自然语言处理一些读书笔记和自己的思考。
在知乎上搜索相关问题,有人推荐《数学之美》,之前粗略看过一次,这次想重新看一下并且做个读书笔记。下面是关于自然语言理解方面的一些读书笔记和自己的思考。
一. 自然语言处理历史:
自然语言处理最初发展的20多年里,相关科学家都极力通过电脑模拟人脑,试图用这种方式来处理人类语言,但是这种方式被证明是行不通的,成功几乎为零。NLP发展的第二阶段是70年代之后,科学家们终于找到了基于数学模型和统计的方法。
第一阶段的时候,学术界对人工智能和自然语言理解的普遍认识是:要让机器完成翻译或者语音识别等等,必须先让计算机理解自然语言,就像人类一样去理解这些语言,这显然是做不到的。即便在可预见的将来,这也必定是一件不太现实的事情。
第二阶段,比如机器在翻译的过程中,并没有理解这句话的意思,它只是做了一种统计上的归纳而已。机器依旧是机器。
基于规则的分析方法,需要将现有的句法系统按照句子成分划分成一个一个单位,而这会随着句子的复杂多样化句子的划分复杂度几何级上升,并且没有上下文的帮助句子词义的多样性同样限制了规则分析方法的发展。比如The pen is in the box.和The box is in the pen.按照规则来分析该句子根本不可能获得语义,必须依靠常识来得到该句子的真正含义,但是基于统计的方法可以依靠上下文对该语义做一个合理的预估。基于规则的方法完全从该单独的句子着手,根本不管上下文。但是这样也还是没有让基于统计的方法快速发展起来,主要原因在于基于统计的方法需要大量的训练数据,这在当时来说是达不到的。
二.统计语言模型:
自然语言逐渐演变成为一种上下文相关的信息表达和传递的方式,计算机就用统计语言模型去表征自然语言这种上下文相关的特性。
一个句子S=(w1,w2,w3…wn)由n个词组成,我们要弄清该句子是否是一个合乎实际的句子,可以计算该句子在现实情况下的概率,最最简单的想法是把人类所有句子统计一遍,然后再计算这个句子的概率,但是这显然是行不通的。一个可行的方法是把这个句子分成n个词(对于中文来说,这就是中文分词研究的东西),然后再计算这n个词按照该顺序组成这个句子的概率大小。可以表示如下:
这个概率计算的复杂度会随着n的增大指数上升。因此引入齐次马尔科夫性假设,即假设一个词的出现只与其前面一个词的出现有关,而与更前面的词无关,这样概率计算可以简化为如下:
这样的模型称为二元模型,用更一般的表示方法为:
但是二元模型显然太过于简单草率,所以有了高阶模型的出现,n阶模型表示一个词的出现与其前面的n-1个词有关。表示为:
一般由于计算复杂度的问题,大多数情况下用3阶模型,谷歌的用到了4阶模型。
接下来的问题是,由于用来训练模型的语料库(corpus)太少而出现的零概率情况如何处理?
这里有一个古德-图灵公式,基本思路是当词语对出现次数大于某一阈值时,利用条件概率计算出来的频率根据大数定理就当做概率(因为只有大于某一阈值时我们才有充分理由相信大数定理的条件被满足),当出现频数小于该阈值但又大于零的频率,则相应的下调该频率值,因为这个时候大数定律成立的条件是没有被满足的,并且出现次数越少,下调频率越多,最后把这个下调的频率当做所求的概率,最后对于零出现的情况,则将这些下调的总和平均分配给零出现的次数,以保证概率总和为1。
三.中文分词问题:
汉语和英语有分割每个词的空格不一样,汉语中所有的词都没有明显分界,所以必须解决中文分词问题,最简单的方法是查字典,基本思想是首先有一个中文词语的字典库,将一个句子从左扫描到末尾,遇到字典里有的词之后就保存,规则是尽量找最长的词,比如中国航天城,中是一个单字词,先保存,继续往下扫描,遇到国字,中和国可以组成一个更长的词,因此最后保存中国这个词,后面的航天城类似。查字典的处理方法简单,但不够准确。因为很多情况下并不是最长词的分词规则就是最适合的。
利用统计语言模型来处理中文分词的第一人是郭进博士,基本思想是:假设一个句子有很多种分词方法,则分别计算每种分词方法对应的该句子概率。即:
也就是说,利用每种分词方法都可以计算该句子的概率。然后取最大概率对应的分词方法。其本质上是一种极大似然估计。
四.关于郭进博士分词方法的一些思考:(求指正)
在这里我添加一些关于极大似然估计和极大后验概率,以及频率学派和贝叶斯学派这方面自己的思考,因为每次好不容易弄清楚了二者联系和区别之后,过段时间又混淆了。
在这里,极大似然估计和极大后验概率都是如下的应用场景:在给定观测数据X的情况下,我们要求解产生该观测数据X背后的参数,并且我们求得的参数并不是非此即彼的,也就是有一个概率分布来表征每一个可能的参数。当然, 一般情况下我们都取概率最大的那个参数,即.
极大似然估计和极大后验概率的关键区别就在第三个等号这里,这也是历史上著名的频率学派和贝叶斯学派争论的地方,焦点就在于是否是一个常数,假如是常量的话,那么第三个等号自然就成立了,这样对于参数的估计就变成了极大似然估计(Maximum Likelihood),假如
不为常量,那么第三个等号就不能成立,对于参数的估计只能停留在倒数第二个式子这里,这便是极大后验概率(Maximum A Posteriori)。
在频率学派的世界里, 参数是常量只是未知。而在贝叶斯学派的世界里,参数则不是常量。双方曾经对这两种观点进行了激烈的争论,这是后话不表。
回到我们这里的问题,给定一个句子,我们要求解其分词组合,实际上给定的这个句子就是我们的观测值,而分词组合便是待求解的参数,而上文说到的清华大学博士郭进所用到的方法便是:先求得每个分词组合下对应的句子概率,把最大概率对应的分词组合作为最终答案。很明显存在如下这个公式:
所以我把这个归为本质上的极大似然估计。
中文分词并不是只能应用在中文领域,而是根据特定场合同样可以应用在字母语言的领域,比如英语词组的分割,手写句子的识别(因为手写英文句子的空格不那么明显)等等。
中文分词已经发展到相当高的阶段,目前只是做一些完善和添加新词的工作,但是也存在一些工程实现方面的取舍问题,主要有两点:
1.分词的一致性,对于同样一个句子,每个人的分词方法不一样,不能说哪种分词方法更优,只能说在具体应用场景里存在一种最优的分词方法;
2.分词的颗粒度问题,和一致性问题一样,不同的应用场景适合用不同的颗粒度,分词器在设计的时候一般会全面兼顾颗粒度小和颗粒度大的情况,在具体问题的时候再进行相应的取舍。
Introduction to Natural Language Processing, Computational Linguistics and
Speech Recognition)
这本书的权威自不用说,译者是冯志伟老师和孙乐老师,当年读这本书的时候,还不知道冯老师是谁,但是读起来感觉非常好,想想如果没有在这个领域积攒多年的实力,是不可能翻译的这么顺畅的。这本书在国内外的评价都比较好,对自然语言处理的两个学派(语言学派和统计学派)所关注的内容都有所包含,但因此也失去一些侧重点。从我的角度来说更偏向于统计部分,所以需要了解统计自然语言处理的读者下面两本书更适合做基础阅读。不过这本书的N-gram语言模型部分写得非常不错,是SRILM的推荐阅读参考。
2、《统计自然语言处理基础》(Foundations of Statistical Natural
Language Processing)
我比较喜欢这本书,这两年的学习过程中也经常拿这本书作为参考,可能与我做统计机器翻译有关吧。看china
pub上的评论说这本书的翻译比较差,自己的感觉是还行。当然,这是国内翻译图书的一个通病:除了很难有翻译的非常好的书外,另外一个原因就是滞后性。如果e文足够好的坏,就及时看英文版吧。这本书在统计基本部分的介绍很不错,另外n元语法部分讲得也比较好,也是SRILM的推荐阅读。
3、《统计自然语言处理》
这是北京自动化所宗成庆老师今年5月出版的一本专著,我有幸较早的阅读了这本书的很多章节。一个很强的感觉是:如果你想了解相关领域的国内外最新进展,这本书非常值得一读。上面两本书在由于出版稍早的缘故,很多领域最新的方法都没有介绍。而这本书刚刚出版,宗老师对国内外现状把握的也比较好,因此书中充分体现了这方面的信息。另外统计机器翻译这一部分写得很详细很不错,这可能与宗老师亦是这个领域的研究者有关吧。
4、《计算机自然语言处理》
这是我最早看的一部自然语言处理方面的书籍,和上面几部大部头的书籍相比,这本书很薄,可以很快的看完。书的内容我都有点忘了,但是印象中可以在每个章节看到国内这个领域的研究历史和相关单位。这时才发现母校HIT在这个领域的超强实力,只是可惜这时候已经离开冰城了。
这些书籍怎么读都行,泛览也罢,精读也行,只要有时间,多读书是没坏处的。我自己的经验是,先泛泛的浏览或阅读一篇,对于比较晦涩的部分可以先跳过去,然后对自己感兴趣的领域或者将要从事的领域的相关章节进行精读,当然,书籍一般在开始的几个章节讲些基础性的知识,这部分最好也仔细揣摩一下。真正要对自己研究的领域深刻了解,还得好好读一下本领域的相关论文。
个人觉得NLP如果不是做学术研究钻算法的,其实很多艰深的著作看过不用的话过段时间就忘,而且容易丧失兴趣。说到最快入门的话,分情况讨论:
1 手头有个项目,需要快速自学完成。举个例子,比如接到任务要做一个sentiment analysis的系统。先去网上,CSDN,博客园,知乎,quora,等等,找一篇该主题的入门引导教程,看看有什么入门级读物,经典论文可以看,先把这些基础资料过一遍,比如对于sentiment analysis,一般很快就会找到一本Bing Liu写的一百多页的小册子,很入门。然后看见基础入门材料的过程中,看到有算法有包可以用都记下来,一个个试。看完这些基本就知道项目怎么做了,如果对现有的包不满意,觉得自己写会更好,就按着你的思路钻算法的本质,充分利用楼上大佬们推荐的经典教材,找到相关的部分看,搞懂了之后自己写。这时候,你对这个领域就算是入门了。
2 手头没有项目,纯想学NLP这个技能,比如找工作想多点些技能树。这种情况下,去找个项目做,比如kaggle,codeproject等,或者github上贡献代码。活儿揽下来后,按1中的步骤走。
3 理论派,兴趣在于算法,纯希望了解NLP的算法在数学上是怎么work的。这种情况,数学好时间足的话直接找本大佬们推荐的教材开始看,不然的话找一个好的入门课程,然而印象中在coursera上好像没怎么发现过,但可以推荐CMU的LTI开的algorithms for NLP,网上应该找得到这个课的公共主页,上面有课件。不过看懂这个课也是需要数学基础的。按着这个课件把主要的topic都cover一遍,想看深一点的就到推荐的经典教材里去找来看。
链接:https://www.zhihu.com/question/19895141/answer/100991969
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
说说自己的历程吧。
我是一名非科班的自然语言,机器学习,数据挖掘关注者。
因工作关系,5年前需要做与自然语言处理的项目。当时的项目老大先是扔给我一本书《统计自然语言处理》,直接给我看蒙了。不能说一点都不懂,但是看的云里雾里,不知道get几层。
但看这本书的过程中,我狂搜了些自然语言处理的课件,有北大的,中科院的,都写的很好,从语言模型开始。从分词,标注,语法树,语意等等。也大体知道自然语言处理,分词法,语法,语义。然后是各种应用,信息检索,机器翻译等自然语言经典应用问题。
断断续续做了些小项目,基于语言模型的拼音输入法,仿照sun\’pinyin写的,他们的blog写的很详细,从模型建模,到平滑处理,很详细,我也用python实现了一遍,当时这个输入法配合上一个简单的ui还在部门内部推广了,搞了个基于云的拼音输入法,获得个小奖品,很是洋洋得意。这个过程中,我看着sunpinyin的blog, https://code.google.com/archive/p/sunpinyin/wikis, 回过头又去看课件,去了解很细节的问题,如拉普拉斯平滑,回退平滑的细节等,收获很多。
后来老大告诉我,看自然语言问题时,可以找博士论文先看,因为博士论文一般都会来龙去脉讲的非常详细,看完一遍之后基本上这个问题就了解的差不多,然后就是follow业界的进度,那就是关注各种会议和期考,可自行百度和谷歌。
搞好这个拼音输入法,进入实际项目,做一套中文自然语言的基础处理引擎,好在不是让我一个人来,公司开始找大学合作,我做企业项目负责跟进的,大学负责具体算法,我跟着自己调查分词标注算法,了解了有基于词典的,语言模型的,hmm,crf的,那个crf的,我始终搞不大明白,后来先了解了hmm的vertbe算法,em算法,大学的博士给我讲了一遍crf,终于豁然开朗。还把解码过程写到了http://52nlp.cn上,关注的人还可以。从那以后我感觉我就真入门了。在来一个什么问题,我基本上也有套路来学习和研究了。
总结下,
1.先各种课件,加那本自然语言的书,搞清楚自然语言大概都有哪些问题,主要是为了解决什么问题的。
2.基于某个问题看博士论文,了解来龙去脉。然后follow业界进度。
3.找各种资源,会议的,期刊的,博客http://52nlp.cn(不是打广告,我不是博主,不过博客真心不错)
4.微博上关注各种这个领域的大牛,他们有时候会推荐很多有用的资料。
当然,数学之美 我也读了,确实不错。
链接:https://www.zhihu.com/question/19895141/answer/167512928
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
大家回答的都挺不错了,只好来强答。
一、独立实现一个小型的自然语言处理项目。
要找一个合适的的自然语言处理相关的开源项目。这个项目可以是与自己工作相关的,也可以是自己感兴趣的。项目不要太大,以小型的算法模块为佳,这样便于独立实现。像文本领域的文本分类、分词等项目就是比较合适的项目。 运行程序得到项目所声称的结果。然后看懂程序,这期间一般需要阅读程序实现所参考的文献。最后,自己尝试独立实现该算法,得到与示例程序相同的结果。再进一步的,可以调试参数,了解各参数对效果的影响,看是否能得到性能更好的参数组合。
这一阶段主要是学习快速上手一个项目,从而对自然语言处理的项目有比较感性的认识——大体了解自然语言处理算法的原理、实现流程等。
当我们对自然语言处理项目有了一定的认识之后,接下来就要深入进去。任何自然语言处理应用都包含算法和所要解决的问题两方面,要想深入进去就需要从这两方面进行着手。
二、对问题进行深入认识
对问题的深入认识通常来源于两个方面,一是阅读当前领域的文献,尤其是综述性的文献,理解当前领域所面临的主要问题、已有的解决方案有哪些、有待解决的问题有哪些。这里值得一提的是,博士生论文的相关文献介绍部分通常会对本问题做比较详细的介绍,也是比较好的综述类材料。
除了从文献中获取对问题的认识外,另一种对问题进行深入认识的直观方法就是对算法得出的结果进行bad case分析,总结提炼出一些共性的问题。对bad case进行分析还有一个好处,可以帮助我们了解哪些问题是主要问题,哪些问题是次要问题,从而可以帮助我们建立问题优先级。如果有具体任务的真实数据,一定要在真实数据上进行测试。这是因为,即使是相同的算法,在不同的数据集上,所得到的结果也可能相差很大。
三、对算法进行深入理解
除了具体的问题分析,对算法的理解是学习人工智能必须要过的关。经过这么多年的发展,机器学习、模式识别的算法已经多如牛毛。幸运的是,这方面已经有不少好的书籍可供参考。这里推荐华为李航的蓝宝书《统计学习方法》和周志华的西瓜书《机器学习》,这两本都是国内顶级的机器学习专家撰写的书籍,思路清晰,行文流畅,样例丰富。
如果觉得教科书稍感乏味,那我推荐吴军的《数学之美》,这是一本入门级的科普读物,作者以生动有趣的方式,深入浅出的讲解了很多人工智能领域的算法,相信你一定会有兴趣。
国外的书籍《Pattern Recognition and Machine Learning》主要从概率的角度解释机器学习的各种算法,也是不可多得的入门教材。如果要了解最新的深度学习的相关算法,可以阅读被誉为深度学习三架马车之一Bengio所著的《Deep Learning》。 在学习教材时,对于应用工程师来说,重要的是理解算法的原理,从而掌握什么数据情况下适合什么样的数据,以及参数的意义是什么。
四、深入到领域前沿
