金融数据智能峰会 | 数据规模爆炸性增长,企业如何进行精准决策?云原生数据仓库数据化运营实战分享

阿里云数据库资深技术专家魏闯先
一、背景与趋势
(一)阿里巴巴15年云计算实践
回顾阿里巴巴十五年来云原生发展的道路,大致分为三个阶段。

第一个阶段是2006年~2015年的应用架构互联网化阶段,是云原生从0到1的过程。最早的时候,阿里巴巴在淘宝上做中间件,那是最早的云的雏形。当时我们研究的是Oracle数据库和IBM的小型机。但阿里巴巴发现一个问题,就是随着淘宝流量越来越大,Oracle的机器无法继续满足业务需求,三个月之后,我们的数据将存不下也算不了。这是非常严重的问题,所以当时阿里巴巴启动了去IOE的计划。
这个时候,阿里巴巴发现我们的业务做得非常好,但技术上有很多挑战。因此,阿里巴巴在2009年成立了阿里云,自研飞天操作系统,开启云化时代,淘宝和天猫合并建设业务中台,届时三大中间件核心系统上线。
飞天操作系统基于Apsara,是一个分布式的操作系统。在基础公共模块之上有两个最核心的服务:盘古和伏羲。盘古是存储管理服务,伏羲是资源调度服务,飞天内核之上应用的存储和资源的分配都是由盘古和伏羲管理。飞天核心服务分为:计算、存储、数据库、网络。
为了帮助开发者便捷地构建云上应用,飞天提供了丰富的连接、编排服务,将这些核心服务方便地连接和组织起来,包括:通知、队列、资源编排、分布式事务管理等等。
飞天最顶层是阿里云打造的软件交易与交付第一平台—-云市场。它如同云计算的“App Store”,用户可在阿里云官网一键开通“软件+云计算资源”。云市场上架在售商品几千个,支持镜像、容器、编排、API、SaaS、服务、下载等类型的软件与服务接入。
这就是最早的云的基础框架,也是一个云原生的架构。
从2011年开始,我们开始做容器调度,在集团里面开始做在线业务,在线的业务开始走容器化。到了2013年,自研飞天操作系统全面支撑集团业务。
2015年,阿里云的云原生技术不单是给阿里巴巴的内部业务使用,也开始对外做商业化,以上就是第一阶段。
第二阶段是2016年~2019年的核心系统全面云原生化阶段。
从2017年开始,我们不只做在线了,离线也全部采用了云原生的技术。双11购物节有大量的交易数据,这些数据的后台分析和后期处理都是交给离线完成。我们基于云原生把在线和离线的底层资源池统一,支撑百万级规模电商交易。
