Hive-06 Hive和HBase的集成
1. 与Hive的集成
Hive和Hbase在大数据架构中处在不同位置,Hive是一个构建在Hadoop基础之上的数据仓库,主要解决分布式存储的大数据处理和计算问题,Hive提供了类SQL语句,叫HiveQL,
通过它可以使用SQL查询存放在HDFS上的数据,sql语句最终被转化为Map/Reduce任务运行,但是Hive不能够进行交互查询——它只能够在Haoop上批量的执行Map/Reduce任务。
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase是Hadoop database 的简称,是一种NoSQL数据库,非常适用于海量明细数据(十亿、百亿)的随机实时查询,如交易清单、轨迹行为等。
在大数据架构中,Hive和HBase是协作关系,Hive方便地提供了Hive QL的接口来简化MapReduce的使用, 而HBase提供了低延迟的数据库访问。如果两者结合,可以利用MapReduce的优势针对HBase存储的大量内容进行离线的计算和分析。
Hive和HBase的通信原理
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,
这种相互通信是通过$HIVE_HOME/lib/hive-hbase-handler-*.jar工具类实现的。通过HBaseStorageHandler,Hive可以获取到Hive表所对应的HBase表名,列簇和列,InputFormat、OutputFormat类,创建和删除HBase表等。基本通信原理如下:
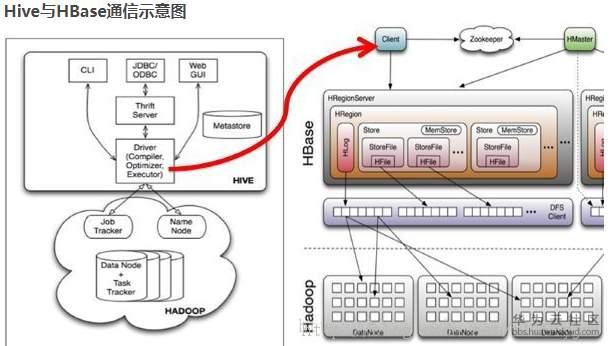
访问
Hive访问HBase中HTable的数据,实质上是通过MR读取HBase的数据,而MR是使用HiveHBaseTableInputFormat完成对表的切分,获取RecordReader对象来读取数据的。
对HBase表的切分原则是一个Region切分成一个Split,即表中有多少个Regions,MR中就有多少个Map;
读取HBase表数据都是通过构建Scanner,对表进行全表扫描,如果有过滤条件,则转化为Filter。当过滤条件为rowkey时,则转化为对rowkey的过滤;Scanner通过RPC调用RegionServer的next()来获取数据。
简单来说,Hive和Hbase的集成就是,打通了Hive和Hbase,使得Hive中的表创建之后,可以同时是一个Hbase的表,并且在Hive端和Hbase端都可以做任何的操作。
使用场景:
(一)将ETL操作的数据通过Hive加载到HBase中,数据源可以是文件也可以是Hive中的表。

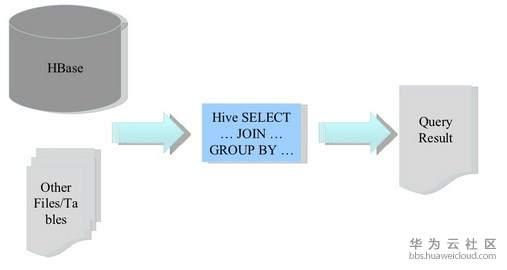
(二)Hbae作为Hive的数据源,通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
(三)构建低延时的数据仓库
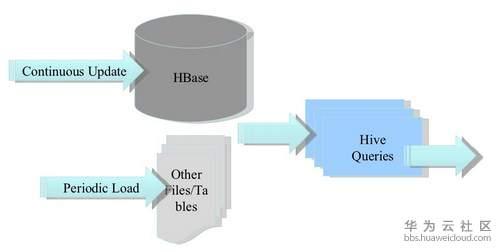
以上原理来自知乎:https://zhuanlan.zhihu.com/p/74041611
HBase与Hive的集成在最新的两个版本中无法兼容。所以,我们只能重新编译:hive-hbase-handler-1.2.2.jar!