自然语言处理领域一直处在快速的发展变化当中,不管是综述类文章还是书籍,都不能反映当前领域的最新进展。如果要进一步的了解领域前沿,那就需要关注国际顶级会议上的最新论文了。下面是各个领域的一些顶级会议。这里值得一提的是,和其他人工智能领域类似,自然语言处理领域最主要的学术交流方式就会议论文,这和其他领域比如数学、化学、物理等传统领域都不太一样,这些领域通常都以期刊论文作为最主要的交流方式。 但是期刊论文审稿周期太长,好的期刊,通常都要两三年的时间才能发表,这完全满足不了日新月异的人工智能领域的发展需求,因此,大家都会倾向于在审稿周期更短的会议上尽快发表自己的论文。 这里列举了国际和国内文本领域的一些会议,以及官网,大家可以自行查看。
国际上的文本领域会议:
ACL:http://acl2017.org/ 加拿大温哥华 7.30-8.4
EMNLP:http://emnlp2017.net/ 丹麦哥本哈根 9.7-9.11
COLING:没找到2017年的
国内会议:
CCKS http://www.ccks2017.com/index.php/att/ 成都 8月26-8月29
SMP http://www.cips-smp.org/smp2017/ 北京 9.14-9.17
CCL http://www.cips-cl.org:8080/CCL2017/home.html 南京 10.13-10.15
NLPCC http://tcci.ccf.org.cn/conference/2017/ 大连 11.8-11.12
NCMMSC http://www.ncmmsc2017.org/index.html 连云港 11.11 - 11.13
像paperweekly,机器学习研究会,深度学习大讲堂等微信公众号,也经常会探讨一些自然语言处理的最新论文,是不错的中文资料。
五、当然,工欲善其事,必先利其器。我们要做好自然语言处理的项目,还需要熟练掌握至少一门工具。当前,深度学习相关的工具已经比较多了,比如:tensorflow、mxnet、caffe、theano、cntk等。这里向大家推荐tensorflow,自从google推出之后,tensorflow几乎成为最流行的深度学习工具。究其原因,除了google的大力宣传之外,tensorflow秉承了google开源项目的一贯风格,社区力量比较活跃,目前github上有相当多数量的以tensorflow为工具的项目,这对于开发者来说是相当大的资源。
以上就是对于没有自然语言处理项目经验的人来说,如何学习自然语言处理的一些经验,希望对大家能有所帮助。
链接:https://www.zhihu.com/question/19895141/answer/35482496
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不请自来,语言学背景,研二。废话不说,直接上货。
书籍篇:
入门书籍挺多的,我也看过不少。
1)《数学之美》(吴军)
这是我看的第一本关于NLP的书。现在第二版出来了,貌似新增了两章内容,还没看过。第一版写的挺好,科普性质。看完对于nlp的许多技术原理都有了一点初步认识。现在没事还会翻翻的。
2)《自然语言处理简明教程》(冯志伟)
冯志伟老师这本书,偏向于语言学,书略厚。关于语言学的东西很多。都是很容易理解的东西。建议没有学过理工科们翻一翻,毕竟nlp这东西未来趋势可能会融合不少语言学的东西。
3)《自然语言处理综论》(Daniel Jurafsky)
这本书也是冯志伟老师翻译的,翻译的挺棒,看了差不多一半。综论性质的,选感兴趣的章节翻翻就行。作者是Daniel Jurafsky,在coursera上面有他的课程,后面视频篇里集中谈。
4)《自然语言处理的形式模型》(冯志伟)
这本书还是冯志伟老师写的。很佩服冯志伟老师,文理兼修,而且都很厉害。内容许多是从他以前的著作里面摘取的。算是一本各种语言模型和统计模型的大集合吧。放在桌面,没事翻翻也能是极好的。
5)《统计自然语言处理(第2版)》(宗成庆)
这本书我觉得写的不错。虽然我是语言学背景,但读起来也没有太吃力。它也是综论性质的,可以跳着看。
6)《统计学习方法》(李航)
自然语言处理需要些机器学习的知识。我数学基础还是太薄弱,有的内容还是有些吃力和困惑的。
7)《机器学习实战》哈林顿 (Peter Harrington)
《Python自然语言处理》
《集体智慧编程》
这些书都是python相关的。中间那本就是将NLTK的。网上都有电子版,需要的时候翻一番看一看就行。
视频篇:
上面提到的,斯坦福的nlp课程Video Listing,哥伦比亚大学的https://class.coursera.org/nlangp-001,两个都是英文的,无中文字幕,现在还可以下载视频和课件。
另外超星学术视频:
1)自然语言理解_宗成庆
我觉得讲的还是不错的,第一次听的时候有些晕乎。该课程网上有ppt讲义。讲义后来被作者写成了书,就是上面提到的《统计自然语言处理》。拿着书就是教材,还有课程ppt和视频可以看,这种感觉还是很好的。
2)自然语言处理_关毅
感觉讲的一般,听了几节,跳跃太多,有时候让人摸不着头脑。多听听还是很有益处的吧。
3)计算语言学概论_侯敏
这个就是语言学内容为主了,作者也是语言学背景下在nlp比较活跃的。讲的很浅。老师讲课很啰嗦,说话太慢,我都是加速看的。
4)计算语言学_冯志伟
冯志伟老师这个课,一如他的著作,语言学和统计都会涉及到一些。冯志伟老师说话有些地方听不大清,要是有字幕就好了。
5)语法分析_陆俭明
这是纯语言学的课程。陆剑明也是当代语言学的大师。我觉得既然是自然语言处理,语言学的东西,还是多少要了解的。
其他篇:
1)博客的话,我爱自然语言处理专门记录nlp的,很不错,再有就是csdn上一些比较琐碎的了。
2)北京大学中文系 应用语言学专业这个刚开始的时候也看了看,又不少干货。
3)《中文信息学报》说这个,不会被大神喷吧。英语不佳,英文文献实在看的少。这个学报,也是挑着看看就行。
好像就是这些内容了。如果有,日后再补。
虽然自己写了这么多,但不少书和视频都没有完整的看完。现在水平仍很菜,仍在进阶的路上。希望各路大神多多指点,该拍砖就拍吧。
链接:https://www.zhihu.com/question/19895141/answer/20084186
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
接下来说,《统计自然语言处理基础》这本书,这书实在是太老了,但是也很经典,看不看随意了。
现在自然语言处理都要靠统计学知识,所以我十分十分推荐《统计学习方法》,李航的。李航老师用自己课余时间7年写的,而且有博士生Review的。自然语言处理和机器学习不同,机器学习依靠的更多是严谨的数学知识以及推倒,去创造一个又一个机器学习算法。而自然语言处理是把那些机器学习大牛们创造出来的东西当Tool使用。所以入门也只是需要涉猎而已,把每个模型原理看看,不一定细致到推倒。
宗成庆老师 的统计自然语言处理第二版非常好~《中文信息处理丛书:统计自然语言处理(第2版)》 蓝色皮的~~~
然后就是Stanford公开课了,Stanford公开课要求一定的英语水平。| Coursera 我觉得讲的比大量的中国老师好~
举例:
http://www.ark.cs.cmu.edu/LS2/in…
或者
http://www.stanford.edu/class/cs…
如果做工程前先搜索有没有已经做好的工具,不要自己从头来。做学术前也要好好的Survey!
开始推荐工具包:
中文的显然是哈工大开源的那个工具包 LTP (Language Technology Platform) developed by HIT-SCIR(哈尔滨工业大学社会计算与信息检索研究中心).
英文的(python):
- pattern – simpler to get started than NLTK
- chardet – character encoding detection
- pyenchant – easy access to dictionaries
- scikit-learn – has support for text classification
- unidecode – because ascii is much easier to deal with
希望可以掌握以下的几个tool:
CRF++
GIZA
Word2Vec
还记得小时候看过的数码宝贝,每个萌萌哒的数码宝贝都会因为主人身上发生的一些事情而获得进化能力,其实在自然语言处理领域我觉得一切也是这样~ 我简单的按照自己的见解总结了每个阶段的特征,以及提高的解决方案
1.幼年体——自然语言处理好屌,我什么都不会但是好想提高
建议。。。去看公开课~去做Kaggle的那个情感分析题。
2.成长期——觉得简单模型太Naive,高大上的才是最好的
这个阶段需要自己动手实现一些高级算法,或者说常用算法,比如LDA,比如SVM,比如逻辑斯蒂回归。并且拥抱Kaggle,知道trick在这个领域的重要性。
3.成熟期——高大上的都不work,通过特征工程加规则才work
大部分人应该都在这个级别吧,包括我自己,我总是想进化,但积累还是不够。觉得高大上的模型都是一些人为了paper写的,真正的土方法才是重剑无锋,大巧不工。在这个阶段,应该就是不断读论文,不断看各种模型变种吧,什么句子相似度计算word2vec cosine已经不再适合你了。
4.完全体——在公开数据集上,把某个高大上的模型做work了~
这类应该只有少数博士可以做到吧,我已经不知道到了这个水平再怎么提高了~是不是只能说不忘初心,方得始终。
5.究极体——参见Micheal Jordan Andrew Ng.
好好锻炼身体,保持更长久的究极体形态
希望可以理解自然语言处理的基本架构~:分词=>词性标注=>Parser
Quora上推荐的NLP的论文(摘自Quora 我过一阵会翻译括号里面的解释):
Parsing(句法结构分析~语言学知识多,会比较枯燥)
- Klein & Manning: “Accurate Unlexicalized Parsing” ( )
- Klein & Manning: “Corpus-Based Induction of Syntactic Structure: Models of Dependency and Constituency” (革命性的用非监督学习的方法做了parser)
- Nivre “Deterministic Dependency Parsing of English Text” (shows that deterministic parsing actually works quite well)
- McDonald et al. “Non-Projective Dependency Parsing using Spanning-Tree Algorithms” (the other main method of dependency parsing, MST parsing)
Machine Translation(机器翻译,如果不做机器翻译就可以跳过了,不过翻译模型在其他领域也有应用)
- Knight “A statistical MT tutorial workbook” (easy to understand, use instead of the original Brown paper)
- Och “The Alignment-Template Approach to Statistical Machine Translation” (foundations of phrase based systems)
- Wu “Inversion Transduction Grammars and the Bilingual Parsing of Parallel Corpora” (arguably the first realistic method for biparsing, which is used in many systems)
- Chiang “Hierarchical Phrase-Based Translation” (significantly improves accuracy by allowing for gappy phrases)
Language Modeling (语言模型)
- Goodman “A bit of progress in language modeling” (describes just about everything related to n-gram language models 这是一个survey,这个survey写了几乎所有和n-gram有关的东西,包括平滑 聚类)
- Teh “A Bayesian interpretation of Interpolated Kneser-Ney” (shows how to get state-of-the art accuracy in a Bayesian framework, opening the path for other applications)
Machine Learning for NLP
- Sutton & McCallum “An introduction to conditional random fields for relational learning” (CRF实在是在NLP中太好用了!!!!!而且我们大家都知道有很多现成的tool实现这个,而这个就是一个很简单的论文讲述CRF的,不过其实还是蛮数学= =。。。)
- Knight “Bayesian Inference with Tears” (explains the general idea of bayesian techniques quite well)
- Berg-Kirkpatrick et al. “Painless Unsupervised Learning with Features” (this is from this year and thus a bit of a gamble, but this has the potential to bring the power of discriminative methods to unsupervised learning)
Information Extraction
- Hearst. Automatic Acquisition of Hyponyms from Large Text Corpora. COLING 1992. (The very first paper for all the bootstrapping methods for NLP. It is a hypothetical work in a sense that it doesn\’t give experimental results, but it influenced it\’s followers a lot.)
- Collins and Singer. Unsupervised Models for Named Entity Classification. EMNLP 1999. (It applies several variants of co-training like IE methods to NER task and gives the motivation why they did so. Students can learn the logic from this work for writing a good research paper in NLP.)
Computational Semantics
- Gildea and Jurafsky. Automatic Labeling of Semantic Roles. Computational Linguistics 2002. (It opened up the trends in NLP for semantic role labeling, followed by several CoNLL shared tasks dedicated for SRL. It shows how linguistics and engineering can collaborate with each other. It has a shorter version in ACL 2000.)