到了2019年,阿里巴巴核心系统100%上云,这其实非常难,因为阿里巴巴的业务量非常巨大,任何普通的系统都无法支撑。
第三阶段是2020年至今,是全面升级下一代云原生技术的阶段。阿里巴巴成立云原生技术委员会,云原生升级为阿里技术新战略。阿里巴巴核心系统全面使用云原生产品支撑大促。阿里云云原生技术全面升级,Serverless时代开启。
(二)阿里云对于云计算的断言
阿里巴巴是怎样看待云计算的?云计算和传统技术的差别到底是什么?
举个例子,在一个家家户户都需要挖井的村庄里,每家根据自家人口数量、大概需要的出水量、是否会有客人来等等因素,决定挖多宽的井。如果遇上家里客人比较多或者干旱了等状况,水可能就不够用了。除了挖井的成本外,日常维护这口井,也需要很高的成本。
上述场景映射到企业中,就是企业基于自己的IT基础,还要到运营商那里买个机房,买几台服务器来支撑自己的服务。如果后续这些机器闲置的话,企业仍然需要支付一大笔费用,成本非常高。
云解决的问题就是通过虚拟化的技术实现资源池化,用上方挖井例子来形容就是建一个自来水厂。自来水厂和井的差别在于,第一,供水量很大,即使来100个客人,供水量也能满足需求。第二,前期不需要投入大量成本去挖井,而是根据用水需求按量计费。即使接通自来水管道,如果不用,那么永远也不需要为它付费。
这为企业带来了两大好处,第一个是企业需要做快速决策的时候,不用花大量时间去“挖井”,而是开箱即用。第二是前期投入成本很低。
这就是云带来的好处,那么什么是云原生呢?
云原生是个标准服务,很多东西我们不需要提前规划。比如我要做数字化转型,需求很简单。我需要有人给我提供这个服务,我要多少,他给我分配多少,不需要我去做提前的准备。随着我业务的增长,它底下的基础设施能够随之一起增长,具有非常好的弹性。这也大大地减少企业成本与精力,可以更加专注地去做最擅长的事情,大幅提升效率。
通过以上的例子,下面这几点就非常好理解了。

首先,我们认为容器+K8s会成为云计算的新界面,这是未来的一个趋势。
其次,整个软件生命周期也会发生变化。原来软件的生命周期很长,现在通过云原生的技术可以做到迭代速度越来越快,向下延伸软硬一体化、向上延伸架构现代化等都可以去做。