将所需要的lib的jar包导入进行编译; apache-hive-1.2.1-src\hbase-handler\src\java
操作Hive的同时对HBase也会产生影响,所以Hive需要持有操作HBase的Jar,那么接下来拷贝Hive所依赖的Jar包(或者使用软连接的形式)。
对hive添加的jar添加到这个参数,需重启;相当于hbase的客户端-hive,hive和hbase集成所依赖的类
export HIVE_AUX_JARS_PATH=/opt/module/hbase-1.3.1/lib/*
同时在hive-site.xml中修改zookeeper的属性,如下:
<property> <name>hive.zookeeper.quorum</name> <value>hadoop101,hadoop102,hadoop103</value> <description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> <description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property>
建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
hive表字段映射到hbase中;用stored by指定下格式类型hbase;指定映射关系;serd是序列化和反序列化;列顺序和字段一一对应;:key即rowkey
hive中表删,hbase中就没有了; 这样建立出来的表插入的源数据都是在Hbase里面存放着,当从Hbase中删除记录的同时也会删除在Hive中的数据
Hive建内部表与Hbase进行关联 — 文件存储在Hbase中 —
内部表,这种情况是hbase本来没有这张表,创建后会在hbase中同样创建一张表,将来数据也是存放在hbase中的;hdfs的hive表目录有hive文件夹,但是里面没有数据。
这时,如果使用load data 命令导入数据会报错,因为该表是non-native table。
当hive使用overwrite关键字进行插入数据时,原本数据不会被删除,有同样的行健会被更新覆盖。因为数据是存在hbase中的,遵守hbase插入数据的规则。
- 当hive删除hive表时,hbase表也会删除。
- 当先删除hbase的时候,先disabled table,然后drop table;这时hbase表就被删除了,zookeeper里面也就删除了。但是hive里面还在,用show tables还能查出来。mysql中TBLS里面还有hive表的信息。但是用select * from hive 查询的时候报错,表不存在(TableNotFoundException)然后删除hive里面的表的时候会报错TableNotFoundException)。继续show tables时,发现表已经不在了。TBLS里面也没有hive表了。
0: jdbc:hive2://hadoop101:10000> create table hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
stored by \'org.apache.hadoop.hive.hbase.HBaseStorageHandler\' with serdeproperties ("hbase.columns.mapping"=":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") tblproperties ("hbase.table.name"="hbase_emp_table","hbase.mapred.output.outputtable"="hbase_emp_table");
说明:
a、 在tblproperties 语句中
“hbase.table.name”定义的是在hbase中的表名 ,这个属性是可选的,仅当你想在Hive和Hbase中使用不同名字的表名时才需要填写,如果使用相同的名字则可以省略;
”hbase.mapred.output.outputtable”定义的hbase_emp_table是存储数据表的名称,指定插入数据时写入的表,如果以后需要往该表插入数据就需要指定该值,这个可以不要,表数据就存储在第二个表中了 。
b、stored by \’org.apache.hadoop.hive.hbase.HBaseStorageHandler\’ :是指定处理的存储器,就是hive-hbase-handler-*.jar包,要做hive和hbase的集成必须要加上这一句;
c、“hbase.columns.mapping” 是定义在hive表中的字段怎么与hbase的列族进行映射。
例如:info就是列族,ename就是列。它们之间通过“:”连接。
在hive中创建的hive_hbase_emp_table表,映射为hbase中的表hbase_emp_table,其中:key对应hbase的rowkey,value对应hbase的列。
完成之后,可以分别进入Hive和HBase查看,都生成了对应的表
在Hive中创建临时中间表,用于load文件中的数据; 不能将数据直接load进Hive所关联HBase的那张表中;要经过mapreduce;
向hive_hbase_emp_table表中插入数据:
hive> insert into table hive_hbase_emp_table select * from emp;
查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
Hive:
hive> select * from hive_hbase_emp_table;
HBase:
hbase> scan ‘hbase_emp_table’ 或者 describe ‘hbase_emp_table’
对于在hbase已经存在的表(可提前设计rowkey),在hive中使用CREATE EXTERNAL TABLE来建立联系
在HBase中建立预分区表;然后再在HIVE中用外表映射到已建立好的HBase表中
在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive-sql来分析HBase这张表中的数据。建立这样的外表,数据也是在hbase中存放,hive会在hdfs中创建目录,但没有数据文件。
一般的情况Hbase的数据可能先存在要怎么关联到Hive中( 这类是外链表删除Hive中的表不影响Hbase中的数据 )
注意:在创建hive的外表时,可以引用hbase中不存在列
同样,不能使用load data命令给外表加载数据,因为该表使用HBaseStorageHandler创建的:
- 删除hive表对hbase没有影响;
- 但是先删除hbase表hive就会报TableNotFoundException;
创建外部表:
create external table relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
stored by \'org.apache.hadoop.hive.hbase.HBaseStorageHandler\'
with serdeproperties ("hbase.columns.mapping"=":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
tblproperties ("hbase.table.name"="hbase_emp_table");
关联后就可以使用Hive函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;
hbase中已有表,去关联它,创建外部表即可;hive中删表,数据在hbase中还是存在的;
多列和多列族
例如: hbase中id,name,age可拆分成多个Hive表:
