么敏感;如果正则化损失项使用L1的话,那么使学习到的参数倾向于稀疏,使用L2 Norm则没有这种倾向。
实践中,根据Quaro的data scientist Xavier Amatriain 的经验,实际应用过程中,L1 nrom几乎没有比L2 norm表现好的时候,优先使用L2 norm是比较好的选择。
理论上讲,参数如果服从高斯分布就用l2,拉普拉斯分布就用l1。实际上你也不知道参数该服从什么分布,所以一般如果你需要稀疏性就用l1,比如参数量很大情况,一般不单独用l2吧,可以l1+l2,不过最终还是看效果…哪个好就用哪个…另外一般框架使用l1,可能也不能保证稀疏性,取决于底层实现…