最后,加速企业数字化升级。原来做企业数字化转型非常复杂,可能要买机器、买数据库、买应用,需要三年五载的时间来完成。而如今的企业数字化转型,只花短短数月的时间,便可实现完全转型。
(三)业界趋势:数据生产/处理正在发生质变
从业界趋势上看,未来数据会发生什么变化,给应用带来什么变化?

首先,我们认为未来数据一定会规模爆炸性增长。2020年全球数据规模约为40 ZB。40 ZB是什么概念?举个例子,假设每部电影是1GB,假设全世界每个人都去看一部电影,那么这些数据量加起来大概就是40ZB。
除此之外,我们预计2025年的全球数据规模将会是2020年的430%,全球数据规模每年都在增长。
第二个是数据生产/处理实时化。原先我们可能一个月看一次报表,经过大数据,我们可以每天看一次昨天的数据。数据越来越实时化,能够实现秒级响应。以营销场景为例,在双十一购物节场景,当商家发现店铺的某个活动不能产生效果,那么可以在一分钟或者数分钟之内调整广告或投放策略,从而达到更好的营销效果。如果数据是按天反馈,在11月12日看到数据的时候,做活动带来的效果已经大大降低了。因此,数据实时化在这样类似的场景中,扮演着十分重要的角色,数据的实时也会带来应用的实时。
第三是数据生产/处理智能化。目前在所有数据中,非结构化数据占比80%,主要包括文本、图形、图像、音频、视频等,尤其是在当下热门的直播领域,对非结构化数据进行智能化处理,能够知道观众的喜好与其他信息,方便业务更好地开展。除此之外,非结构化数据以每年增加55%的速度持续增长,未来将成为数据分析非常重要的一个来源。
第四个是数据加速上云。我们认为数据上云势不可挡,正如汽油车终将被电车代替一样。预计到2025年的时候,数据存储云上规模为49%,2023年数据库上云规模75%。
(四)业界趋势:云计算加速数据库系统演进
另一个业界趋势不容忽略:云计算加速数据库系统演进。
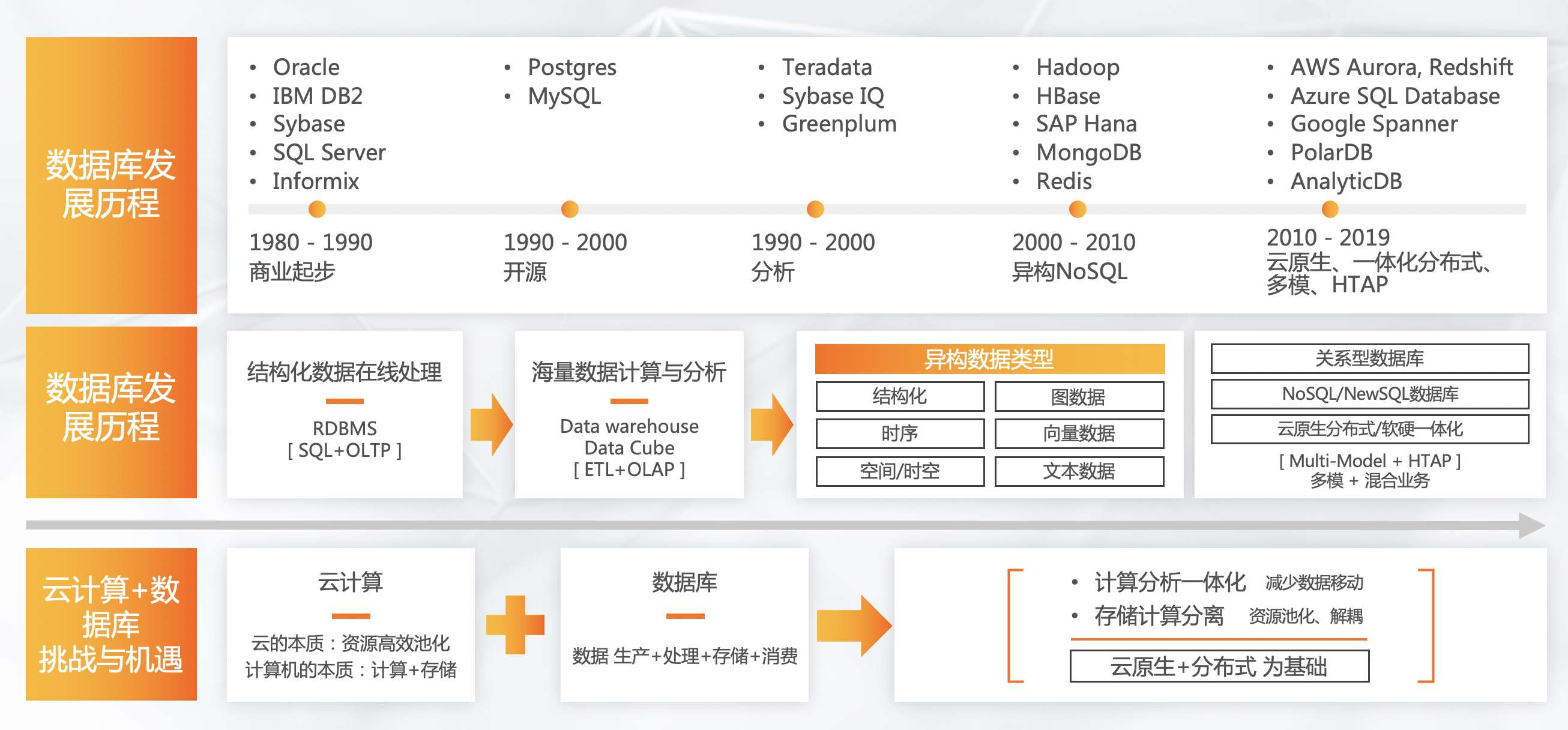
首先我们看一下数据库发展历程。早在八九十年代数据库就已经诞生,那时候主要是商业数据库,如Oracle、IBM DB2等,这里面有些数据库还占据这如今的市场。