CREATE EXTERNAL TABLE test_hbase_1 ( id STRING, name STRING) STORED BY \'org.apache.hadoop.hive.hbase.HBaseStorageHandler\' WITH SERDEPROPERTIES (\'hbase.table.name\'=\'test:table1\', \'hbase.mapred.output.outputtable\'=\'test:table1\', \'hbase.columns.mapping\'=\':key,f:name\') CREATE EXTERNAL TABLE test_hbase_2 ( id STRING, age STRING) STORED BY \'org.apache.hadoop.hive.hbase.HBaseStorageHandler\' WITH SERDEPROPERTIES ( \'hbase.table.name\'=\'test:table1\', \'hbase.mapred.output.outputtable\'=\'test:table1\', \'hbase.columns.mapping\'=\':key, f:age\'); drop table test_hbase_3; CREATE EXTERNAL TABLE test_hbase_3 ( id STRING, name STRING, age STRING) STORED BY \'org.apache.hadoop.hive.hbase.HBaseStorageHandler\' WITH SERDEPROPERTIES ( \'hbase.table.name\'=\'test:table1\', \'hbase.mapred.output.outputtable\'=\'test:table1\', \'hbase.columns.mapping\'=\':key,f:name,f:age\')
可以看到,同一张HBase表可以映射多张 Hive 外部表,并且查询列互不影响。
可见向不同 Hive 外部表中插入数据是不会影响HBase其他列的。
insert into 与 insert overwrite 操作HBase-Hive映射外部表结果是一样的,且均是基于Hive表所属列进行更新,不会影响其他列的值。
注意点
1、HBase 中的空 cell 在 Hive 中会补 null
2、Hive 和 HBase 中不匹配的字段会补 null
3、Bytes 类型的数据,建 Hive 表示加#b, 因为 HBase 中 double,int , bigint 类型以byte方式存储时,用字符串取出来必然是乱码。
4、其中:key代表的是 HBase 中的 rowkey, Hive 中也要有一个 key 与之对应, 不然会报错, cf 指的是 HBase 的列族, 创建完后,会自动把 HBase 表里的数据同步到 Hive 中
使用Hive集成HBase表的需注意
- 对HBase表进行预分区,增大其MapReduce作业的并行度
- 合理的设计rowkey使其尽可能的分布在预先分区好的Region上
- 通过set hbase.client.scanner.caching设置合理的扫描缓存
2. MapReduce
用MapReduce将数据从本地文件系统导入到HBase的表中,
比如从HBase中读取一些原始数据后使用MapReduce做数据分析。
结合计算型框架进行计算统计
查看HBase的MapReduce任务的执行,把jar打印出来的就是需要添加到hadoop的CLASSPATH下的jar包
$ bin/hbase mapredcp
环境变量的导入
(1)执行环境变量的导入(临时生效,在命令行执行下述操作)
$ export HBASE_HOME=/opt/module/hbase $ export HADOOP_HOME=/opt/module/hadoop-2.7.2 $ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
(2)永久生效
在etc/hadoop下hadoop-env.sh中配置:(注意:在for循环之后配),要重启下才生效 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*
运行官方的MapReduce任务
-- 案例一:统计Student表中有多少行数据; 要在hbase中先有student表 $ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter student -- 案例二:使用MapReduce将hdfs数据导入到HBase 1)在本地创建一个tsv格式的文件:fruit.tsv Apple Red Pear Yellow Pineapple Yellow 2)创建HBase表 hbase(main):001:0> create \'fruit\',\'info\' 3)在HDFS中创建input_fruit文件夹并上传fruit.tsv文件 [kris@hadoop101 hadoop-2.7.2]$ hdfs dfs -mkdir /hbase/input_fruit [kris@hadoop101 datas]$ hadoop fs -put fruit.tsv /hbase/input_fruit //把表名写死了;不写死可以通过命令行run(String[] args)传参 [kris@hadoop101 hadoop-2.7.2]$ bin/yarn jar HbaseTest-1.0-SNAPSHOT.jar com.atguigu.mr.ReadFromTableDriver bin/yarn jar HbaseTest-1.0-SNAPSHOT.jar com.atguigu.mr2.ReadFromHdfsDriver /fruit.tsv fruit_mr //给它传参数 4)执行MapReduce到HBase的fruit表中 [kris@hadoop101 hadoop-2.7.2]$ bin/yarn jar /opt/module/hbase-1.3.1/lib/hbase-server-1.3.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit /hbase/input_fruit //hdfs://hadoop101:9000/这个可省略 5)使用scan命令查看导入后的结果 hbase(main):001:0> scan ‘fruit’
① 将fruit表中的一部分数据,通过MR迁入到fruit_mr表中。
从hbase中读取数据;
输入的k,v类型已经写好(ImmutableBytesWritable key,Result value),要自定义输出类型k,v
ReadFromTableMapper.java //把hbase中的fruit表中的一部分数据,通过MR迁入到fruit_mr表, fruit_mr要先在hbase中创建好。 public class ReadFromTableMapper extends TableMapper<ImmutableBytesWritable, Put> { @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { //1.获取rowkey//不可变的字节数组,按rowkey来读;scan扫描的封装到了result(1行里边的所有数据) byte[] rowkey = key.get(); //2.创建put对象 Put put = new Put(rowkey); //创建put对象时要指定rowkey //3.添加列的信息 for (Cell cell : value.rawCells()) { //获取这1列的所有cell if ("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){ if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); }else if ("color".