- Pantel and Lin. Discovering Word Senses from Text. KDD 2002. (Supervised WSD has been explored a lot in the early 00\’s thanks to the senseval workshop, but a few system actually benefits from WSD because manually crafted sense mappings are hard to obtain. These days we see a lot of evidence that unsupervised clustering improves NLP tasks such as NER, parsing, SRL, etc,
其实我相信,大家更感兴趣的是上层的一些应用~而不是如何实现分词,如何实现命名实体识别等等。而且应该大家更对信息检索感兴趣。不过自然语言处理和信息检索还是有所区别的,So~~~我就不在这边写啦
链接:https://www.zhihu.com/question/19895141/answer/24710071
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
昨天实验室一位刚进组的同学发邮件来问我如何查找学术论文,这让我想起自己刚读研究生时茫然四顾的情形:看着学长们高谈阔论领域动态,却不知如何入门。经过研究生几年的耳濡目染,现在终于能自信地知道去哪儿了解最新科研动态了。我想这可能是初学者们共通的困惑,与其只告诉一个人知道,不如将这些Folk Knowledge写下来,来减少更多人的麻烦吧。当然,这个总结不过是一家之谈,只盼有人能从中获得一点点益处,受个人认知所限,难免挂一漏万,还望大家海涵指正。
1. 国际学术组织、学术会议与学术论文
自然语言处理(natural language processing,NLP)在很大程度上与计算语言学(computational linguistics,CL)重合。与其他计算机学科类似,NLP/CL有一个属于自己的最权威的国际专业学会,叫做The Association for Computational Linguistics(ACL,URL:ACL Home Page),这个协会主办了NLP/CL领域最权威的国际会议,即ACL年会,ACL学会还会在北美和欧洲召开分年会,分别称为NAACL和EACL。除此之外,ACL学会下设多个特殊兴趣小组(special interest groups,SIGs),聚集了NLP/CL不同子领域的学者,性质类似一个大学校园的兴趣社团。其中比较有名的诸如SIGDAT(Linguistic data and corpus-based approaches to NLP)、SIGNLL(Natural Language Learning)等。这些SIGs也会召开一些国际学术会议,其中比较有名的就是SIGDAT组织的EMNLP(Conference on Empirical Methods on Natural Language Processing)和SIGNLL组织的CoNLL(Conference on Natural Language Learning)。此外还有一个International Committee on Computational Linguistics的老牌NLP/CL学术组织,它每两年组织一个称为International Conference on Computational Linguistics (COLING)的国际会议,也是NLP/CL的重要学术会议。NLP/CL的主要学术论文就分布在这些会议上。
作为NLP/CL领域的学者最大的幸福在于,ACL学会网站建立了称作ACL Anthology的页面(URL:ACL Anthology),支持该领域绝大部分国际学术会议论文的免费下载,甚至包含了其他组织主办的学术会议,例如COLING、IJCNLP等,并支持基于Google的全文检索功能,可谓一站在手,NLP论文我有。由于这个论文集合非常庞大,并且可以开放获取,很多学者也基于它开展研究,提供了更丰富的检索支持,具体入口可以参考ACL Anthology页面上方搜索框右侧的不同检索按钮。
与大部分计算机学科类似,由于技术发展迅速,NLP/CL领域更重视发表学术会议论文,原因是发表周期短,并可以通过会议进行交流。当然NLP/CL也有自己的旗舰学术期刊,发表过很多经典学术论文,那就是Computational Linguistics(URL:MIT Press Journals)。该期刊每期只有几篇文章,平均质量高于会议论文,时间允许的话值得及时追踪。此外,ACL学会为了提高学术影响力,也刚刚创办了Transactions of ACL(TACL,URL:Transactions of the Association for Computational Linguistics (ISSN: 2307-387X)),值得关注。值得一提的是这两份期刊也都是开放获取的。此外也有一些与NLP/CL有关的期刊,如ACM Transactions on Speech and Language Processing,ACM Transactions on Asian Language Information Processing,Journal of Quantitative Linguistics等等。
根据Google Scholar Metrics 2013年对NLP/CL学术期刊和会议的评价,ACL、EMNLP、NAACL、COLING、LREC、Computational Linguistics位于前5位,基本反映了本领域学者的关注程度。
NLP/CL作为交叉学科,其相关领域也值得关注。主要包括以下几个方面:(1)信息检索和数据挖掘领域。相关学术会议主要由美国计算机学会(ACM)主办,包括SIGIR、WWW、WSDM等;(2)人工智能领域。相关学术会议主要包括AAAI和IJCAI等,相关学术期刊主要包括Artificial Intelligence和Journal of AI Research;(3)机器学习领域,相关学术会议主要包括ICML,NIPS,AISTATS,UAI等,相关学术期刊主要包括Journal of Machine Learning Research(JMLR)和Machine Learning(ML)等。例如最近兴起的knowledge graph研究论文,就有相当一部分发表在人工智能和信息检索领域的会议和期刊上。实际上国内计算机学会(CCF)制定了“中国计算机学会推荐国际学术会议和期刊目录”(CCF推荐排名),通过这个列表,可以迅速了解每个领域的主要期刊与学术会议。
最后,值得一提的是,美国Hal Daumé III维护了一个natural language processing的博客(natural language processing blog),经常评论最新学术动态,值得关注。我经常看他关于ACL、NAACL等学术会议的参会感想和对论文的点评,很有启发。另外,ACL学会维护了一个Wiki页面(ACL Wiki),包含了大量NLP/CL的相关信息,如著名研究机构、历届会议录用率,等等,都是居家必备之良品,值得深挖。
2. 国内学术组织、学术会议与学术论文
与国际上相似,国内也有一个与NLP/CL相关的学会,叫做中国中文信息学会(URL:中国中文信息学会)。通过学会的理事名单(中国中文信息学会)基本可以了解国内从事NLP/CL的主要单位和学者。学会每年组织很多学术会议,例如全国计算语言学学术会议(CCL)、全国青年计算语言学研讨会(YCCL)、全国信息检索学术会议(CCIR)、全国机器翻译研讨会(CWMT),等等,是国内NLP/CL学者进行学术交流的重要平台。尤其值得一提的是,全国青年计算语言学研讨会是专门面向国内NLP/CL研究生的学术会议,从组织到审稿都由该领域研究生担任,非常有特色,也是NLP/CL同学们学术交流、快速成长的好去处。值得一提的是,2010年在北京召开的COLING以及2015年即将在北京召开的ACL,学会都是主要承办者,这也一定程度上反映了学会在国内NLP/CL领域的重要地位。此外,计算机学会中文信息技术专委会组织的自然语言处理与中文计算会议(NLP&CC)也是最近崛起的重要学术会议。中文信息学会主编了一份历史悠久的《中文信息学报》,是国内该领域的重要学术期刊,发表过很多篇重量级论文。此外,国内著名的《计算机学报》、《软件学报》等期刊上也经常有NLP/CL论文发表,值得关注。
过去几年,在水木社区BBS上开设的AI、NLP版面曾经是国内NLP/CL领域在线交流讨论的重要平台。这几年随着社会媒体的发展,越来越多学者转战新浪微博,有浓厚的交流氛围。如何找到这些学者呢,一个简单的方法就是在新浪微博搜索的“找人”功能中检索“自然语言处理”、 “计算语言学”、“信息检索”、“机器学习”等字样,马上就能跟过去只在论文中看到名字的老师同学们近距离交流了。还有一种办法,清华大学梁斌开发的“微博寻人”系统(清华大学信息检索组)可以检索每个领域的有影响力人士,因此也可以用来寻找NLP/CL领域的重要学者。值得一提的是,很多在国外任教的老师和求学的同学也活跃在新浪微博上,例如王威廉(Sina Visitor System)、李沐(Sina Visitor System)等,经常爆料业内新闻,值得关注。还有,国内NLP/CL的著名博客是52nlp(我爱自然语言处理),影响力比较大。总之,学术研究既需要苦练内功,也需要与人交流。所谓言者无意、听者有心,也许其他人的一句话就能点醒你苦思良久的问题。无疑,博客微博等提供了很好的交流平台,当然也注意不要沉迷哦。
3. 如何快速了解某个领域研究进展
最后简单说一下快速了解某领域研究进展的经验。你会发现,搜索引擎是查阅文献的重要工具,尤其是谷歌提供的Google Scholar,由于其庞大的索引量,将是我们披荆斩棘的利器。
当需要了解某个领域,如果能找到一篇该领域的最新研究综述,就省劲多了。最方便的方法还是在Google Scholar中搜索“领域名称 + survey / review / tutorial / 综述”来查找。也有一些出版社专门出版各领域的综述文章,例如NOW Publisher出版的Foundations and Trends系列,Morgan & Claypool Publisher出版的Synthesis Lectures on Human Language Technologies系列等。它们发表了很多热门方向的综述,如文档摘要、情感分析和意见挖掘、学习排序、语言模型等。
如果方向太新还没有相关综述,一般还可以查找该方向发表的最新论文,阅读它们的“相关工作”章节,顺着列出的参考文献,就基本能够了解相关研究脉络了。当然,还有很多其他办法,例如去http://videolectures.net上看著名学者在各大学术会议或暑期学校上做的tutorial报告,去直接咨询这个领域的研究者,等等。
链接:https://www.zhihu.com/question/19895141/answer/149475410
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
针对这个问题,我们邀请了微软亚洲研究院首席研究员周明博士为大家解答。
<img src=”https://pic4.zhimg.com/v2-0556e1ea58ce3dfb713ac3d3111ca7db_b.png” data-rawwidth=”191″ data-rawheight=”191″ class=”content_image” width=”191″>

周明博士于2016年12月当选为全球计算语言学和自然语言处理研究领域最具影响力的学术组织——计算语言学协会(ACL, Association for Computational Linguistics)的新一届候任主席。此外,他还是中国计算机学会中文信息技术专委会主任、中国中文信息学会常务理事、哈工大、天津大学、南开大学、山东大学等多所学校博士导师。他1985年毕业于重庆大学,1991年获哈工大博士学位。1991-1993年清华大学博士后,随后留校任副教授。1996-1999访问日本高电社公司主持中日机器翻译研究。他是中国第一个中英翻译系统、日本最有名的中日机器翻译产品J-北京的发明人。1999年加入微软研究院并随后负责自然语言研究组,主持研制了微软输入法、对联、英库词典、中英翻译等著名系统。近年来与微软产品组合作开发了小冰(中国)、Rinna(日本)等聊天机器人系统。他发表了100余篇重要会议和期刊论文。拥有国际发明专利40余项。
————这里是正式回答的分割线————
自然语言处理(简称NLP),是研究计算机处理人类语言的一门技术,包括:
1.句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。
2.信息抽取:从给定文本中抽取重要的信息,比如,时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什么结果。涉及到实体识别、时间抽取、因果关系抽取等关键技术。
3.文本挖掘(或者文本数据挖掘):包括文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。目前主流的技术都是基于统计机器学习的。
4.机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本。根据输入媒介不同,可以细分为文本翻译、语音翻译、手语翻译、图形翻译等。机器翻译从最早的基于规则的方法到二十年前的基于统计的方法,再到今天的基于神经网络(编码-解码)的方法,逐渐形成了一套比较严谨的方法体系。
5.信息检索:对大规模的文档进行索引。可简单对文档中的词汇,赋之以不同的权重来建立索引,也可利用1,2,3的技术来建立更加深层的索引。在查询的时候,对输入的查询表达式比如一个检索词或者一个句子进行分析,然后在索引里面查找匹配的候选文档,再根据一个排序机制把候选文档排序,最后输出排序得分最高的文档。
6.问答系统: 对一个自然语言表达的问题,由问答系统给出一个精准的答案。需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,然后到知识库中查找可能的候选答案并通过一个排序机制找出最佳的答案。
7.对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。同时,为了体现个性化,要开发用户画像以及基于用户画像的个性化回复。
随着深度学习在图像识别、语音识别领域的大放异彩,人们对深度学习在NLP的价值也寄予厚望。再加上AlphaGo的成功,人工智能的研究和应用变得炙手可热。自然语言处理作为人工智能领域的认知智能,成为目前大家关注的焦点。很多研究生都在进入自然语言领域,寄望未来在人工智能方向大展身手。但是,大家常常遇到一些问题。俗话说,万事开头难。如果第一件事情成功了,学生就能建立信心,找到窍门,今后越做越好。否则,也可能就灰心丧气,甚至离开这个领域。这里针对给出我个人的建议,希望我的这些粗浅观点能够引起大家更深层次的讨论。
建议1:如何在NLP领域快速学会第一个技能?
我的建议是:找到一个开源项目,比如机器翻译或者深度学习的项目。理解开源项目的任务,编译通过该项目发布的示范程序,得到与项目示范程序一致的结果。然后再深入理解开源项目示范程序的算法。自己编程实现一下这个示范程序的算法。再按照项目提供的标准测试集测试自己实现的程序。如果输出的结果与项目中出现的结果不一致,就要仔细查验自己的程序,反复修改,直到结果与示范程序基本一致。如果还是不行,就大胆给项目的作者写信请教。在此基础上,再看看自己能否进一步完善算法或者实现,取得比示范程序更好的结果。
建议2:如何选择第一个好题目?
工程型研究生,选题很多都是老师给定的。需要采取比较实用的方法,扎扎实实地动手实现。可能不需要多少理论创新,但是需要较强的实现能力和综合创新能力。而学术型研究生需要取得一流的研究成果,因此选题需要有一定的创新。我这里给出如下的几点建议。
- 先找到自己喜欢的研究领域。你找到一本最近的ACL会议论文集, 从中找到一个你比较喜欢的领域。在选题的时候,多注意选择蓝海的领域。这是因为蓝海的领域,相对比较新,容易出成果。
- 充分调研这个领域目前的发展状况。包括如下几个方面的调研:方法方面,是否有一套比较清晰的数学体系和机器学习体系;数据方面,有没有一个大家公认的标准训练集和测试集;研究团队,是否有著名团队和人士参加。如果以上几个方面的调研结论不是太清晰,作为初学者可能不要轻易进入。
- 在确认进入一个领域之后,按照建议一所述,需要找到本领域的开源项目或者工具,仔细研究一遍现有的主要流派和方法,先入门。
- 反复阅读本领域最新发表的文章,多阅读本领域牛人发表的文章。在深入了解已有工作的基础上,探讨还有没有一些地方可以推翻、改进、综合、迁移。注意做实验的时候,不要贪多,每次实验只需要验证一个想法。每次实验之后,必须要进行分析存在的错误,找出原因。
- 对成功的实验,进一步探讨如何改进算法。注意实验数据必须是业界公认的数据。
- 与已有的算法进行比较,体会能够得出比较一般性的结论。如果有,则去写一篇文章,否则,应该换一个新的选题。
建议3:如何写出第一篇论文?
- 接上一个问题,如果想法不错,且被实验所证明,就可开始写第一篇论文了。
- 确定论文的题目。在定题目的时候,一般不要“…系统”、“…研究与实践”,要避免太长的题目,因为不好体现要点。题目要具体,有深度,突出算法。
- 写论文摘要。要突出本文针对什么重要问题,提出了什么方法,跟已有工作相比,具有什么优势。实验结果表明,达到了什么水准,解决了什么问题。
- 写引言。首先讲出本项工作的背景,这个问题的定义,它具有什么重要性。然后介绍对这个问题,现有的方法是什么,有什么优点。但是(注意但是)现有的方法仍然有很多缺陷或者挑战。比如(注意比如),有什么问题。本文针对这个问题,受什么方法(谁的工作)之启发,提出了什么新的方法并做了如下几个方面的研究。然后对每个方面分门别类加以叙述,最后说明实验的结论。再说本文有几条贡献,一般写三条足矣。然后说说文章的章节组织,以及本文的重点。有的时候东西太多,篇幅有限,只能介绍最重要的部分,不需要面面俱到。
- 相关工作。对相关工作做一个梳理,按照流派划分,对主要的最多三个流派做一个简单介绍。介绍其原理,然后说明其局限性。
- 然后可设立两个章节介绍自己的工作。第一个章节是算法描述。包括问题定义,数学符号,算法描述。文章的主要公式基本都在这里。有时候要给出简明的推导过程。如果借鉴了别人的理论和算法,要给出清晰的引文信息。在此基础上,由于一般是基于机器学习或者深度学习的方法,要介绍你的模型训练方法和解码方法。第二章就是实验环节。一般要给出实验的目的,要检验什么,实验的方法,数据从哪里来,多大规模。最好数据是用公开评测数据,便于别人重复你的工作。然后对每个实验给出所需的技术参数,并报告实验结果。同时为了与已有工作比较,需要引用已有工作的结果,必要的时候需要重现重要的工作并报告结果。用实验数据说话,说明你比人家的方法要好。要对实验结果好好分析你的工作与别人的工作的不同及各自利弊,并说明其原因。对于目前尚不太好的地方,要分析问题之所在,并将其列为未来的工作。
- 结论。对本文的贡献再一次总结。既要从理论、方法上加以总结和提炼,也要说明在实验上的贡献和结论。所做的结论,要让读者感到信服,同时指出未来的研究方向。
- 参考文献。给出所有重要相关工作的论文。记住,漏掉了一篇重要的参考文献(或者牛人的工作),基本上就没有被录取的希望了。
- 写完第一稿,然后就是再改三遍。
- 把文章交给同一个项目组的人士,请他们从算法新颖度、创新性和实验规模和结论方面,以挑剔的眼光,审核你的文章。自己针对薄弱环节,进一步改进,重点加强算法深度和工作创新性。
- 然后请不同项目组的人士审阅。如果他们看不明白,说明文章的可读性不够。你需要修改篇章结构、进行文字润色,增加文章可读性。
- 如投ACL等国际会议,最好再请英文专业或者母语人士提炼文字。
————这里是回答结束的分割线————
感谢大家的阅读。
本帐号为微软亚洲研究院的官方知乎帐号。本帐号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个帐号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
链接:https://www.zhihu.com/question/24417961/answer/148743442
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.宗成庆 《统计自然语言处理处理》
很全面,基本上涉及了自然语言处理的所有知识
<img data-rawwidth=”1280″ data-rawheight=”1707″ src=”https://pic3.zhimg.com/v2-e9882c9daf9fa8c60576447d6cea21b6_b.jpg” class=”origin_image zh-lightbox-thumb” width=”1280″ data-original=”https://pic3.zhimg.com/v2-e9882c9daf9fa8c60576447d6cea21b6_r.jpg”>

2.《Natural Language processing with Python》
非常实用的工具书,叫你怎么用Python实际进行操作,上手处理文本或者语料库。
以下两本书都是我在我们学校借的英文原版,如果找不到可以去搜中文译本~
<img data-rawwidth=”1280″ data-rawheight=”1280″ src=”https://pic4.zhimg.com/v2-d982760652fdbe4267f72667fde23db3_b.jpg” class=”origin_image zh-lightbox-thumb” width=”1280″ data-original=”https://pic4.zhimg.com/v2-d982760652fdbe4267f72667fde23db3_r.jpg”>

3. 稍微进阶一点的 Philipp Koehn 《Statistical Machine Translation》
如果你对机器翻译感兴趣,可以继续看这本
这本书的中文版也是宗成庆老师翻译的,可以去找找
<img data-rawwidth=”1280″ data-rawheight=”1707″ src=”https://pic1.zhimg.com/v2-e5dd784ed58ec159d5475421e8b94fd8_b.jpg” class=”origin_image zh-lightbox-thumb” width=”1280″ data-original=”https://pic1.zhimg.com/v2-e5dd784ed58ec159d5475421e8b94fd8_r.jpg”>

4.更新两本这几天刚好在看的,《编程集体智慧》,应该也是可以找到中文翻译版PDF的,主要围绕机器学习这一领域来加深你的编程功底,每一个例子都有非常完整的代码,可以学习到很多!<img data-rawwidth=”1280″ data-rawheight=”1707″ src=”https://pic1.zhimg.com/v2-ddb002a8ed4c4e5f106334c5291bf7d4_b.jpg” class=”origin_image zh-lightbox-thumb” width=”1280″ data-original=”https://pic1.zhimg.com/v2-ddb002a8ed4c4e5f106334c5291bf7d4_r.jpg”>

5.《Pattern Recognition and Machine Learning》
没啥好介绍的,机器学习经典书籍~但是晦涩,晦涩,晦涩…入坑需谨慎,我可能快要从入门到放弃了…
<img data-rawwidth=”1280″ data-rawheight=”1280″ src=”https://pic4.zhimg.com/v2-5ee2311573c249ece362db16dca848bf_b.jpg” class=”origin_image zh-lightbox-thumb” width=”1280″ data-original=”https://pic4.zhimg.com/v2-5ee2311573c249ece362db16dca848bf_r.jpg”>

如果我还有看什么书,我应该会不定期更新一下这条回答吧,也当是给自己做个记录~
差不多就这些啦,如果看完这些应该能够顺利入门了,剩下的就是自己上手去做!