到90年代,开源数据库开始涌现,如PostgreSQL、MySQL等。国内用MySQL比较多,国外用PostgreSQL比较多。到90年代以后,数据量越来越大,原来数量小的时候可能用PostgreSQL或MySQL,单机就可以解决问题,随着数据量爆炸性增长,就需要像分布式或小型机的方式去解决大量数据和分析问题。
数据分析的重要性体现在哪里?
举个例子,有个数据仓库Snowflake的公司在刚上市的时候就达到1000亿美金的市值,如今也有700亿美金,对于一个只做一款产品的公司来说,这是一个非常高的市值。为什么它的市值这么高?
前段时间和一位老师交流,他说对于现在的企业,尤其是电商或直播等互联网企业,早先他们企业最大的成本是人力,员工工资占据主要支出。但如今最大的支出是信息和数据,为了公司未来的发展规划,需要拥有大量的数据来分析当前客户最想要什么,最需要什么,业界的发展是什么。因此,公司需要大量购买数据、做大量的数据分析,这方面的成本已经超过了人员成本。这也是为什么一个只做数据仓库的公司,市值能够达到700亿美金。
2000年以后大家开始用Hadoop、Spark,2010年开始出现云原生、一体化分布式等产品,例如AWS、AnalyticDB等。
(五)业界趋势:数据仓库加速从Big Data向 Cloud-Native + Fast Data 演进
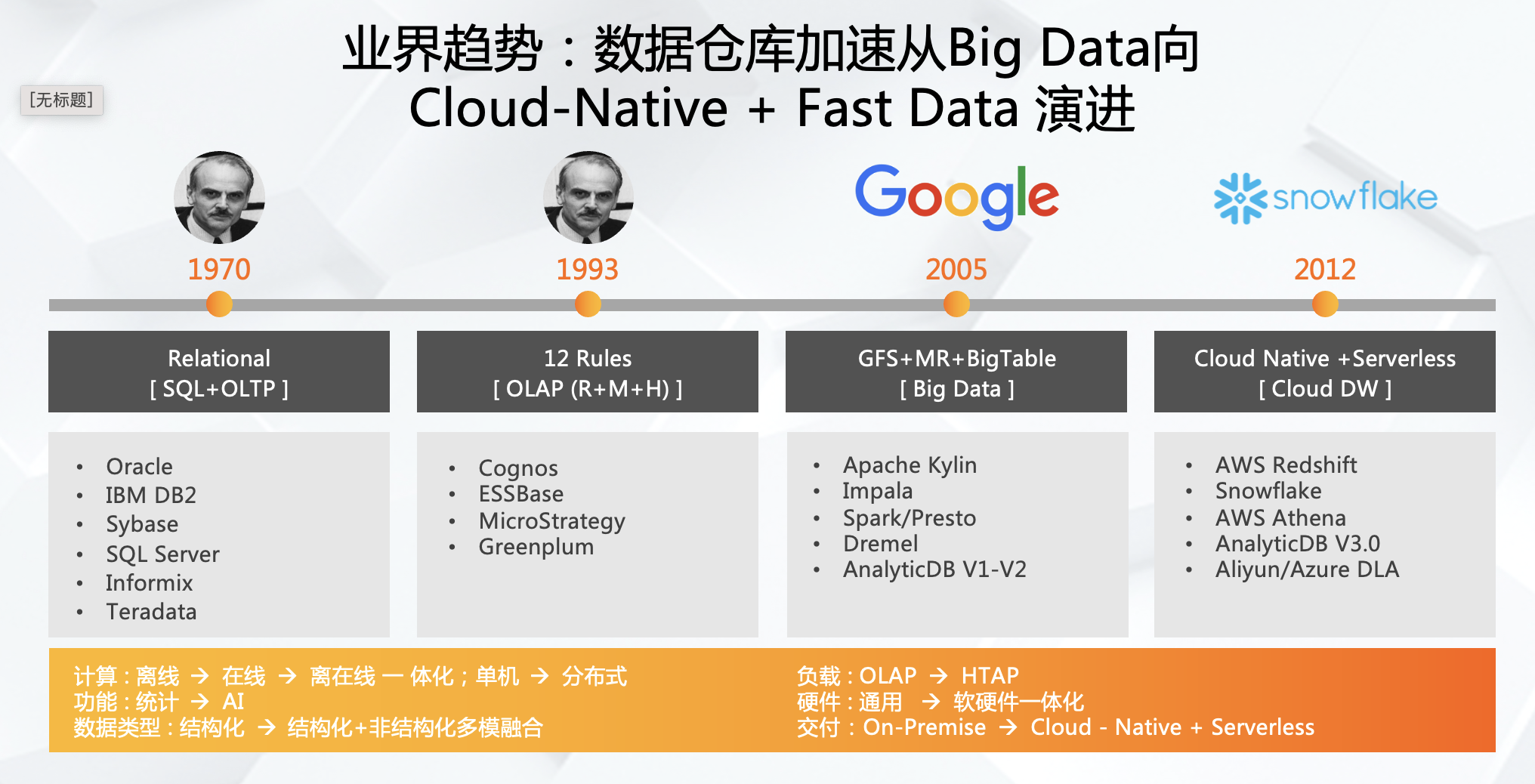
上方是数据仓库的演进历史,计算方式从离线到在线,再到离在线一体化,然后到分布式。功能从统计到AI,数据类型也从结构化到结构化与非结构化多模融合,负载从OLAP到HTAP,硬件也升级为软硬件一体化,交付从On-Premise 到Cloud – Native + Serverless。
在演进的不同进程中,有着各式各样的产品做支撑。
(六)数据库系统架构演进
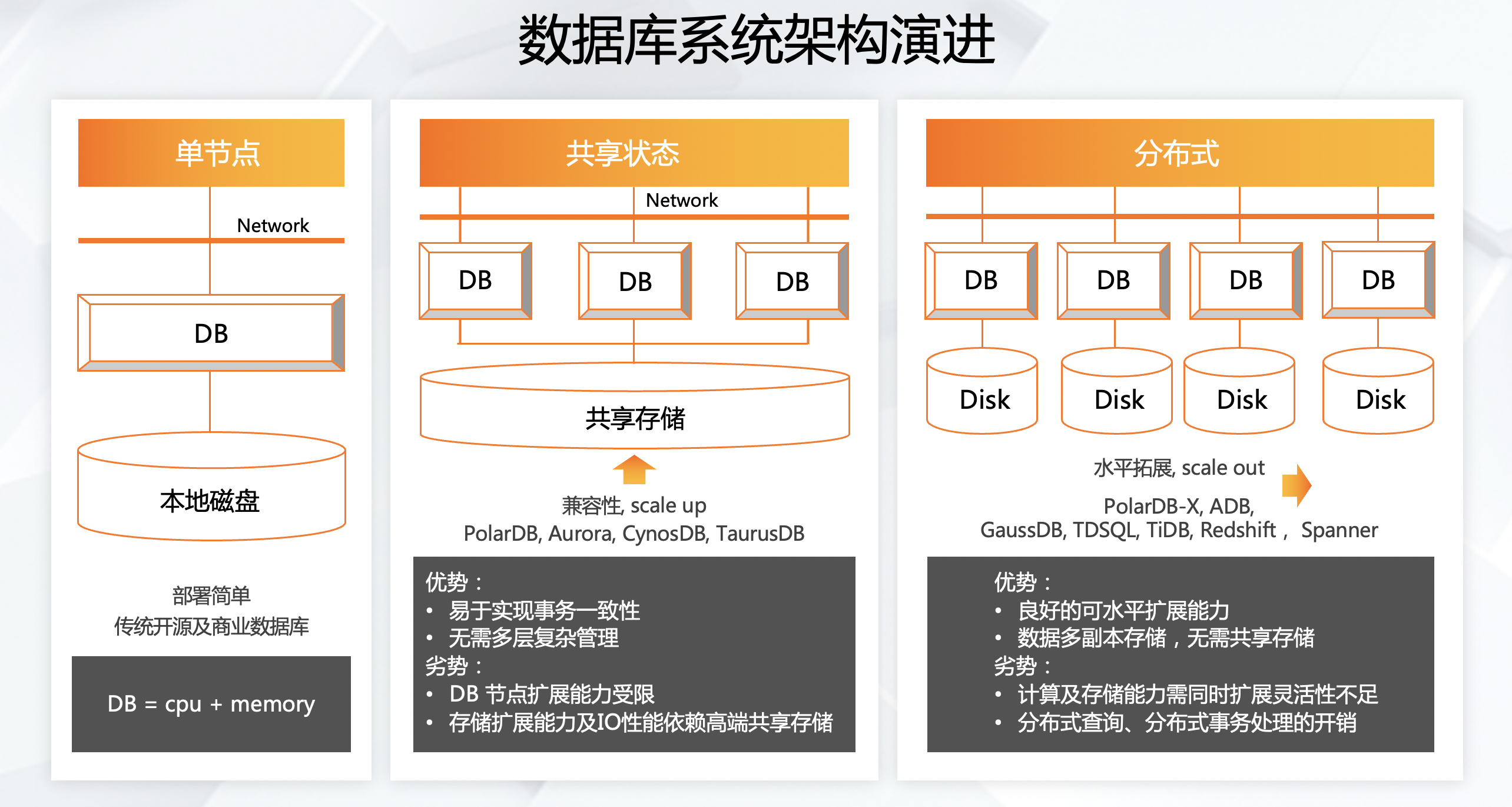
上图为数据库系统架构演进,简单的逻辑可以理解为,原来是一个厂房一个人干活,后来变成一个厂房十个人干活,然后再发展成多个厂房多个人干活,这就是整个数据仓库的发展历史,由原来的单机变成分布式,并且一份数据多个人使用。
数据库的发展也跟人类工作一样,原来有的店夫妻二人就可以维持,一个人负责生产,另一个人负责销售。随着发展,店里的顾客越来越多,店还是一个店,但员工可能有十个人了。再后来,业务发展更多大了,一下招10万个员工,然后在10个场地去干,这就是分布式云原生数据仓库。