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); } } } context.write(key, put); } } ReadFromTableReducer.java // TableReducer<KEYIN, VALUEIN, KEYOUT> extends Reducer<KEYIN, VALUEIN, KEYOUT, Mutation> //Mutation,Delete和Put都是它的子类;Hbase中每次操作可看做mutation这个类; Put已经封装了rowkey等所有数据 reducer初始化没有用到nullwritable public class ReadFromTableReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> { @Override protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException { for (Put put : values) { context.write(NullWritable.get(), put); } } } ReadFromTableDriver.jva //实现Tool接口,执行任务时用ToolRunner调 public class ReadFromTableDriver implements Tool { private Configuration configuration = null; public int run(String[] strings) throws Exception { //获取任务并设置 //1.获取job对象 Job job = Job.getInstance(configuration); //2.设置job对象 job.setJarByClass(ReadFromTableDriver.class); Scan scan = new Scan();//在这里传参数StartRow StopRow scan.setCacheBlocks(true); //设置缓存 scan.setCaching(100); //扫100条数据再跟Hbase的server端交互,减少次数 TableMapReduceUtil.initTableMapperJob("fruit", scan, //mapper去读数据; ReadFromTableMapper.class, ImmutableBytesWritable.class,//k v; fruit可通过args[0]传参 Put.class, job); TableMapReduceUtil.initTableReducerJob("fruit_mr", //插入数据的表 //工具类初始化map,reduce ReadFromTableReducer.class, job); boolean b = job.waitForCompletion(true); return b ? 0 : 1; //1表false } public void setConf(Configuration conf) { //hadoop的8个配置文件封装到Configuration中 this.configuration = conf; } public Configuration getConf() { return configuration; } public static void main(String[] args) throws Exception { int run = ToolRunner.run(new ReadFromTableDriver(), args); //最终调用的是上边的run方法;tool对象即ReadFromTableDriver的对象 System.exit(run);//run为0或1 } }
打包运行任务
$ /opt/module/hadoop-2.7.2/bin/yarn jar hbase-0.0.1-SNAPSHOT.jar com.atguigu.mr.ReadFromTableDriver
②实现将HDFS中的数据写入到HBase表中。
写入到Hbase;泛型,输入k,value;value已定义好immutaion;需自定义k
public class ReadFromHdfsTableMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { private ImmutableBytesWritable k = new ImmutableBytesWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1.获取1行 String line = value.toString(); //2.切割 String[] fields = line.split("\t"); //3.获取put对象 String rowkey = fields[0]; Put put = new Put(Bytes.toBytes(rowkey)); //添加列信息| 列族/列名 put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(fields[1])); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("color"), Bytes.toBytes(fields[2])); context.write(k, put); } } public class ReadFromHdfsTableReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> { @Override protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException { for (Put put : values) { context.write(NullWritable.get(), put); } } } public class ReadFromHdfsDriver implements Tool { private Configuration configuration; public int run(String[] args) throws Exception { Job job = Job.getInstance(); job.setJarByClass(ReadFromTableDriver.class); job.setMapperClass(ReadFromTableMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); //设置文件路径 FileInputFormat.setInputPaths(job, new Path(args[0])); TableMapReduceUtil.initTableReducerJob(args[1], ReadFromTableReducer.class, job); boolean b = job.waitForCompletion(true); return b ? 0 : 1; } public void setConf(Configuration conf) { configuration =conf; } public Configuration getConf() { return configuration; } public static void main(String[] args) throws Exception { int run = ToolRunner.run(new ReadFromTableDriver(), args); //传Tool对象 System.exit(run); } }
打包运行 $ /opt/module/hadoop-2.7.2/bin/yarn jar hbase-0.0.1-SNAPSHOT.jar com.atguigu.mr2.ReadFromHdfsDriver 提示:运行任务前,如果待数据导入的表不存在,则需要提前创建之。
hadoop jar
yarn jar
8032rm和yarn的通信端口号