链接:https://www.zhihu.com/question/24417961/answer/113638582
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主 和 我 情况类似,应该也是 “野生” NLPer。我的工作主要是文本数据挖掘,和 NLP 相关性 很强。我一开始只关心一两个小点,后面自己慢慢系统地补足。我说一下自己的学习路线吧。
我参考了两本书 作为学习的蓝图,并且主要章节(机器翻译和语音识别 没看)都认真看了一两遍。
(1) 统计自然语言处理(第2版)宗成庆 著
(2) 语音与语言处理(英文版 第2版)Daniel Jurafsky, James H. Martin 著
这两本书分别是 中文 和 英文 中 比较权威的书籍, 并且知识点全面。出版时间也比较新。以这两本为学习主线 配合 其他的书籍和论文作为 辅助。
另外 自然语言处理 与 机器学习 十分相关,我参考相关的几本书,主要推荐两本:
(3) 机器学习 周志华 著
本书比较易懂, 看完 前10章,颇有收获。然而一开始看的是 范明 翻译的 机器学习导论,但比较晦涩,就不推荐了。看到国人写出这样的好书,还是值得高兴的。
(4) 统计学习方法 李航 著
这本书蛮难啃的, 我按需看了一半,其中 CRF 这本讲的比较全。
配合性的其他书籍主要有:
(5) 计算语言学(修订 版)刘颖 著
比较偏语言学一点,数学理论比较少,相对简单一点, 看一遍 收益也有不少
(6) 自然语言处理简明教程 冯志伟 著
相对简单,稍微略显啰嗦,不过感觉 HMM 这本书讲的最易懂。
(7) 自然语言处理的形式模型 冯志伟 著
这本和 (6) 比,增加不少 深度 和 难度,建议按需慢慢啃。我啃了几章,觉得蛮有用。
(8) 自然语言处理基本理论和方法 陈鄞 编
哈工大出的书,纯粹为 配合 超星视频 而买。
(9) Java自然语言处理(影印版 英文版) Richard M Reese 著
学了总要实践吧,Java 还是 要比 Python 靠谱。
(10) 本体方法及其应用 甘健侯 等 著
(11) 本体与词汇库(英文影印版)典居仁(Chu-Ren Huang)等 编
这两本书对 信息抽取 有一定帮助,不感兴趣的可以略过。
以上所有列出的图书我都有纸介质 (能买则买, 买不到就打印)
另外超星学术视频 (网络上可以找到资源):
(12)自然语言理解 宗成庆(中科院)
看了感觉是配套 宗成庆书的初版
(13)自然语言处理 关毅(哈工大)
看起来还算蛮简单,和(8)几乎是配套的
(14) Stanford 的 NLP 课程(Youtube)
Dan Jurafsky & Chris Manning: Natural Language Processing
(15) Michael Collins 的Coursera课程 和 主页
Michael Collins:Natural Language Processing
链接:https://www.zhihu.com/question/24417961/answer/66872781
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. 2008.Introduction to Information Retrieval. Cambridge University Press.
Christopher D. Manning and Hinrich Schütze. 1999. Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press.
Daniel Jurafsky and James H. Martin. 2008. Speech and Language Processing: An Introduction to Natural Language Processing, Speech Recognition, and Computational Linguistics. 2nd edition. Prentice-Hall.
国际计算语言学学会ACL Fellow的名单应该就是最高的认可吧?历年ACL Fellow的名单请参看官网ACL Fellows – ACL Wiki
以人类语言为研究对象的“自然语言处理”(Natural Language Processing:NLP)是人工智能最重要的研究方向之一。在自然语言处理领域,ACL是世界上影响力最大、也最具活力、最有权威的国际学术组织,成立至今已有57年历史,会员遍布世界60多个国家和地区,代表了自然语言处理领域的世界最高水平。
2011年开始,ACL开始以一年平均4-5个的速度评选会士,ACL Fellow的头衔是对NLP领域有杰出贡献的人最高的认可。截至2016年ACL共评选出40个会士,其中4位是华人/华裔,分别是:
Dekai Wu(2011 ACL Fellow),香港科技大学吴德凯教授,成就是“较早将中文分词方法用于英文词组的分割,并且将英文词组和中文词在机器翻译时对应起来”,已发表学术论文百余篇,论文引用量超6800次;
<img src=”https://pic2.zhimg.com/v2-303ace5b9e4e577787c2969eb139c171_b.png” data-rawwidth=”2200″ data-rawheight=”748″ class=”origin_image zh-lightbox-thumb” width=”2200″ data-original=”https://pic2.zhimg.com/v2-303ace5b9e4e577787c2969eb139c171_r.png”>
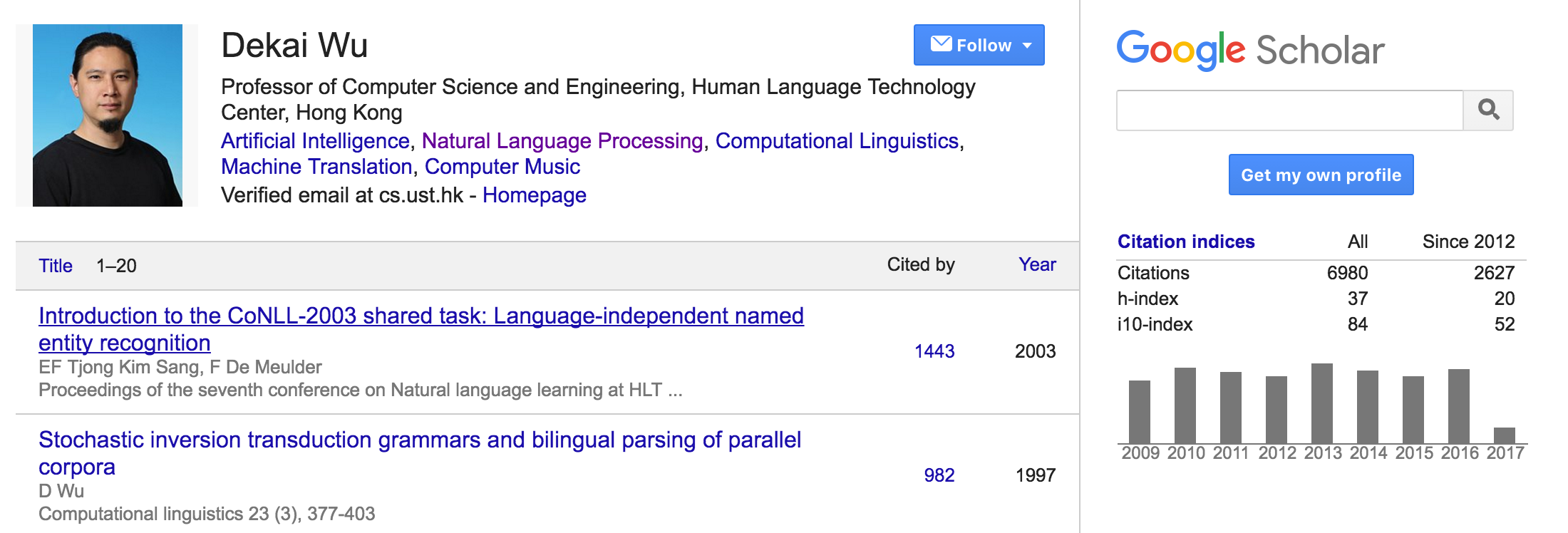
Hwee Tou Ng(2012 ACL Fellow),新加坡国立大学黄伟道教授,自然语言处理和信息检索专家,精通于核心分辨率和语义处理以及语义语料库的开发,ACL2005程序委员会主席,已发表学术论文百余篇,被引用超8200次;
<img src=”https://pic2.zhimg.com/v2-b1b55eb47a33241445df98ed67aca279_b.png” data-rawwidth=”2252″ data-rawheight=”680″ class=”origin_image zh-lightbox-thumb” width=”2252″ data-original=”https://pic2.zhimg.com/v2-b1b55eb47a33241445df98ed67aca279_r.png”>

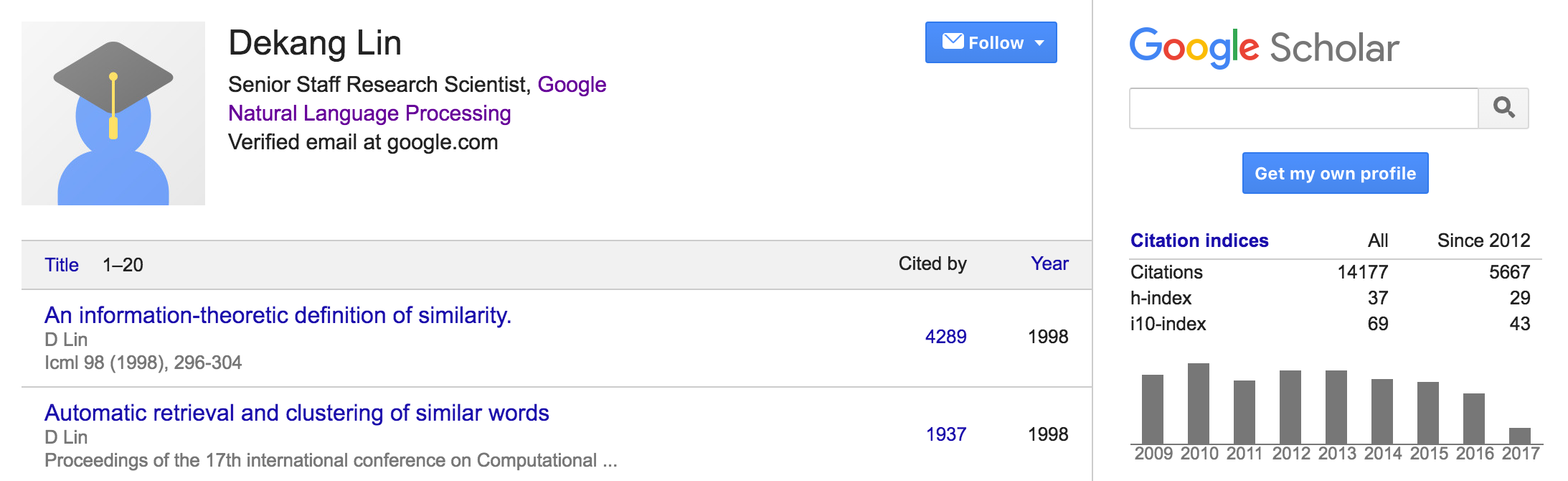
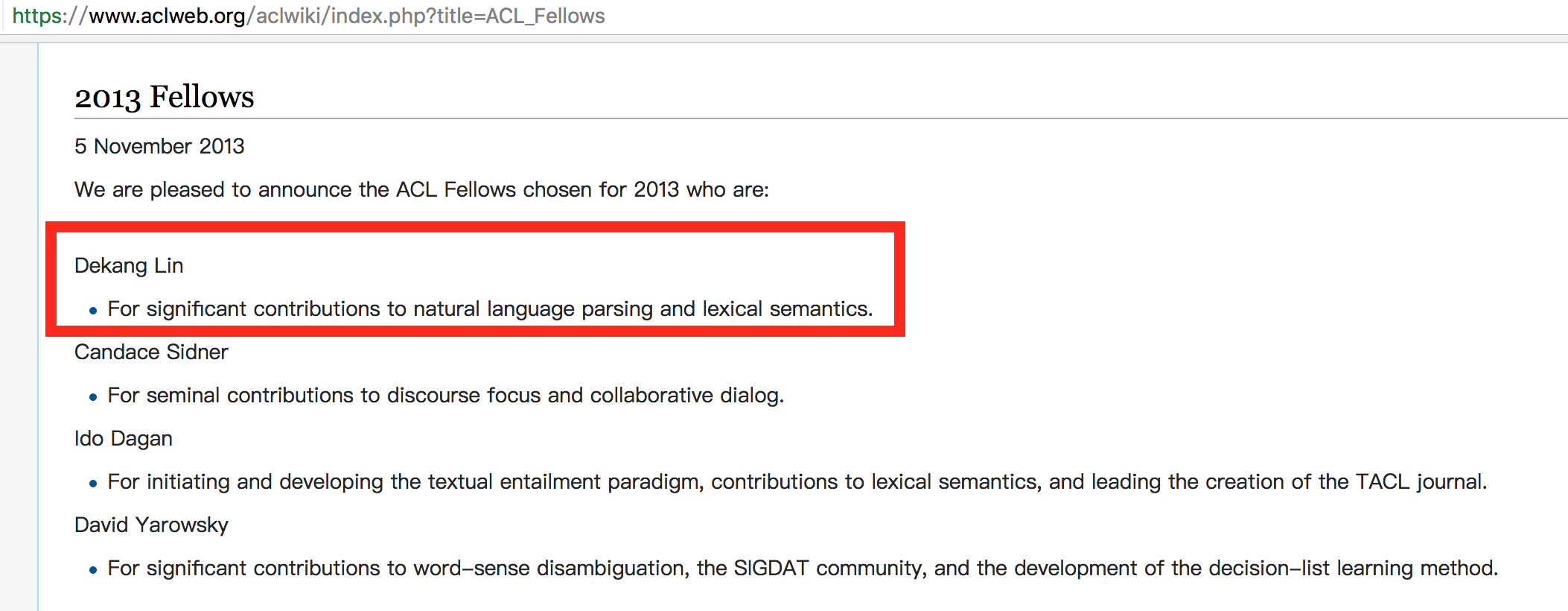
Dekang Lin(2013 ACL Fellow):林德康,前Google高级管理科学家(senior staff research scientist),在加入Google之前是加拿大Alberta大学计算机教授,发表过逾90篇论文,被引用超过14000次,对自然语言解析和词汇语义做出重要贡献。林德康教授还多次担任计算语言最高学术机构国际计算语言学学会ACL(Association for Computational Linguistics)的领导职务, 包括:ACL 2002程序委员会联合主席、ACL2011大会主席、ACL 2007北美分会执行委员等。2016年回国创办了一家智能语音助手相关的公司奇点机智;
<img src=”https://pic2.zhimg.com/v2-d1e5eb95791d639895a923c4ab6a4bb5_b.png” data-rawwidth=”2186″ data-rawheight=”670″ class=”origin_image zh-lightbox-thumb” width=”2186″ data-original=”https://pic2.zhimg.com/v2-d1e5eb95791d639895a923c4ab6a4bb5_r.png”>
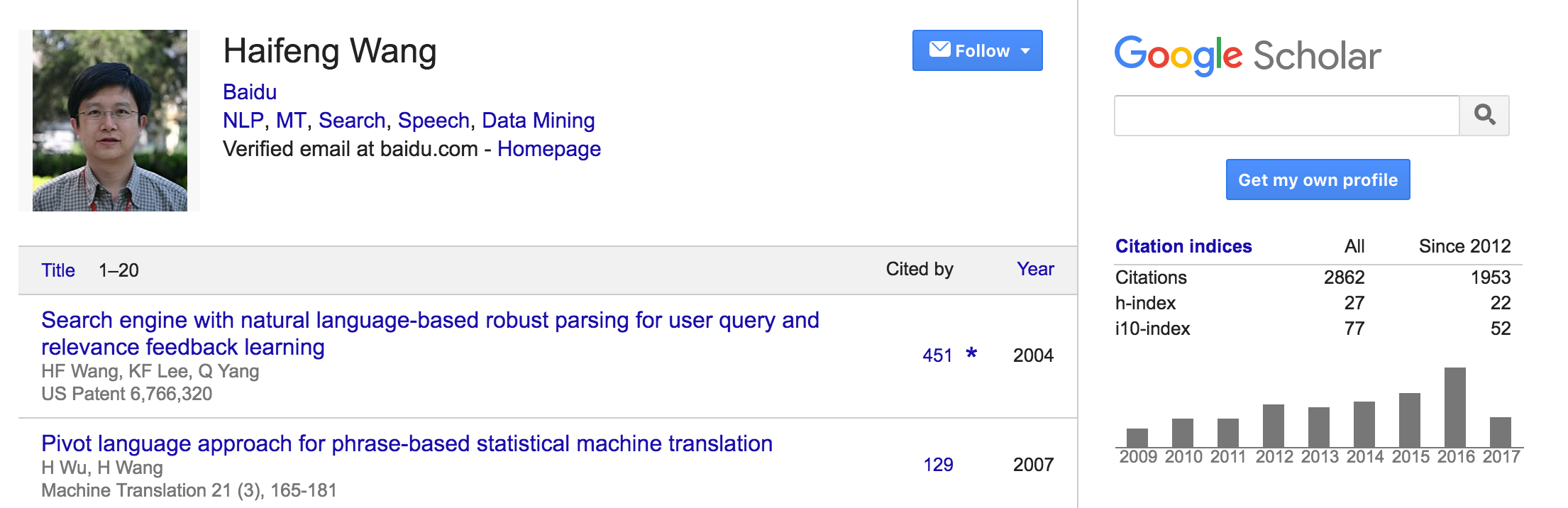
王海峰(2016年 ACL Fellow):现任百度副总裁,AI技术平台体系(AIG)总负责人,已发表学术论文百余篇,论文引用量超2800次。已授权或公开的专利申请120余项。王海峰曾作为负责人承担国家核高基重大专项、863重大项目,并正在承担973、自然科学基金重点项目等。
<img src=”https://pic3.zhimg.com/v2-b29b4f9c58951bcd830095d169afbd5e_b.png” data-rawwidth=”2210″ data-rawheight=”716″ class=”origin_image zh-lightbox-thumb” width=”2210″ data-original=”https://pic3.zhimg.com/v2-b29b4f9c58951bcd830095d169afbd5e_r.png”>
题主问的是国内的牛人,那就是林德康和王海峰两位教授啦~
听说两位教授所在公司目前都在招NLP方面的人才,有兴趣的大神可以投简历至hr@naturali.io 和 hr@baidu.com试一试,祝大家好运~㊗️
机器学习、深度学习与自然语言处理领域推荐的书籍列表
机器学习、深度学习与自然语言处理领域推荐的书籍列表 是笔者 Awesome Reference 系列的一部分;对于其他的资料、文章、视频教程、工具实践请参考面向程序猿的数据科学与机器学习知识体系及资料合集。本文算是抛砖引玉,笔者最近有空就会在 Pad 上面随手翻阅这些书籍,希望能够了解其他优秀的书籍。
数学基础
- 2010 – All of Statistics: A Concise Course in Statistical Inference【Book】: The goal of this book is to provide a broad background in probability and statistics for students in statistics, Computer science (especially data mining and machine learning), mathematics, and related disciplines.
- 2008-统计学完全教程:由美国当代著名统计学家L·沃塞曼所著的《统计学元全教程》是一本几乎包含了统计学领域全部知识的优秀教材。本书除了介绍传统数理统计学的全部内容以外,还包含了Bootstrap方法(自助法)、独立性推断、因果推断、图模型、非参数回归、正交函数光滑法、分类、统计学理论及数据挖掘等统计学领域的新方法和技术。本书不但注重概率论与数理统计基本理论的阐述,同时还强调数据分析能力的培养。本书中含有大量的实例以帮助广大读者快速掌握使用R软件进行统计数据分析。
机器学习
- 2007 – Pattern Recognition And Machine Learning【Book】: The book is suitable for courses on machine learning, statistics, computer science, signal processing, computer vision, data mining, and bioinformatics.
- 2012 – Machine Learning A Probabilistic Perspective 【Book】: This textbook offers a comprehensive and self-contained introduction to the field of machine learning, a unified, probabilistic approach. The coverage combines breadth and depth, offering necessary background material on such topics as probability, optimization, and linear algebra as well as discussion of recent developments in the field, including conditional random fields, L1 regularization, and deep learning.