(七)业界趋势:云原生数据库关键技术

上方是云原生数据库的关键技术。
这里简单说两个技术,首先是云原生,云原生是什么意思呢?假如某位用户买了个数据库,当业务量少的时候,或者在法定节假日不使用的时候,收费就少,而在业务量大的时候,收费就多一些。按需按量收费,这是我们对数据仓库的一个要求。
另外一个是安全可信,举个例子,阿里巴巴有一个投资部,假如给A公司投了500万,给B公司投了100万,这些信息都是高度私密,不可对外泄露的。假如这些信息是由员工进行管理,员工存在离职的可能,而一旦离职后发生泄密行为,这在法律层面也很难追责。如何让这种高度私密的信息完全加密,使得就算是拥有最高权限的DBA也无法查看这类信息,做到安全可信。后文将对此做详细展开。
二、云原生与大数据应用
(一)业务面临的挑战
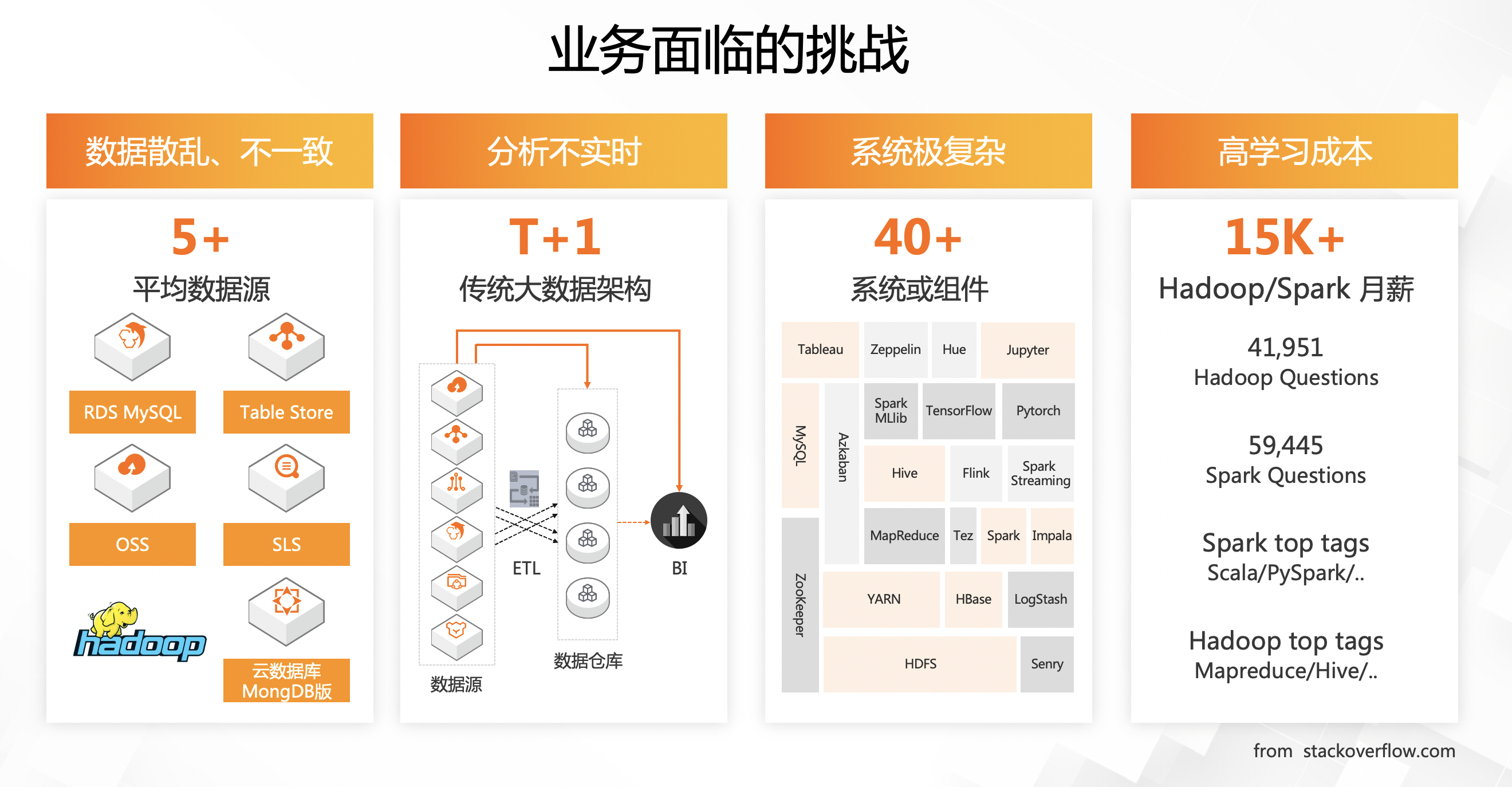
业务面临着许多挑战,主要有四个方面。
首先是数据散乱、不一致,也有非常多的数据源,把数据收集起来是一个很大挑战。
其次是系统极其复杂,系统或组件有40+个。原来可能基于Hadoop,现在需要非常多的系统或组件,底下可能是HDFS,上面是YARN、HBase,再往上还有Hive、Flink等许多东西,非常复杂。
除此之外还有分析不实时,它的数据只能做T+1,是传统大数据架构。
最后是高学习成本,不同技术的版本迭代速度很快,学习成本很高。
(二)云原生数据仓库+云原生数据湖构建新一代数据存储、处理方案
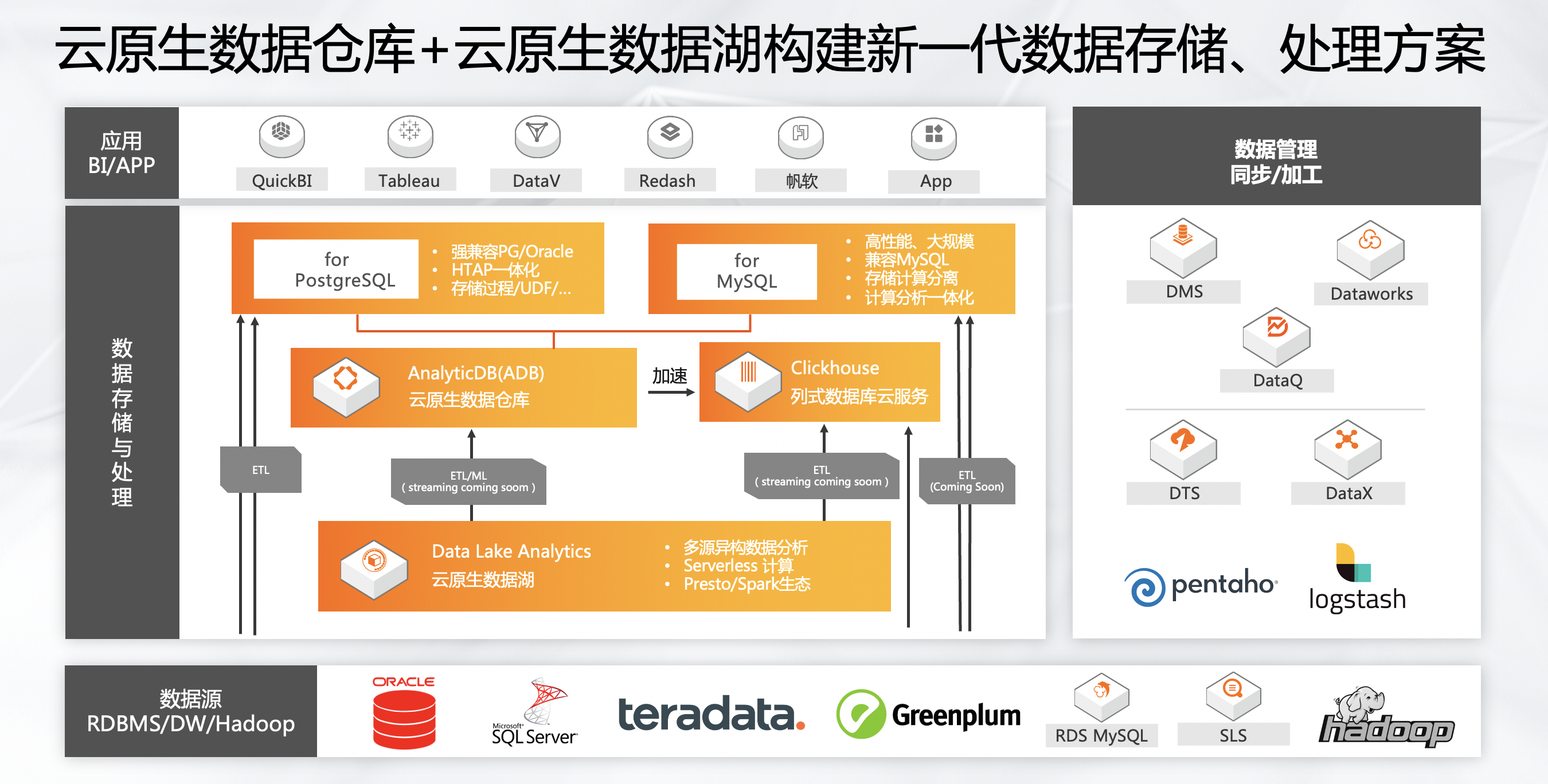
阿里云当时采用的是从一个最简单的架构,通过一个或两个产品就能解决整套产品的架构,能够让用户用得更简单,用SQL就可以解决各种各样的问题。比方原来的OSS数据,各个生产处理的数据大集中分析等。
(三)云原生数据仓库:云原生
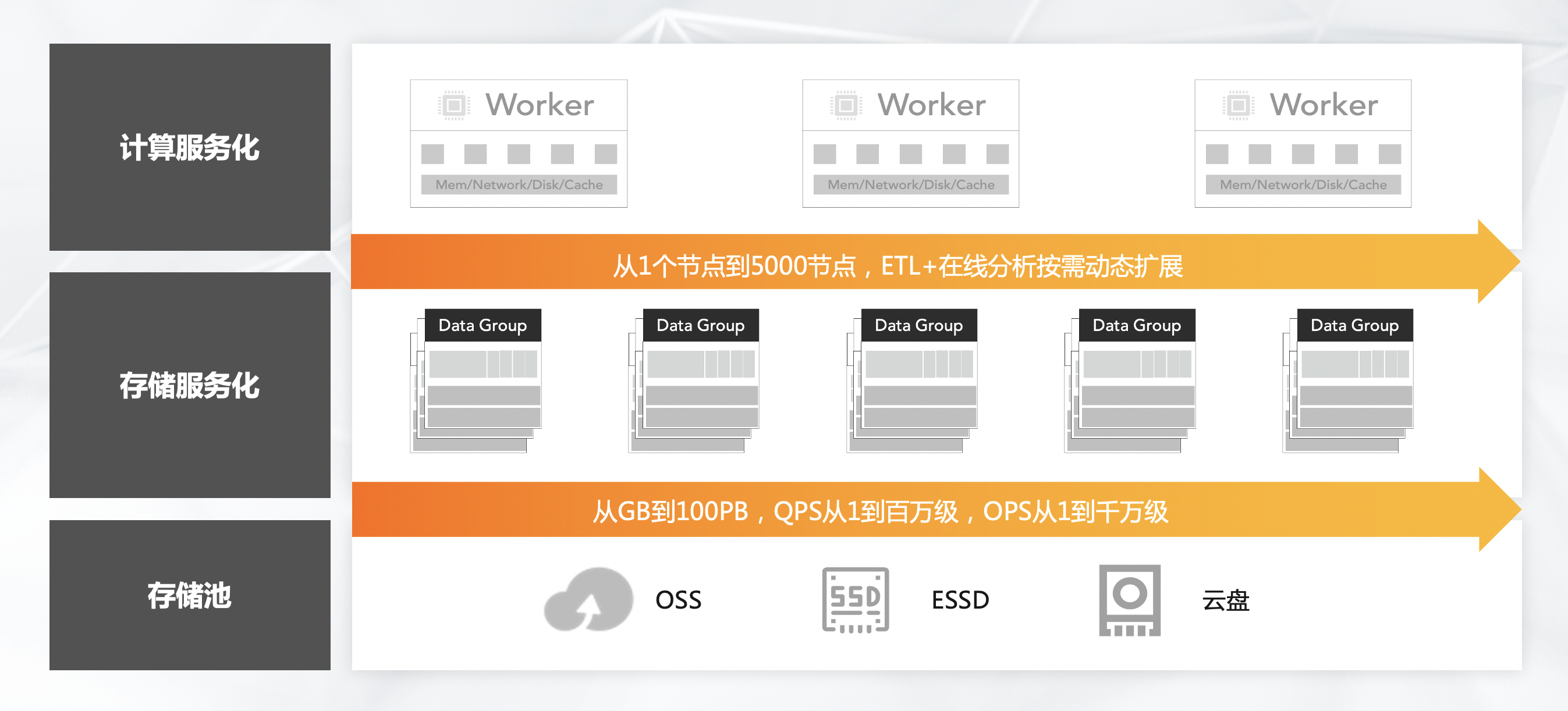
云原生数据仓库的云原生特性主要体现在,如果就一条数据,那么只会分配一条数据的存储,如果数据量增长,它会自动分配更多的存储。
同样的,计算也是这样,如果没有计算需求或者分析需求,它不会分配资源,只有来了需求,才会分配资源进行计算或分析,整个做到按需按量付费,加上资源的弹性。
(四)云原生数据仓库:数据库与大数据一体化
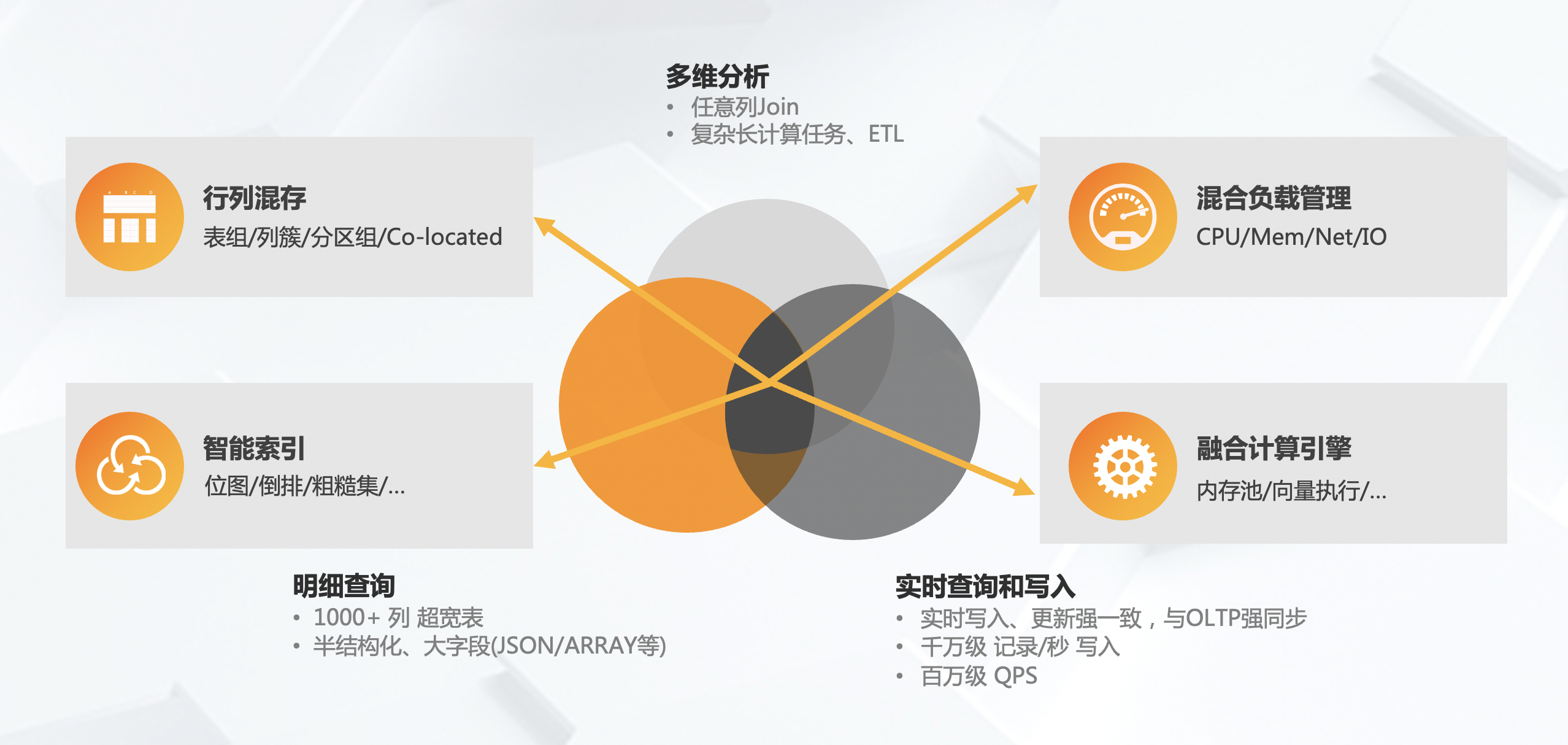
上面是云原生数据仓库中的关键技术,例如行列混存,能够支持高吞吐写入和高并发查询。
其次是混合负载,就是上面既可以跑ETL,又可以做查询。
此外还有智能索引。数据库里面很重要的一个点是需要理解业务,理解Index,要知道什么对查询有影响,什么对写入有影响,所以我们希望这个东西能够做得更智能,让用户不用管理这些东西。
(五)新一代数据仓库解决方案
上方为新一代数据仓库解决方案架构图。最底层是数仓,上面是数仓模型,阿里在淘宝指数,数据洞察等方面做了非常多的模型,包括通过一个ID把所有的信息关联起来。这些信息汇聚成模型。模型上有数据构建管理引擎,可以做数仓规划,代码研发,数据资产管理,数据服务等。
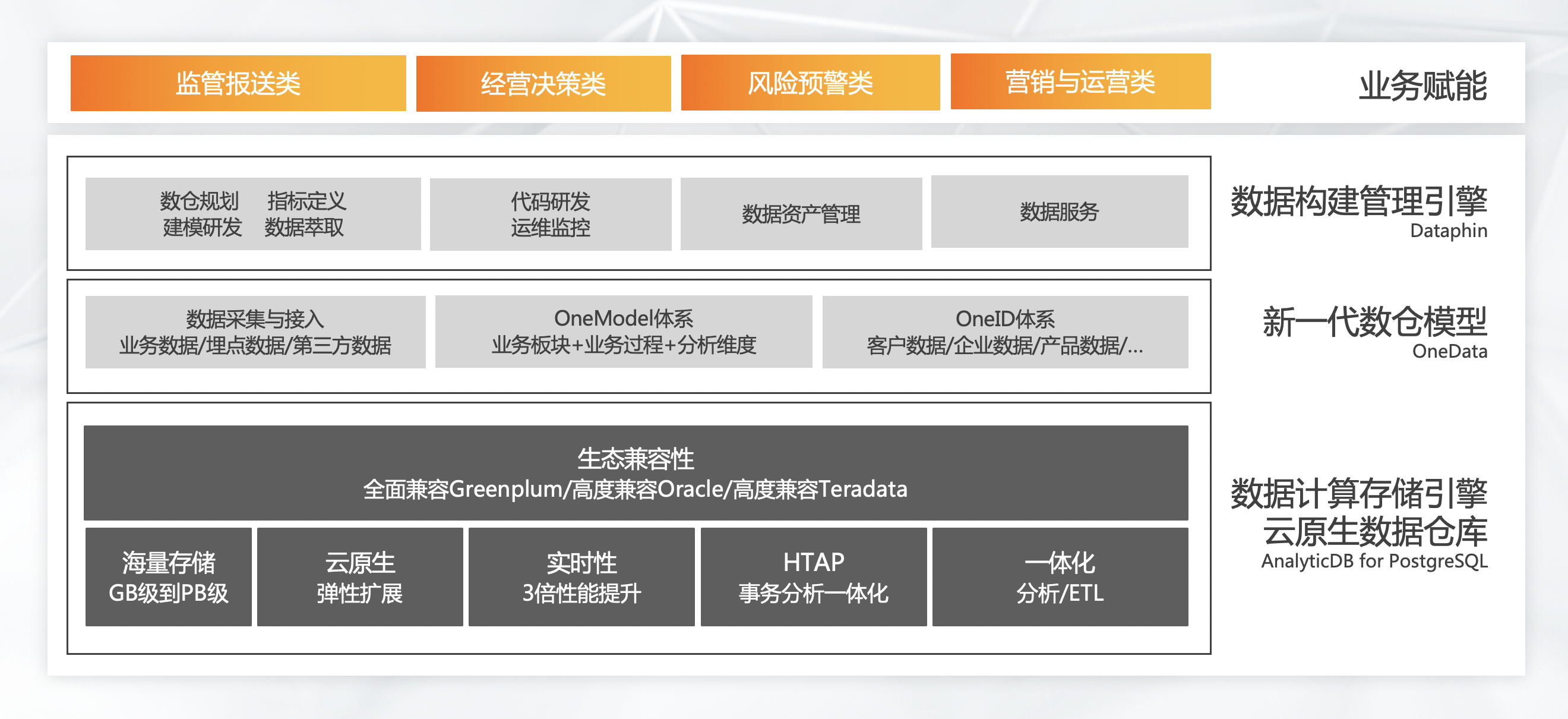
最上面是业务赋能,有许多的应用,包括监管报送类,经营决策类,风险预警类和营销与运营类。
(六)云上数据安全
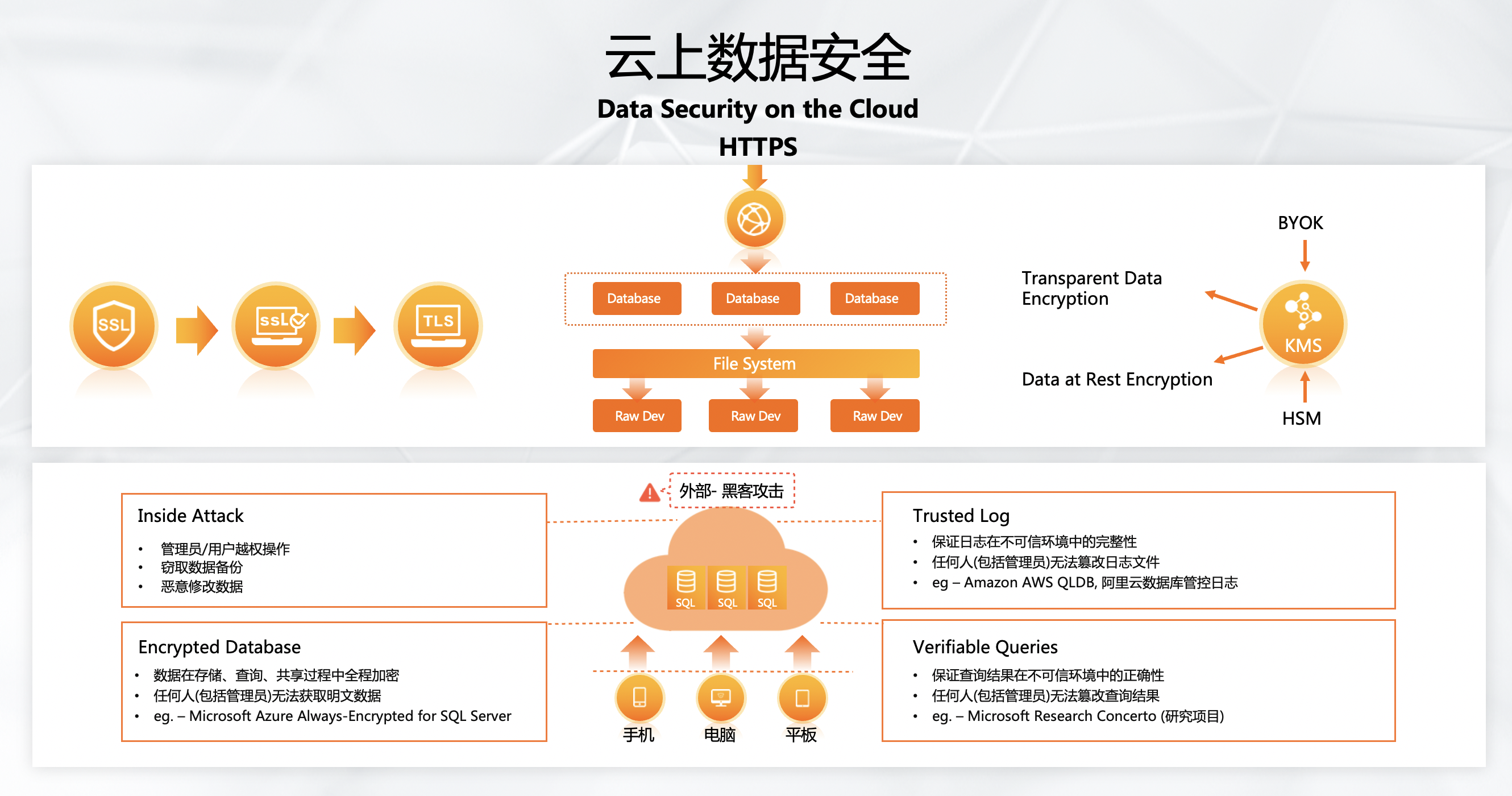
关于云上数据安全的问题,我们展开来讲。每个公司都有绝密的数据,这些数据面临着许多安全问题,例如管理员/用户越权操作,窃取数据备份,恶意修改数据等。除此之外,还有数据在存储、查询、共享过程中全程加密,任何人(包括管理员)无法获取明文数据。保证日志在不可信环境中的完整性,任何人(包括管理员)无法篡改日志文件。保证查询结果在不可信环境中的正确性,任何人(包括管理员)无法篡改查询结果。
以前的解法很简单,就是写到数据库的时候就把数据加密了,例如写进去叫123,通过加密就变成了乱序,如213,312等。这个看似是一个很好的方法,但它有什么问题呢?它没有办法做查询,比方我们要查超过50块钱的交易,但是因为50通过加密以后就不是50了,可能就变成了500,而原来500加密完就是50,因此这个查询无法进行,相当于它变成了一个存储,无法做分析查询。
(七)云端全程加密数据永不泄露

有没有一种方法能让我们做数据分析,同时既能保密,原来的SQL也都能去做?