- 2012 – 李航:统计方法学:李航老师的这本书偏优化和推倒,推倒相应算法的时候可以参考这本书。
- 2014 – DataScience From Scratch【Book】: In this book, you’ll learn how many of the most fundamental data science tools and algorithms work by implementing them from scratch.
- 2015 – Python Data Science Handbook【Book】:Jupyter Notebooks for the Python Data Science Handbook
- 2015 – Data Mining, The Textbook【Book】: This textbook explores the different aspects of data mining from the fundamentals to the complex data types and their applications, capturing the wide diversity of problem domains for data mining issues.
- 2016 – 周志华 机器学习【Book】:周志华老师的这本书非常适合作为机器学习入门的书籍,书中的例子十分形象且简单易懂。
- University of Illinois at Urbana-Champaign:Text Mining and Analytics【Course】
- 台大机器学习技法【Course】
- 斯坦福 机器学习课程【Course】
- CS224d: Deep Learning for Natural Language Processing【Course】
- Unsupervised Feature Learning and Deep Learning【Course】:来自斯坦福的无监督特征学习与深度学习系列教程
深度学习
- 2015-The Deep Learning Textbook【Book】:中文译本这里,The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free.
- Stanford Deep Learning Tutorial【Book】: This tutorial will teach you the main ideas of Unsupervised Feature Learning and Deep Learning. By working through it, you will also get to implement several feature learning/deep learning algorithms, get to see them work for yourself, and learn how to apply/adapt these ideas to new problems.
- Neural Networks and Deep Learning【Book】: Neural Networks and Deep Learning is a free online book. The book will teach you about: (1) Neural networks, a beautiful biologically-inspired programming paradigm which enables a computer to learn from observational data. (2) Deep learning, a powerful set of techniques for learning in neural networks
- Practical Deep Learning For Coders 【Course】:七周的免费深度学习课程,学习如何构建那些优秀的模型。
- Oxford Deep NLP 2017 course【Course】: This is an advanced course on natural language processing. Automatically processing natural language inputs and producing language outputs is a key component of Artificial General Intelligence.
自然语言处理
- 2016 – CS224d: Deep Learning for Natural Language Processing【Course】
- 2017 – Oxford Deep NLP 2017 course【Course】
- 2015 – Text Data Management and Analysis【Book】: A Practical Introduction to Information Retrieval and Text Mining
- DL4NLP-Deep Learning for NLP resources【Resource】
泛数据科学
- 2012 – 深入浅出数据分析 中文版【Book】:深入浅出数据分析》以类似“章回小说”的活泼形式,生动地向读者展现优秀的数据分析人员应知应会的技术:数据分析基本步骤、实验方法、最优化方法、假设检验方法、贝叶斯统计方法、主观概率法、启发法、直方图法、回归法、误差处理、相关数据库、数据整理技巧;正文之后,意犹未尽地以三篇附录介绍数据分析十大要务、R工具及ToolPak工具,在充分展现目标知识以外,为读者搭建了走向深入研究的桥梁。
- Lean Analytics — by Croll & Yoskovitz: 本书是教会你如何建立基本的以商业思维去使用这些数据,虽然这本书本身定位是面向初学者,不过我觉得你可以从中学到更多。你可以从本书中学到一条基本准则、6个基础的线上商业形态以及隐藏其后的数据策略。
- Business value in the ocean of data — by Fajszi, Cser & Fehér: 如果说Lean Analytics是关于面向初学者讲解商业逻辑加上数据,那么本书是面向大型公司来讲解这些内容。听上去好像没啥新鲜的,不过往往初创企业与独角兽之间面对的问题是千差万别,本书中会介绍譬如保险公司是如何进行定价预测或者银行从业者们又在面临怎样的数据问题。
- Naked Statistics — Charles Wheelan: 这本书我一直很是推荐,因为它不仅仅面向数据科学家,而是为任何一个行业的人提供基本的统计思维,这一点恰恰是我认为非常关键的。这本书并没有太多的长篇大论,而是以一个又一个的故事形式来讲解统计思维在公司运营中的重要作用。
- Doing Data Science — Schutt and O’Neil: 这算是最后一本非技术向的书了吧,这本书相较于上面三本更上一层楼,他深入了譬如拟合模型、垃圾信息过滤、推荐系统等等方面的知识。
- Data Science at the Command Line — Janssens: 在介绍本书之前首先要强调下,千万不要畏惧编程,学习些简单的编程知识能够有助于你做更多有趣的事。你可以自己去获取、清洗、转化或者分析你的数据。不过我也不会一上来就扔出大堆的编程知识,我建议还是从简单的命令行操作开始学起,而本书正是介绍如何只用命令行就帮你完成些数据科学的任务。
- Python for Data Analysis — McKinney: Python算是近几年来非常流行的数据分析的语言了吧,人生苦短,请用Python。这本书算是个大部头了,有400多页吧,不过它首先为你介绍了Python的基础语法,因此学起来不会很困难吧。
- I heart logs — Jay Kreps: 最后一本书则是短小精悍,加起来才60多页吧。不过它对于数据收集和处理的技术背景有很好的概述,虽然很多分析家或者数据科学家并不会直接用到这些知识,但是至少你能够理解技术人员们可以用哪些架构去解决数据问题。
本科大三,学过机器学习算法。假设你学过的算法都熟练的话,你已经有了不错的基础了。那么问题分解为:1.如何入门NLP;2.如何开始做NLP的研究。这两个我分别回答,但是你可以同时行动。
入门NLP。就像你自学机器学习一样,你最好系统的看一本书,或者上一门公开课,来系统的梳理一遍NLP的基本知识,了解NLP的基本问题。这里我推荐Michael Collins的公开课:COMS W4705: Natural Language Processing (Spring 2015),以及Jason Eisner的Lecture Notes:600.465 – Natural Language Processing。如果学有余力的话,可以看一下参考书:https://web.stanford.edu/~jurafsky/slp3/。 时间有限的情况下,公开课和Notes就够了。
系统学习知识的同时(或之后),你可以开始着手复现一些经典的项目。这个过程非常重要:1.你可以巩固自己的知识(确定你真的正确理解了);2.你可以进一步提高自己的科研和工程能力;3.你很可能在实现的过场中发现问题,产生灵感,做出自己的工作(发一篇paper)。那么复现什么项目呢?如果你的导师没有给你指定的话,不妨从历年NLP顶会(ACL,EMNLP,NAACL)的获奖论文中筛选你感兴趣又有能力完成的。由于full paper的工程量通常较大,你可以先从short paper中进行选择。
下面是最近的ACL,EMNLP和NAACL的录取论文列表:
ACL | Association for Computational Linguistics
EMNLP 2016
Accepted Papers
同时,再附上一些Jason Eisner为帮助本科生做研究而写的一些建议:
Advice for Research Students (and others)
希望你能enjoy NLP!
偏旁部首对于词性标注确实是有效的,尤其是对于未登录词的泛化能力。
比如言字旁、提手旁的一般是动词(说、谈、记等);提土旁的一般为名词(地、堤、城等)。我师姐09年做过一篇论文,题目是:基于SVMTool的中文词性标注,使用了部首特征。这也是我们实验室LTP早期版本中所采用的词性标注器,现版LTP没有使用。
对于命名实体识别,我目前还没有看到有哪些工作用了部首特征。猜测有三个可能的原因:
1. 命名实体绝大多数都是名词,部首特征对于名词之间的细粒度区分作用较小;
2. 命名实体识别任务大都已经使用了词性特征,与部首特征有较大overlap;
3. 命名实体识别任务中词缀的影响更加显著,比如:xx国,xx银行,xx所。
其他的工作,最近糕神用部首做了汉字embedding,可以参考:http://arxiv.org/ftp/arxiv/papers/1508/1508.06669.pdf
整体而言,传统NLP框架上增加部首特征,即使有效果也是比较有限的,而且创新性较小。但是在Neural Network上应该还是有可发挥的空间。最近英文上的一个研究趋势是Character-aware neural modeling,我觉得在中文上是不是也可以做类似的扩展,Character-based or even Radical-based,通过设计更好的学习结构从更原始的信号中学习feature。
python速度和方便程度都不比不上matlab。而且文献中有很多程序都是用matlab写的。另外matlab的矩阵计算优化得很好,计算速度远远超过了numpy。
如果要作为产品,那么用C++和Eigen库开发,然后并行化,是极好的。整体速度远远高于matlab和python,内存使用量也小(大数据情况下内存使用量也是要考虑的)。
我先在基本用matlab做原型,用C++开发产品。
python介于两者之间,我自己用下来的感觉是比较尴尬的。
「python速度和方便程度都不比不上matlab」——方便程序?安装的便捷性和时间消耗?启动的时间消息?语法对人的友好度?另外,说 Matlab 算矩阵超过 numpy,我很奇怪 Fortran 会这么不给力。有可验证的对比测试么?