这里面核心的事情就是我们采用的硬件,通过ApsaraDB RDS(PostgreSQL版)+神龙裸金属服务器(安全芯片TEE技术),可以提前把Key存到里面去,然后所有的计算和逻辑都在加密硬件中进行。由于整个过程受加密硬件保护,即使有人把系统的内存全部复制出来,复制出来的数据也全是加密过的,这就保证运维人员就算拿到绝密数据也没有泄露的风险。
三、最佳实践
下面我们看一下几个最佳实践:
DMP:全链路营销
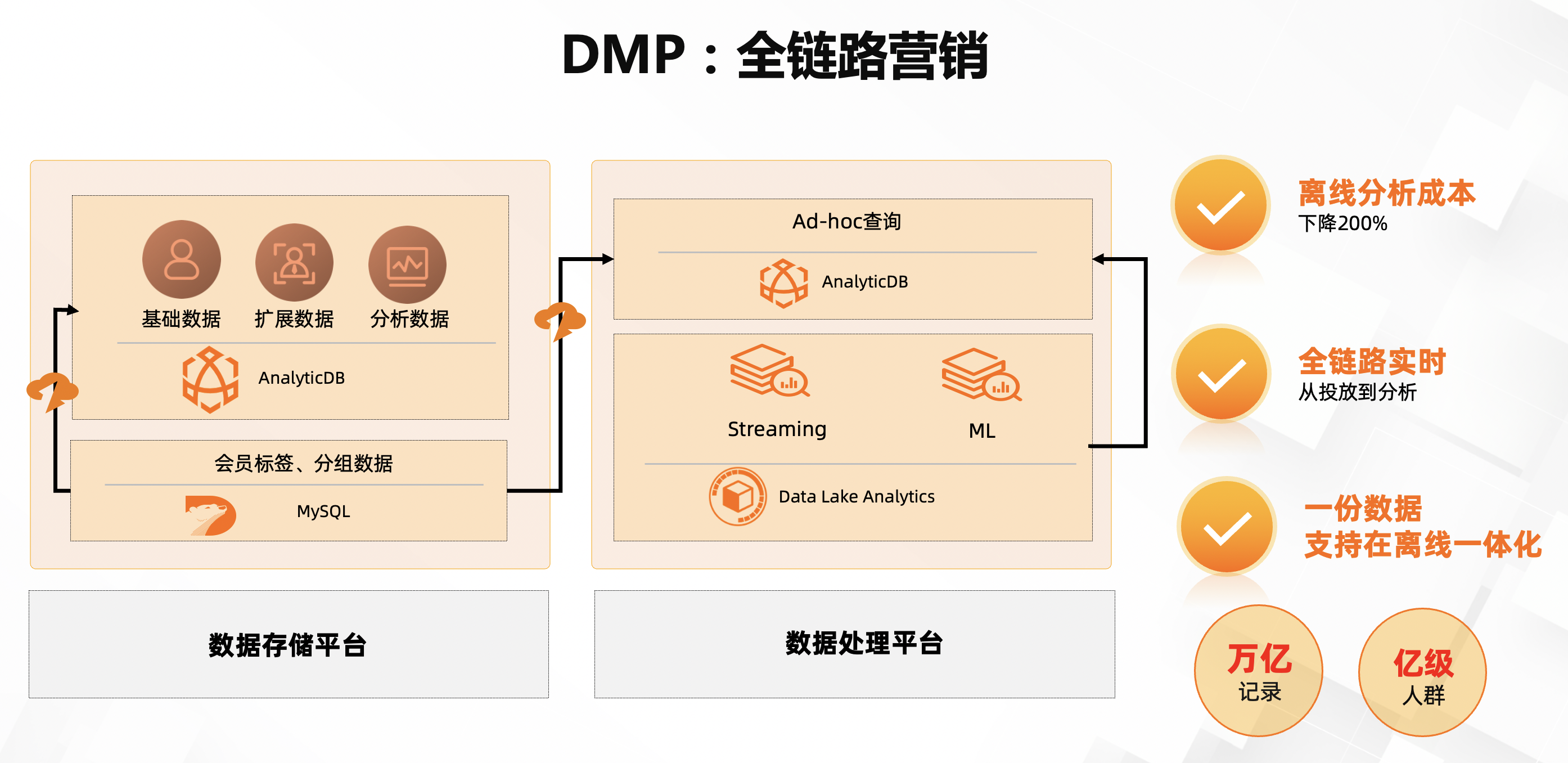
DMP(Data Management Platform)表示数据管理平台,也叫数据营销平台。
营销最核心的事情是什么?营销最核心的事情是找人,找到最关心的一群人,专业词称为圈人。
举个例子,什么场景需要圈人?比如今天我们想找一下对云原生感兴趣的人来一起讨论云原生。把对云原生感兴趣的人找到,这个过程就叫圈人。
还有一种是类似于天猫淘宝报告,例如在双十一前的一段时间,商家认为某位客户今年可能要买个衣服或买一个包,是潜在客户,于是就去给TA推一些消费券等。
这里面最关键的就是精准人群的定位,能够精准地把人群区分出来。中国大概有电商消费人群大概有8亿人,给对某样物品感兴趣的人群推送消息,这里面最核心的就是圈人的事情。
阿里巴巴基于数仓去做圈人的事情,首先去找一些种子人群,这些种子人群数量大概为几百万人,是我们认为的高优质客户,比如每个月在淘宝上花5000块以上或1万块以上的人。把人群全出来后,第二步是将群体进行聚类。
聚类的意思是把几百万人再分成几个小类,每一类里面可能喜欢一个类别,比方这一类喜欢买化妆品,另一类喜欢数码产品,还有一类喜欢买书。划分完小类以后,比如爱买化妆品的可能有10万人,但这10万人可能大部分之前已经买过化妆品了,这次大概率不买了。
因此,我们需要在在8亿消费人群中找到真正可能买化妆品的人,该怎么做呢?