Matlab <= C++Eigen优化 < C++ Eigen < C++ for循环优化 < Numpy < C++ for循环
优化是指编译的时候加了-O3 -march=native,for循环优化的时候手动设置了一些局部变量。
我测试的环境是Phenom X4 + ddr2 8G + ubuntu 12.04
结果可能随机器配置不同而不同,你可以试试。
另外NLP是好东西,分享一点资料:
http://www.52nlp.cn/
http://blog.csdn.net/sinboy/article/details/952977
http://www.chedong.com/tech/lucene.html (听说lucene入门都是看这个的,CJK的作者,貌似没有他就没有IK和庖丁了)
另外还有一份PDF 数学之美与浪潮之巅.pdf
AC自动机, HMM算法等请自学好。。。
PS:混了3年了, 还是觉得自己啥都不会。不敢说“掌握”这个词。
PS2:感觉LZ是迷茫了,对前途的迷茫, 想多学习一门语言, 感觉这样子有安全感一点。我以前也有过这样的想法, 谁知道PHP, .NET, JAVA, ASM, C++全部都学了个入门。到头来毕业的时候啥都会==啥都不会。LZ目前更应该的是做点什么出来。譬如说做个网站(起码几万代码规模),然后放到外网,让人访问,提出修改意见,学会设计一个产品。这样才是你要做的事儿。 我也是走这条路的人啦, 希望这个建议对LZ有帮助^__^
随着 2016 年结束,剑桥大学高级研究员 Marek Rei 对人工智能行业的 11 个主要会议和期刊进行了分析,它们包括 ACL、EACL、NAACL、EMNLP、COLING、CL、TACL、CoNLL、Sem / StarSem、NIPS 和 ICML。本次分析对目前在机器学习与自然语言处理领域的各类组织与院校的科研情况进行了对比。分析显示,在论文数量上,卡耐基梅隆大学(CMU)高居第一位。
以下各图所用到的信息均来自网络,每份文件的机构组织信息都是由论文的 pdf 文件中获取的,并不保证完全准确。
在你看完这份分析,得出自己的结论之前,请注意一个前提:论文的质量远比数量重要,而论文质量并不在本次分析的范围内。我们的分析来源于这样一个动机:我们希望展示深度学习和机器学习领域在过去的一年里发生了什么,大公司和院校正在做什么,希望它能够为你提供一些帮助。
首先是 2016 年最活跃的 25 个机构:
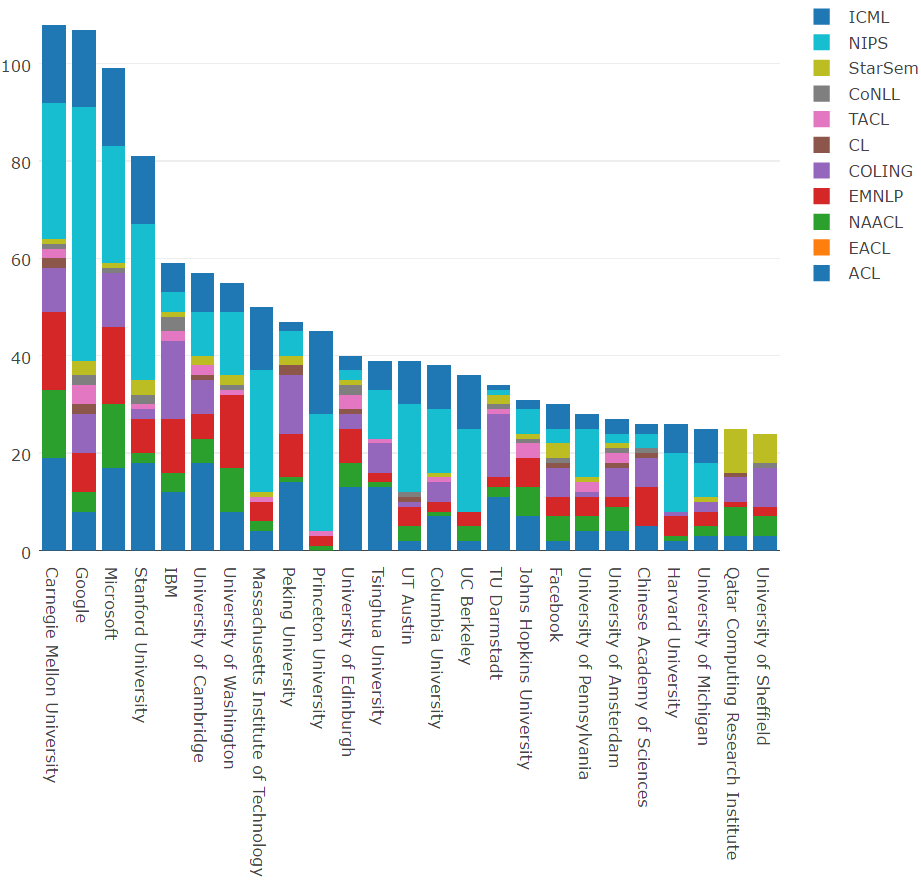 卡耐基梅隆大学仅以一篇论文优势击败谷歌。2016 年,微软和斯坦福也发表 80 多篇论文。IBM、剑桥、华盛顿大学和 MIT 都抵达了 50 篇的界线。谷歌、斯坦福、MIT 以及普林斯顿大学明显关注的是机器学习领域,论文发表几乎都集中在了 NIPS 和 ICML 上。实际上,谷歌论文几乎占了 NIPS 所有论文的 10%。不过,IBM、北大、爱丁堡大学以及达姆施塔特工业大学(TU Darmstadt)显然关注的是自然语言处理应用。
卡耐基梅隆大学仅以一篇论文优势击败谷歌。2016 年,微软和斯坦福也发表 80 多篇论文。IBM、剑桥、华盛顿大学和 MIT 都抵达了 50 篇的界线。谷歌、斯坦福、MIT 以及普林斯顿大学明显关注的是机器学习领域,论文发表几乎都集中在了 NIPS 和 ICML 上。实际上,谷歌论文几乎占了 NIPS 所有论文的 10%。不过,IBM、北大、爱丁堡大学以及达姆施塔特工业大学(TU Darmstadt)显然关注的是自然语言处理应用。
接下来,看看作者个人情况:
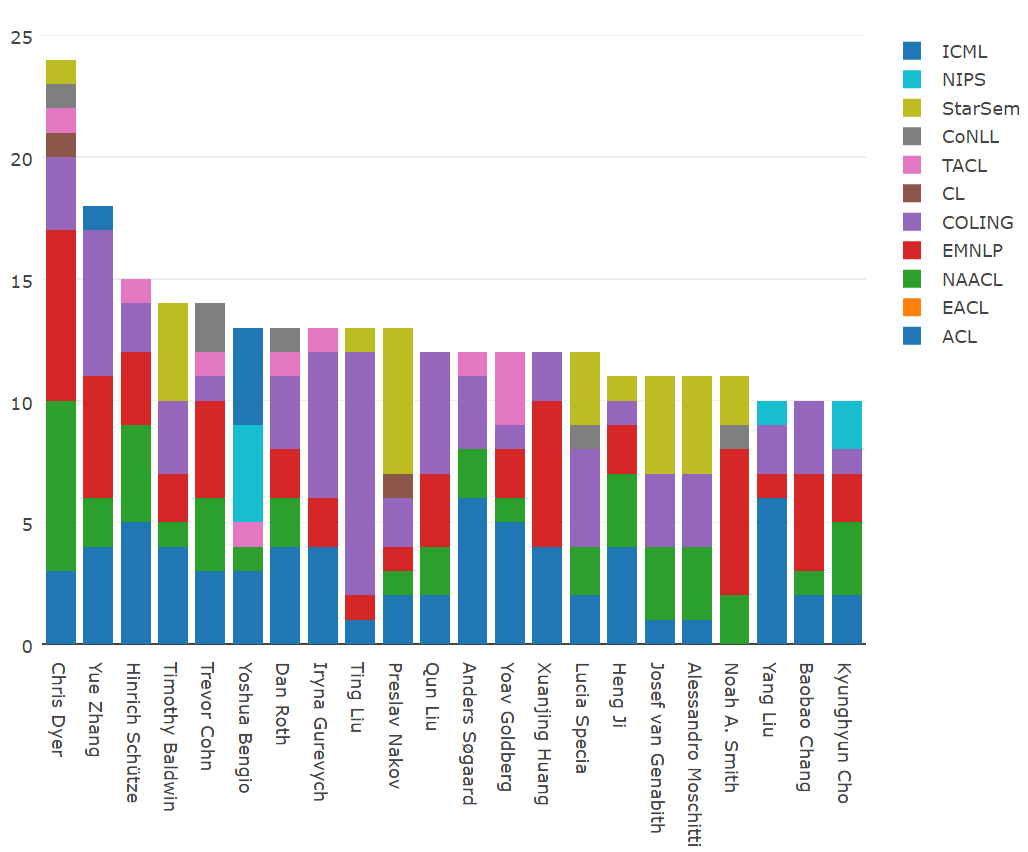 Chris Dyer 继续他惊人的论文发表势头,2016 年共发表了 24 篇论文!我很好奇为什么 Chris 不发 NIPS 或 ICML,但他确实在每一个 NLP 会议都有一篇论文(除了 2016 没有开的 EACL)。紧跟之后的是 Yue Zhang (18)、Hinrich Schütze (15)、Timothy Baldwin (14) 和 Trevor Cohn (14)。来自哈尔滨工业大学的 Ting Liu 在 COLING 上就发了 10 篇论文。Anders Søgaard 和 Yang Liu 在 ACL 上都有 6 篇论文。
Chris Dyer 继续他惊人的论文发表势头,2016 年共发表了 24 篇论文!我很好奇为什么 Chris 不发 NIPS 或 ICML,但他确实在每一个 NLP 会议都有一篇论文(除了 2016 没有开的 EACL)。紧跟之后的是 Yue Zhang (18)、Hinrich Schütze (15)、Timothy Baldwin (14) 和 Trevor Cohn (14)。来自哈尔滨工业大学的 Ting Liu 在 COLING 上就发了 10 篇论文。Anders Søgaard 和 Yang Liu 在 ACL 上都有 6 篇论文。
下面是 2016 年最高产的第一作者:
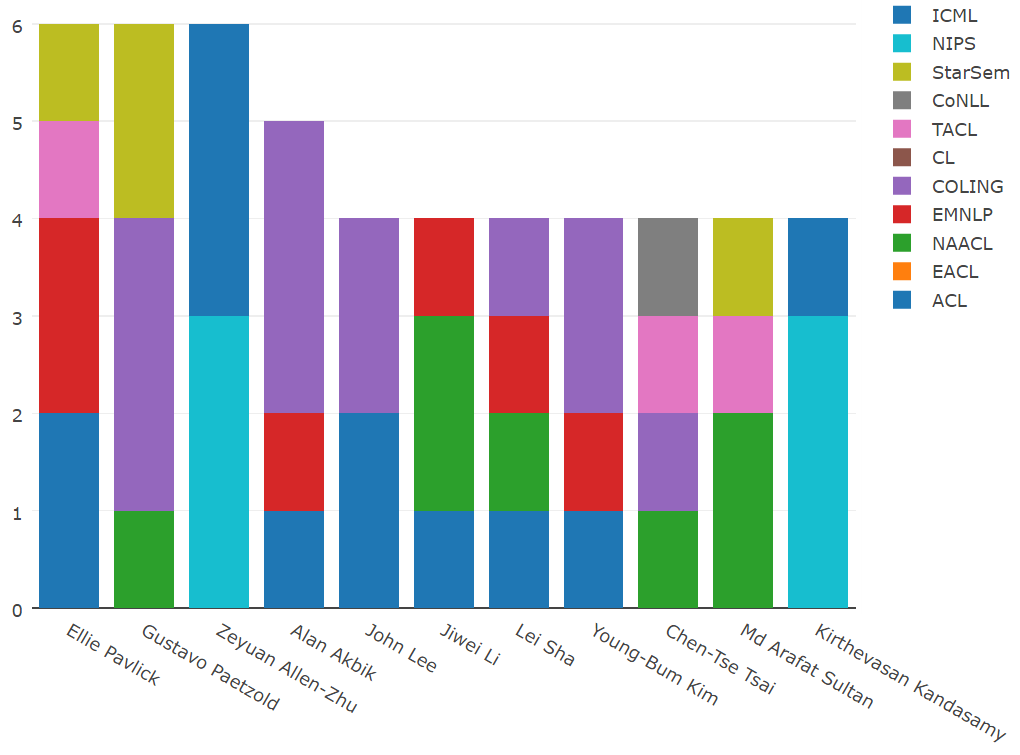 三位研究者发表了六篇第一作者论文,他们是 Ellie Pavlick(宾夕法尼亚大学)、Gustavo Paetzold(谢菲尔德大学)和 Zeyuan Allen-Zhu(普林斯顿大学高级研究所)。Alan Akbik(IBM)发表了 5 篇第一作者论文,还有七位研究者发表了四篇第一作者论文。
三位研究者发表了六篇第一作者论文,他们是 Ellie Pavlick(宾夕法尼亚大学)、Gustavo Paetzold(谢菲尔德大学)和 Zeyuan Allen-Zhu(普林斯顿大学高级研究所)。Alan Akbik(IBM)发表了 5 篇第一作者论文,还有七位研究者发表了四篇第一作者论文。
另外有 42 人发表了三篇第一作者论文,231 人发布了两篇第一作者论文。
接下来看看在时间序列上的排布,首先,在不同会议上发表的论文总数:
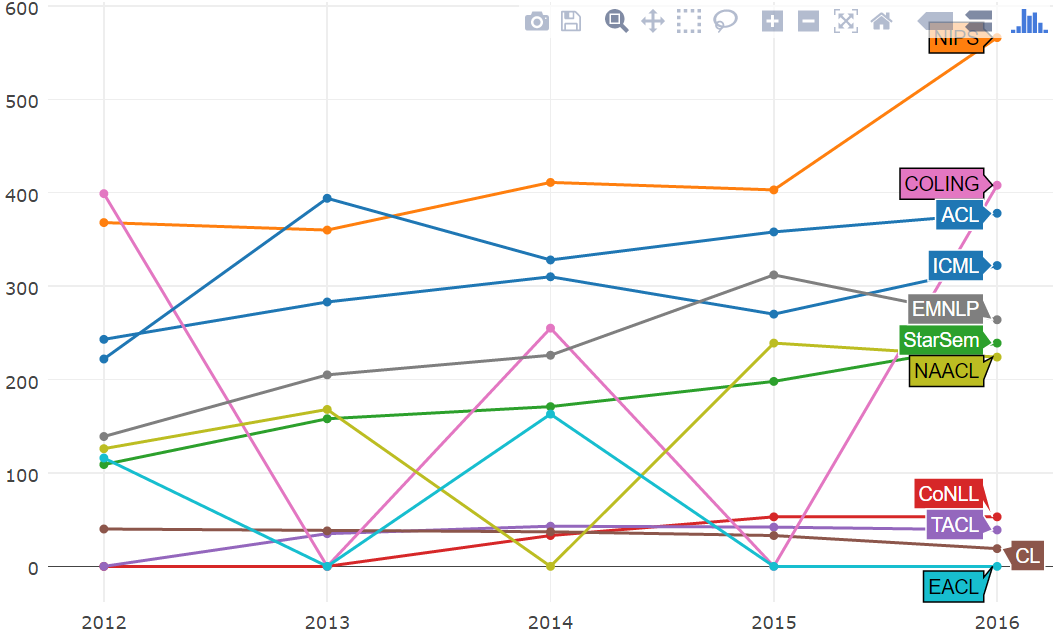
NIPS 一直以来每年都有一场规模很大的会议,今年看起来更是不得了。另外,COLING 今年的表现超过了预期,甚至超过了 ACL。这是自 2012 年 NAACL 和 COLING 合并以来的第一次。
下面是每个组织机构的历年来的论文数量:
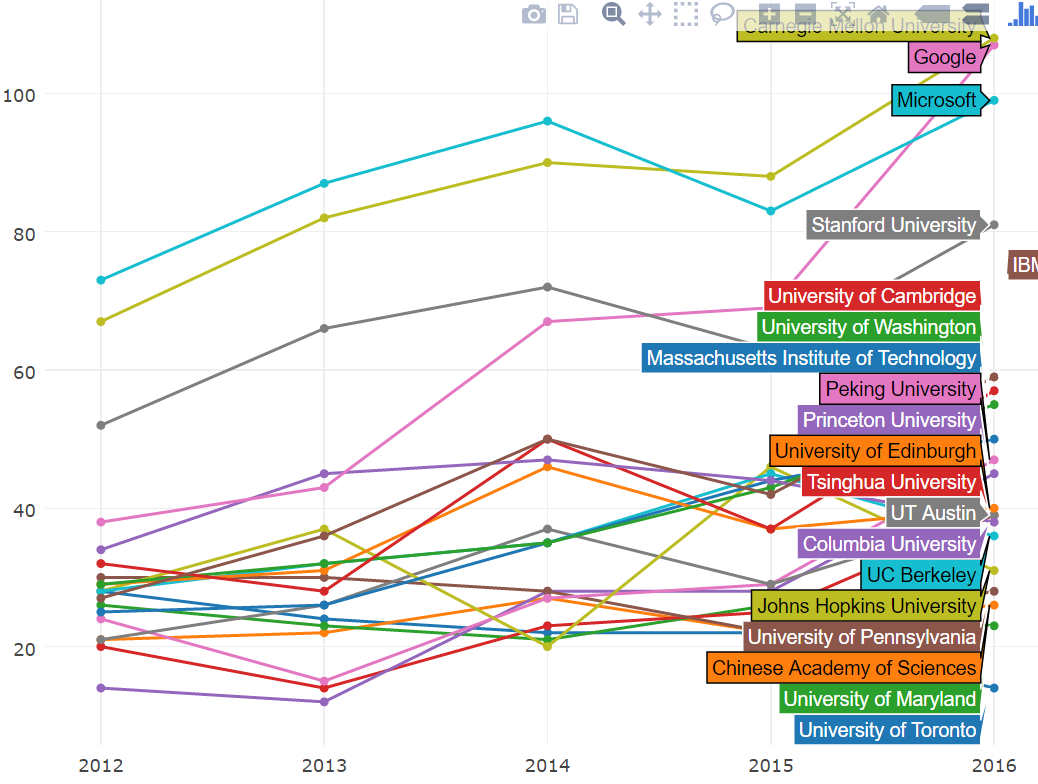
在 2015 年超过微软之后,CMU 继续领跑。但是谷歌也大步跨越,几乎快追上来了。斯坦福的表现也很抢眼,后面跟着 IBM 和剑桥大学。
最后,让我们来看看个人作者:
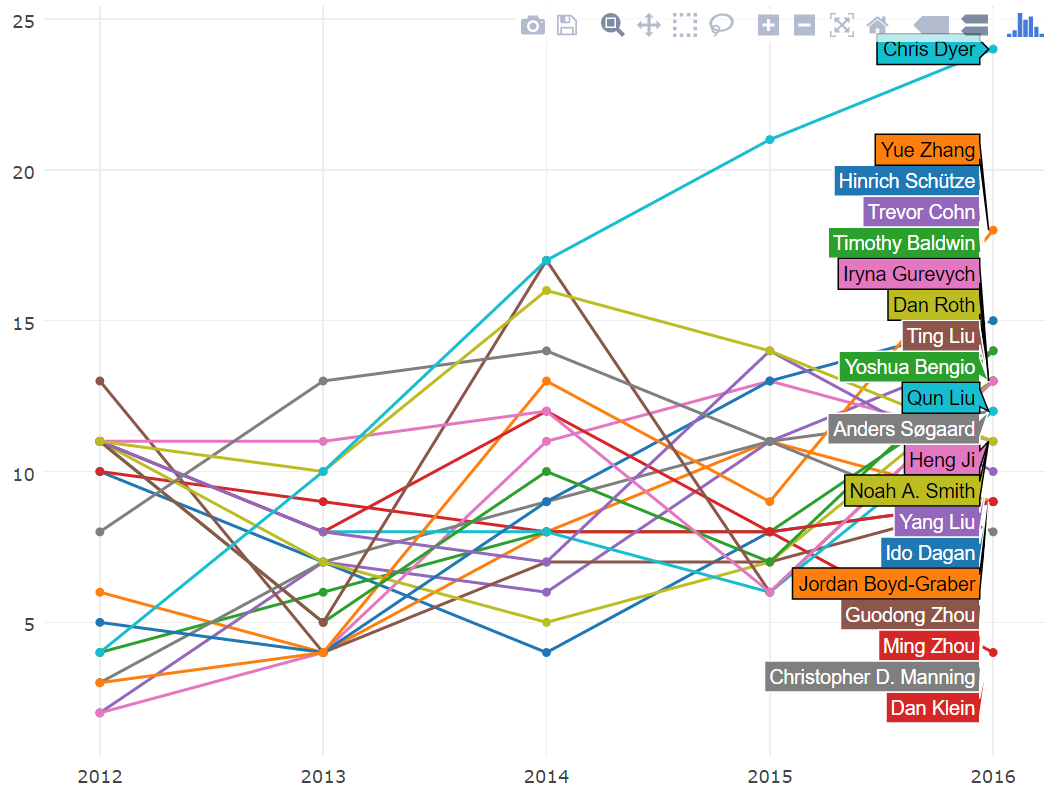
在图上可以看到,Chris Dyer 有一条非常明显的上升曲线。其他过去五年来一直保持增长的作者:Preslav Nakov、Alessandro Moschitti、Yoshua Bengio 和 Anders Søgaard。
NLP(自然语言处理)界有哪些神级人物?
链接:https://www.zhihu.com/question/32318281/answer/55588123
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先想到的不应该是Michael Collins吗……
Michael Collins (Columbia), Jason Eisner (JHU), David Yarowsky (JHU)三位师兄弟(David > Michael > Jason)均师承于Upenn的Mitchell Marcus教授,也就是著名的Penn Treebank的作者。这三位是NLP界公认的大神,研究领域各有侧重。collins/eisner对NLP结构学习领域贡献极大,yarowsky早年研究词义消歧,是著名的yarowsky algorithm的作者,后来做了很多跨语言学习的开创性工作。
Michael Collins的学生中著名的有Terry Koo (Google), Percy Liang (Stanford), Luke Zettlemoyer (UW);Jason Eisner的得意弟子当首推Noah Smith (CMU->UW);David Yarowsky似乎没有什么特别杰出的学生。
Stanford NLP掌门Chris Manning,以《统计自然语言处理基础》一书以及Stanford NLP (toolkit) 而闻名。Dan Jurafsky,著有《语音与语言处理》一书,具有深厚的语言学背景。稍微提一下Manning的学生Richard Socher,近几年声名鹊起,在dl4nlp领域风头一时无两,属年轻一代翘楚。
UCBerkeley的Dan Klein,早些年在无指导学习领域建树颇多。Percy Liang也是他的学生。
UIUC的Dan Roth,Chengxiang Zhai (偏IR);MIT的Regina Barzilay;哦,当然还有Brown大学的Eugene Charniak大神(Charniak parser),Brown大学也可算是没落的贵族了,和UPenn有点儿相似。
欧洲方面,Joakim Nivre (Uppsala University),代表工作是基于转移的依存句法分析。Philipp Koehn,著名机器翻译开源系统Moses作者,14年加入JHU。
当然,在工业界也是NLP群星璀璨。Google有Fernando Pereira坐镇,此外还有Ryan McDonald,Slav Petrov等句法分析领域绕不开的名字;而最近Michael Collins也加入了Google;IBM则有Kenneth Church;提一嘴Tomas Mikolov (Facebook)吧,word2vec作者,虽然他严格意义上并不属于NLP核心圈子,但是不得不说,近两年acl/emnlp近半数文章都给他贡献了citation,能做到这种程度的人极少。
以上我提到的人都是对NLP领域有重要基础性贡献并经过时间考验的(citation超过或者接近1W),除了以上提到的,还有很多非常优秀的学者,比如Kevin Knight,Daniel Marcu, Mark Johnson,Eduard Hovy,Chris Callison-Burch,年轻一代的David Chiang,Hal Daume III等。
暂时想到的就这些人,水平有限,抛砖引玉。相对而言,虽然华人学者近几年在ACL/EMNLP等顶级会议上占据越来越重要的地位,但是对NLP领域具有重要基础性贡献的学者相对还是很少的。
Christopher Manning, Stanford NLP
他的学生:Dan Klein\’s Home Page
然后这位的学生:Percy Liang
然后Stanford另一位NLP大神:Dan Jurafsky
这位在JHU的“亲戚”(误:两位都是俄罗斯/苏联后裔,据说俄语的last name几乎是一样的,现在的不同拼写多半是当年是美国边境官员的杰作):David Yarowsky
(很巧两位都是语言学的大拿)
另一位JHU公认的大神:Jason Eisner
另一位叫Dan的大神:Dan Roth – Main Page
很早很早就开始研究parsing并一战成名的Michael Collins大神,是Percy Liang的另一位师父:Michael Collins
(有空接着更……)
以下摘自wikipedia:
Michael J. Collins (born 4 March 1970) is a researcher in the field of computational linguistics.
His research interests are in natural language processing as well as machine learning and he has made important contributions in statistical parsing and in statistical machine learning. One notable contribution is a state-of-the-art parser for the Penn Wall Street Journal corpus.
His research covers a wide range of topics such as parse re-ranking, tree kernels, semi-supervised learning, machine translation and exponentiated gradient algorithms with a general focus on discriminative models and structured prediction.
Collins worked as a researcher at AT&T Labs between January 1999 and November 2002, and later held the positions of assistant and associate professor at M.I.T. Since January 2011, he has been a professor at Columbia University.
非常喜欢 Michael Collins, 认为他写的paper看得最舒服最爽,犹如沐浴于樱花之中。Jason Eisner确实是厉害,不过看他paper实在太难看懂,写的语言非常抽象,我等屌丝实在难以深入理解。 经过Collins大侠的一些paper才能对Eisner的paper妙语进行理解。
总之,就是超级喜欢Michael Collins. 期待能见到他或者follow 他工作。
此外Ryan Mcdonald也是我十分喜欢的一个NLP researcher. 写的paper虽然木有collins那样妙笔生花,但是也是通俗易懂。
国际计算语言学会ACL Fellow的名单应该就是最高的认可吧?ACL Fellows – ACL Wiki
名单里有35个会士,前面答案里提到的Michael Collins、Christopher Manning也在名单之列。看名字其中有3个是华人/华裔(其中一个是香港人)。
- Dekai Wu,如果没有搞错应该是香港科技大学吴德凯教授,成就是“较早将中文分词方法用于英文词组的分割,并且将英文词组和中文词在机器翻译时对应起来”;
- Hwee Tou Ng,(这个不知道是哪位大神)
- Dekang Lin,林德康老师,前Google高级管理科学家(senior staff research scientist),在加入Google之前是加拿大Alberta大学计算机教授,发表过逾90篇论文、被引用超过12000次,目前做了一家NLP相关的创业公司奇点机智。
国际计算语言学学会仅有的4位华人ACL Fellow之一,林德康教授对自然语言解析和词汇语义做出重要贡献。
&lt;img src=”https://pic4.zhimg.com/v2-caf11d1bcbef377cecb77cd425da7e17_b.png” data-rawwidth=”2106″ data-rawheight=”820″ class=”origin_image zh-lightbox-thumb” width=”2106″ data-original=”https://pic4.zhimg.com/v2-caf11d1bcbef377cecb77cd425da7e17_r.png”&gt;
林德康(Dekang Lin):国际计算语言学学会会士(ACL Fellow)。前Google研究院高级管理科学家(senior staff research scientist),在加入Google之前担任加拿大阿尔伯塔大学计算机教授。他在自然语言处理及理解领域总共发表过90余篇论文,其研究总计被引用超过14000次。1985年毕业于清华大学计算机科学与技术专业,后赴英国求学,又转入加拿大阿尔伯塔大学读取计算机博士。先后任职阿尔伯塔大学副教授、正教授,任教期间主要从事自然语言理解研究.研究成果包括一款基于最简原则的英文语法分析器Minipar和一种用非监督学习同义词组的方法。后在美国Google研究院担任高级管理科学家,是Google搜索问答系统的创始人和技术负责人,领导了一个由科学家及工程师组成的团队,将Google搜索问答系统从一个基础研究项目逐步发展推广成为一个每天回答两千万问题的产品。
&lt;img src=”https://pic2.zhimg.com/v2-d1e5eb95791d639895a923c4ab6a4bb5_b.png” data-rawwidth=”2186″ data-rawheight=”670″ class=”origin_image zh-lightbox-thumb” width=”2186″ data-original=”https://pic2.zhimg.com/v2-d1e5eb95791d639895a923c4ab6a4bb5_r.png”&gt;
林德康教授还多次担任计算语言最高学术机构国际计算语言学学会ACL(Association for Computational Linguistics)的领导职务, 包括:ACL 2002程序委员会联合主席、ACL2011大会主席、ACL 2007北美分会执行委员等。2016年初回国,创办一家研发手机智能助手的公司——奇点机智,2017年4月发布的乐视AI手机宣布搭载奇点机智研发的语音助手——“小不点”。
听说其公司目前正在招聘NLP方面的人才,有意的大神可以投简历至hr@naturali.io,不过面试题有一定难度,不惧挑战的牛人可以尝试一下,反正我有个南大的同学没有通过(老铁,真心不是黑你TT),但还是祝各位好运~
华人两大泰斗张国维博士和李中莹,国外的也有人非常厉害
做 NLP 的应该基本都看过这本书,甚至就是这本入门的吧。。。我在 CU 的那两年好像还是系里的 dean,当年上他的 NLP 的课,final project 在数据集巧合的情况下刷了个比他的 PhD 给出的 benchmark 还要高的 f-score,自我感觉爆棚了交上去,然并卵最后还是没给 A。。。
。
计算机视觉和自然语言处理,哪个更具有发展前景呢,还是各有千
都是非结构化数据,但由于图像是数字信号,处理和特征提取的手段更加丰富和可靠,文本数据提取特征难度较大,比较主流的就是词频矩阵和word2vec,而且由于语言种类很多,并且文本数据普遍质量不好,数据清洗和预处理的工作比较多。
个人以为,NLP现在对于浅层次的特征提取,分类等问题已经比较成熟了,而深层次的语义理解是现在大家研究的热点,也是和深度学习结合密切的方面。比如这两年以来Neural machine translation在机器翻译上相对于以前Phrase-based ML所取得的长足进步。并且现在工业界对于NLP的期待很大,在chatbot,翻译,语义分析,summarization,信息提取和本文分类都有很多尝试。
图像这方面,是最先开始和深度学习合作的领域,现在已有不错的工业化的例子,比如在医疗领域的协助诊断,安防的人脸识别,但都是浅层(并不是指方法简单)的图像处理技术,感觉对于图像深层次含义的理解和挖掘还需要很多努力,估计这方面未来也需要借助自然语言的研究成果。
简单来说,两个都是非常棒的方向,大有可为。图像的工业化方面的实例不少,研究领域也看得到很多前景。NLP初入坑会很多,但应该是之后这几年业界会投资很多的领域,并且一些方向已经快达到了工业化所需要的性能。
1.商业应用来讲,当前nlp更成熟,cv处在探索阶段
nlp的商业应用上,国内的像百度语音、科大讯飞都做得很成熟了。
目前机器视觉主要应用定位、识别、检测和测量,虽说四大块都取得了进展,但受到应用场景、算法的限制,稳定性较差,商业应用并未成熟。
所以从就业来说,短期的几年内cv应该更火一点,现在来看也是这样的。
2.nlu是nlp未来的突破方向
nlp经过十多年的高速发展,精度已经相当高,但是达到99%以后,再提升就显得非常困难。从各大巨头发布的介绍来看,各家事实上是在追求自然语言理解(Natural Language Understanding,NLU)的突破,但是在短期内还未见曙光。因为这方面的突破将会与脑神经科学、认知科学的发展联系密切,所以可能更适合搞研究(比较牛逼的突破性研究)。
3.个人学习来讲,打好数理和编程基础是关键
本身cv和nlp许多算法的原理都是相通的,数学和编程搞好了哪方面都容易吃得开。
恰好两块都有涉猎,CV多一些,NLP和以前的项目关系更大,有过研究但不够深入。
从宏观的讲,CV自然是会更有“前景”一些,从应用面的大小就能看出来,当然这也是一个不负责任的粗略的判断。虽然CV已经有很多年的积累,有了很多成熟的项目和技术,但是个人感觉它还有非常大的空间还没有被发掘出来,
至于NLP,与其将其限制在语言的识别,不如退后一点来看audio progcessing(包括语言和其他声音), audio processing已经在非常多的领域,未来还会在更多的领域得到应用。而且客观地说,目前看来audio processing是一个被低估的方向。因为我们太过于依赖视觉来判断,audio中所包含的信息,值得我们提取的信息还有非常多,但对于我们而言很多都是隐性的,就光是这一点,audio processing就已经有了很大的潜力。
多加一句,从个人发展角度讲,我感觉两个都具有非常大潜力的领域无论大小,都还不至于影响到个人发展,所以更重要的是找到适合自己的方向,选择你更有热情,更感兴趣的方向会让你能够研究的更加深入。
单论发展前景而言的话,从两方面来看,一个是工业界,一个是学术界。
在工业界,我认为nlp的发展前景更大,有更加明朗的商业盈利模式,像推荐,翻译等,然而目前视觉在互联网工业界还没有特别明朗的盈利模式。
在学术界,我认为cv的发展前景更大,因为图像中包含信息更多,理解图像,描述图像很难,另外目前大部分有影响力的工作都是从视觉开始的,DL也是因为CNN的巨大成功而兴起。
大概扫了下,这个问题的回答目前大多来自并没有真正做过NLP的童鞋们……这也基本可以反应整个智能信息处理大环境下CV和NLP相关研究人员的比例有多不均衡。
这里需要强调一点:NLP不是字符串处理,也不是简单的词袋或文本分类。很多任务要做好就需要知道给你的句子或语段到底在讲什么。暂且先不考虑整个篇章级别的信息结构。给定任何一个句子,都可以有相对句长达到指数级数量的结果来解析它的语法结构,然而其中只有一个或极少个是语义上正确的。同时,同一个意思有无穷多种方式可以表达出来,绝大多数表达模式在大家手上的实验数据中可能出现都从来没出现过。Ambiguities(一个表达多种意义)和variations(一个意义多种表达)是NLP的根本难点,短期内不会有任何工作可以提出通用有效的解决方案。
如果你要问发展前景,那短期内必须是vision。原因很简单:就相关问题本身的难点以及目前的支撑技术发展状况来看,想做好NLP的难度远远更高。这其实也是前面有人讲“目前大部分有影响力的工作都是从视觉开始的”的原因。
感觉现在国内NLP的市场还不是很广阔啊,很多公司都不招这方面的人。椰子你认为未来几年国内NLP会引发更多公司关注吗
从远期,视觉无疑能吸收更加庞大的信息量,进入图像理解之后还可以学习创造,我个人认为远期要超过语言类,不过可以转啊,我说的远期至少是十年以后。语言最终会到达极限,比如二十年后,可能语言类的技术完全成熟后会停滞不前。
CV啊,因为NLP现在都没有啃下来(模型、计算资源、数据,都没搞定),CV几个大任务,反正在公开的数据集上都快被啃得差不多了。
如果解决了NLP,也就是自然语言理解的问题,我觉得离AGI也就不差几步了,语言的发明本来就是人类历史的一个飞跃,难度可想而知。在这之前,估计一般人投身进去都是去填坑。CV现在技术基础已经有了,玩点儿应用出成果的可能性还是有的。
目前有的答案大多都是从技术的角度,已经分析的很好了。补充一点,任何技术的发展前景,归根到底是取决于它的应用尤其是商用前景。年轻人如果想选择自己毕生从事的领域,首当其冲要考虑的可能并不是一个东西在技术上还有多少现存问题没解决,而是一个东西在未来20、30甚至50年有没有可能代表一个庞大的市场应用。如果有,那么自然会有无数的技术问题被创造出来,需要无数的人才投入,那么自然而然的好的“发展前景”也就形成了。所谓选错行、站错队,大多数时候即是在这样的选择上出了问题。当然,timing也很重要,最典型的例子就是当年的生命科学….