我们需要把每个客户的消费行为和历史购买记录转成AI模型的一个向量,如果有两位客户的购买行为是类似的,那么他们的向量距离就会非常小,这样的话我们的做法就很简单。例如,我们对数码产品感兴趣的人作为种子放到8亿里面去找,跟这些人种子向量距离最近的假如有1000万人,然后对这1000万人去发数码产品的广告或优惠券等,用这种方式去做业务营销。
这个过程最核心的有几个方面。
第一个是将人群进行聚类,把人群划分,知道TA的历史交易,数据必须要能够支持任意维度多维分析。
第二个是能够对整个数仓里面的数据做具体的分析。
第三个是聚类后的向量近似度检索,找出与每个类向量相近的人群进行消息推送。
这就是我们拥有的能力,目前是基于AnalyticDB实现。
还有一个事情是要做Ad-hoc查询。例如,我们要找到对数码感兴趣的人群,,且去年没有买过比如iPhone 12的人,这样他今年才可能买iPhone12。或者说去年买了iPhone12,同时又买了AirPods的人,那我们认为大概率他可能会买苹果的键盘,或者是苹果的电脑等。我们需要对这些人做各种各样的交易查询,从而精准地找到我们的目标人群。
广告精细化管理
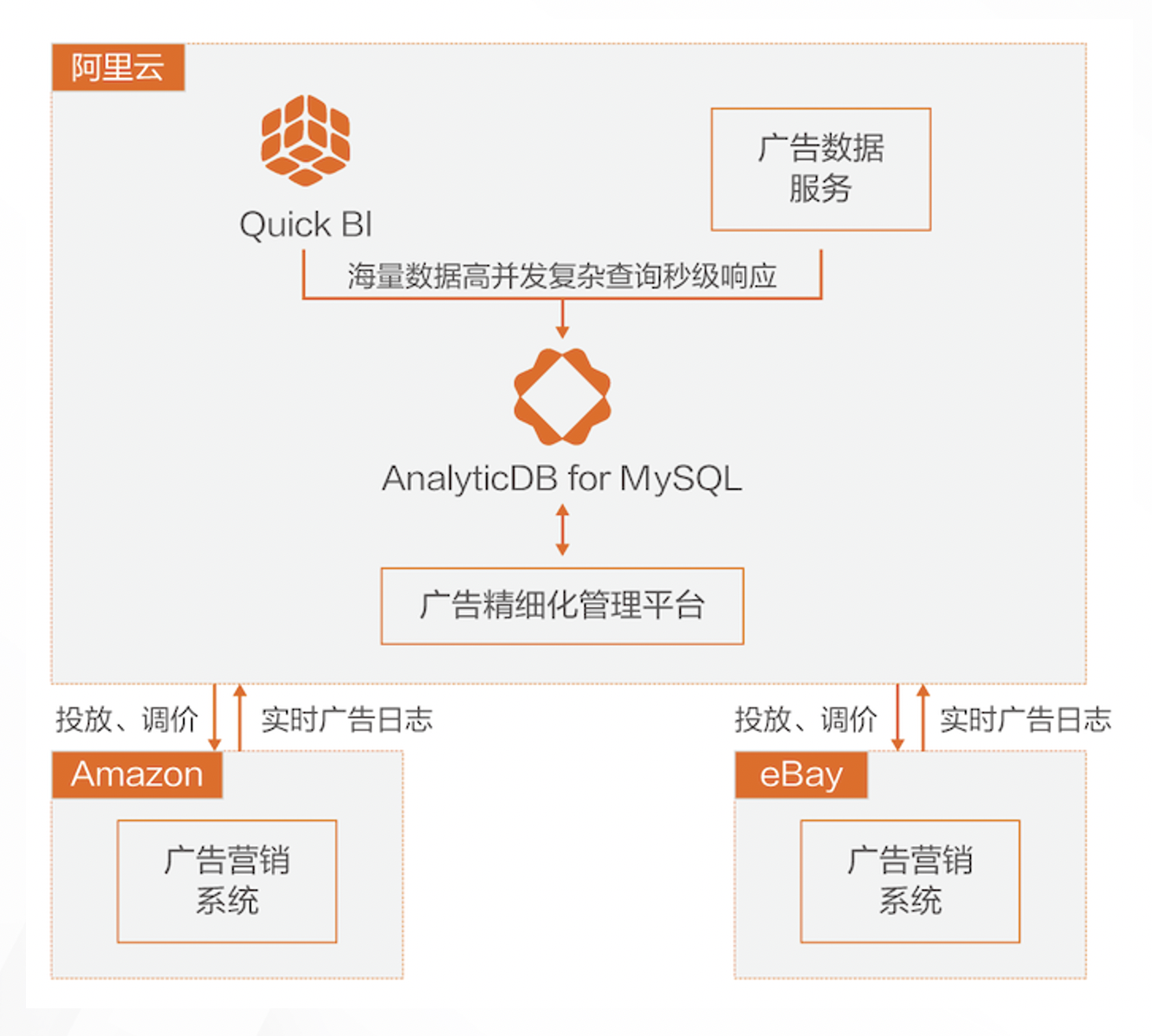
业务挑战:
1)投放关键词搜索事件需要高并发实时入库;
2)所有用户通过仪表板同时查询转化率,复杂查询 QPS高;
3)响应时间要求高,避免错过调价黄金时段。
业务价值:
1)多个站点、多个店铺的关键词统一管理;
2)处理上万TPS并发写;
3)海量数据实时分析,按时段智能调价;
4)键词快速识别分析,最大化收益。
在线电商
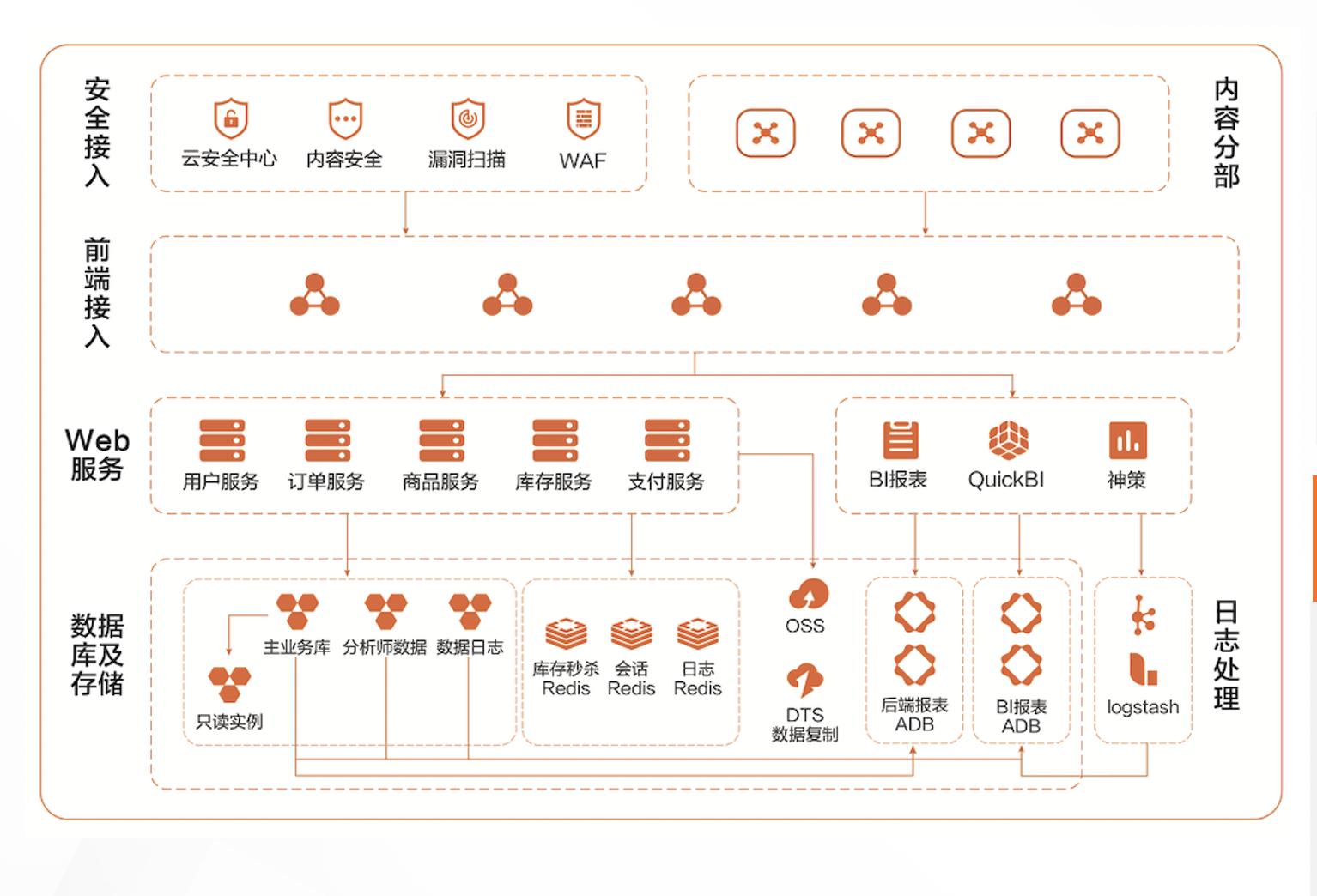
业务挑战:
1)传统MySQL数据库分析满,千万级/亿级复杂报表无法返回;
2)复杂报表秒级返回;
3)兼容MySQL生态;
4)业务发展迅速,对计算存储有不同要求。
业务价值:
1)RDS + AnalyticDB 实现HTAP联合方案,业务和分析隔离;
2)2-10倍分析性能提升;
3)分布式架构,横向扩展,灵活变配,支持数据量和访问量的不同需求
这就是2020年至今,全面升级下一代云原生技术的阶段—-Serverless时代。阿里巴巴成立云原生技术委员会,云原生升级为阿里技术新战略,未来云原生数据仓库还会有更多新功能,为行业解决更核心的痛点,敬请期待。
本文为阿里云原创内容,未经允许不得转载。