作为AI的分支领域,CV和NLP根本上来说就是代表了人希望机器能“代替自己看”和“代替自己读和写”(听和说也依赖NLP但隔了一层speech)。短期之内,可能是局限在某些场景下(例如安防人脸识别、人机自动问答)。但长期来说,只要看好AI,就必须认识到CV和NLP会在越来越多的场景下取代人的“看”和“读写”功能。那回过头来评价这两个领域的前景,只需要考虑:这些被CV和NLP所取代的man power,到底代表了多大的生产力、时间和精力投入,就可知这个领域的前景最大可能有多大。再本质一点说,我们作为人,到底有多少时间精力是花在“看”上,多少时间精力花在“听说读写”上,也许就代表了CV和NLP领域本身的终极potential。再脑洞开一点,如果有一种方式,能够计算一下人类平均来说有多少卡路里是消耗在“看”相关的行为上,多少是消耗在“听说读写”相关的行为上,估计就是CV和NLP领域的最终“发展前景”大小了。
AI的发展一定是为了方便人类的生活,而大部分场景下跟人交互最直接、有效的方式是文本,市场空间高下立判。
图像处理会比文本处理需要更多的资源,这点有朋友说过了,具体不再解释。成本越高越不利于前期发展,尤其是小公司、缺经费的实验室。
不过图像相比文本也有很多优点,比如更直观、信息量更大、更容易吸引人眼球等。
初学者会觉得玩图像、语音比文本更酷,也比文本更难处理(不只是刚入门的会有这个误解,微软某应用科学家亲口说他也有过这个误解)。但学习时间越长越发现不是这样,因为图像、语音相对来说更客观、规律性更强,自然语言更具有人的主观、更加抽象、对应的场景更多、更加多义性并且容易歧义。
目前来说,无疑cv发展更成熟,nlp还需进一步取得大突破、挑战也更大,可能需要十年甚至几十年的多人努力,任重道远但也恰恰提供了更大的发展空间。
不过,cv和nlp很多模型、方法都是相通的,大同小异。未来推动人工智能发展的不仅仅是cv,也不仅仅是nlp、语音识别,而是多个领域的共同发展。
最后,cv和nlp都是好方向,选那个都行,根据兴趣决定就好,把兴趣当职业的人最幸福也最有效率!祝好!
链接:https://www.zhihu.com/question/49432647/answer/144958145
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
先说学术圈
视觉大热过后现在已经进入了一个瓶颈期,现有数据上比较重要的问题都已经做的差不多了。视觉有三大问题:分类(classification)、检测(detection)、分割(segmentation)。
分类方面,imagenet已经MNIST化,折腾半天提升半个点实在没什么意思。检测方面有RCNN和SSD两个大方向,骨架已经搭好,剩下的就是填trick了。分割基本上是dilated convolution/upsampling的各种变种,也是过几个月加几个trick提高一个点的模式。
视频理论上是未来的方向,但是似乎视频需要的计算量比图片大得多,目前还没有什么突破,前途不明朗。可能还要等核弹厂挤两年牙膏。所以现在大家都在搞GAN啊pix2pix啊这种看起来炫酷但是无法量化评价的东西,虽然看起来百花齐放但是很难说前途明朗。
自然语言处理有些不温不火,虽然深度学习在翻译等方面带来一些进步但是并没有翻天覆地的感觉。由于自然语言先天的高度结构化、高度抽象、数据量(相对)小的特点,糙快猛的神经网络有些施展不开。如果说视觉已经过气了,那么自然语言就是还没火起来。未来应该是有前途的方向,但是这个未来有多远还不好说。
再说工业和应用方向
视觉在学术圈退火意味着技术已经比较成熟,正是工业界大干快上的好时机。但是工业应用想要成功,必须深耕一个垂直市场,比如自动驾驶,医疗图像,安全监控,其中医疗图像我认为是最有潜力的方向。想要做一个通用平台搞分类监测的公司基本都会遇到商业模式不清晰,竞争激烈,变现困难的问题,最好的下场也就是被大厂收购或者包养。
自然语言处理也有一些商业机会,但是想靠深度学习横扫天下不现实。需要新老方法的结合以及深厚的经验积累。自然语言更是需要深耕垂直市场,通用算法完全看不到商业模式,像聊天机器人啊自动翻译这种东西都是大厂用来提高知名度的,无法变现。垂直市场方面我看好法律应用,助理律师的很多工作,比如对比判例、专利这种,完全可以自动化。
NLP由于特征较为高层,因此现有算法处理起来比较容易,发展比较成熟,像文档分类等任务,简单的特征可以达到非常高的准确率。但是在享受完基于统计的浅层语义果实以后,下一步的深层语义理解则困难重重。像机器翻译,对话系统等依赖深层语义理解的任务,目前的系统距离人类水平,尚有不小的差距。
CV由于特征较为底层,因此之前需要人工设计大量特征,效果也不尽如人意,所以发展没有NLP成熟。但是深度学习技术在特征提取上的具大优势,为CV的发展开启了一个崭新的时代。像图像分类等任务,已经达到接近甚至超过人类的水平,而之前想都不敢想的图像生成,视频生成等,也不断有激动人心的成果涌现。
NLP相当于已经达到90分,想提高到99分,困难很大,而CV之前也许只有60分,因此提高到90分非常容易,这也是目前CV迅速发展的原因。
不过由于深度学习技术的巨大潜力,NLP领域逐渐被深度学习席卷,大家希望能借助深度学习技术,向99分发起冲刺,因此NLP领域也非常有前景。
从发展上,两个领域目前都非常有前景,没有必要一定要分出个高下。从技术上,它们都逐渐被深度学习统治,像描述生成图片和图片生成描述这样的交叉任务也越来越多,有相当多互相借鉴的地方。从个人方向选择角度,我建议以个人兴趣作为第一出发点,无论选择哪个方向都挺好。而且有了深度学习技术的基础以后,想转另外一个方向,也不是很难。
先说我的观点:计算机视觉将越来越融合自然语言处理。
因为我自己是计算机视觉研究背景,所以下面主要讨论一下自然语言处理在计算机视觉中的几个应用。
首先,自然语言给计算机视觉的图片数据带来了结构化和语义化。自然语言中一个“词”代表某个概念或者类,比如说“猫”和“动物”。通过语义关系,利用这些词可以很容易建立一个语义结构关系网。WordNet是目前最大的语义结构关系,其中的hypernym/hyponym代表了两个词之间的语义关系。在计算机视觉中,由像素组成的图片本身是个非常高维的数据,比如说800×600像素的图片,是个高达480000的向量。图片空间里最稀缺的是对这些高维数据的语义结构化。ImageNet (ImageNet Tree View)的重要贡献是基于WordNet建立的图片语义结构。其中每个synset有成百上千张所属类别的图片,这样ImageNet就完成了对一千多万张图片的语义性的归类和描述。
所以,对图片数据的语义化和结构化,可以说是自然语言处理在计算机视觉里的一个首要应用。随后的各种基于机器学习的图片识别算法,都是为了预测图片的语义标定。Deep learning本身也是representation learning,说到底就是在图片高维空间里面建立更好的表征,使得这些表征对语义标定有更好的区分和映射。
图片的语义标定本身可以衍生出很多应用,这里我举两个比较有意思的任务:Entry-level recognition和Zero-shot learning。 Entry-level recognition(From Large Scale Image Categorization to Entry-Level Categories)主要是分析wordnet上的synset到entry-level description的关系,比如说一张海豚的图,Wordnet里面给的是grampus griseus,而人们普遍会用dolphin去描述这张图,怎么给两者建立联系是entry-level recognition要解决的问题。
Zero-shot learning解决的问题是,如果某个类别没有任何训练图片数据,如何去识别这个类别。因为世界上的词语太多,对每个词语对应的概念都收集图片训练数据显然不现实。zero-shot learning的大致做法是,利用当前没有任何图片数据的标定与之前有图片数据的标定的语义相似度,来建立语义标定之间的关联。自然语言处理的word embedding也得到了应用。Zero-shot learning的一些代表作,比如说DeViSE(http://papers.nips.cc/paper/5204-devise-a-deep-visual-semantic-embedding-model.pdf), semantic codes(http://papers.nips.cc/paper/3650-zero-shot-learning-with-semantic-output-codes.pdf), domain-adaptation(http://papers.nips.cc/paper/5027-zero-shot-learning-through-cross-modal-transfer.pdf)。Zero-shot learning的最新进展可以参见最近的一次ECCV‘16 Tutorial(Zero-Shot Learning Tutorial | ECCV 2016)。
这两三年紧密结合自然语言处理的视觉任务也越来越多。2014年和2015年大热的基于CNN+RNN的看图说话(Image Captioning):给任意一张图,系统可以输出语句来描述这幅图里的内容。Microsoft,Google,Stanford等大厂都有concurrent work,一些代表作如Vinyals et al. from Google (CNN + LSTM) 和 Karpathy and Fei-Fei from Stanford (CNN + RNN)。New York TImes这篇科普文章还不错,(https://www.nytimes.com/2014/11/18/science/researchers-announce-breakthrough-in-content-recognition-software.html?_r=0)。这里有篇挺有意思的来自Ross GIrshick和Larry Zitnick的论文https://arxiv.org/pdf/1505.04467.pdf,里面用nearest neighbor retrieval的土办法取得了可以跟那些基于RNN/LSTM系统不相上下的结果。由此可以看出,目前的image captioning系统基本还是在做简单的retrieval和template matching。Image captioning大火之后这两年这个研究方向好像就没啥相关论文了,前阵子Microsoft Research做了篇Visual Storytelling的工作(https://www.microsoft.com/en-us/research/wp-content/uploads/2016/06/visionToLanguage2015_DataRelease-1.pdf),并提供了个dataset(Visual Storytelling Dataset)。
随后,2015年和2016年图片问答Visual Question Answering (VQA)又大热。VQA是看图说话的进阶应用:以前看图说话是给张图,系统输出语句描述,而VQA更强调互动,人们可以基于给定的图片输入问题,识别系统要给出问题的答案。目前最大的dataset是基于COCO的VQA dataset(Visual Question Answering),最近出了v2.0版本。CVPR’16搞了个VQA challenge & Workshop(Visual Question Answering),其页面里有挺多资料可供学习。我之前自己也做过一阵子VQA的工作,提出了一个非常简单的baseline。这里是一个可供测试的demo(Demo for Visual Question Answering),代码和report也公布了,感兴趣的同学可以看看。当时这个baseline跟那些基于RNN的复杂模型比起来也毫不逊色,侧面证明了目前VQA系统到跟人一样真正理解和回答问题还有非常长的一段距离。Facebook AI Research前两个月公布了一个新的数据库(https://arxiv.org/pdf/1612.06890.pdf),用于诊断visual reasoning系统。我自己挺喜欢这样的分析性质的论文,推荐阅读。
另外,Feifei-Li老师组新建立的Visual Genome Dataset (VisualGenome),其实也是力求让计算机视觉更好地跟自然语言处理里的知识库和语义结构更进一步融合起来。
由此可见,计算机视觉和自然语言处理并不是隔阂的两个研究方向。两者的未来发展会借助各自的优势齐头并进,融合到General AI的框架之下。未来又会产生怎样的新研究问题,我充满期待。
NG的课在网易有字幕版,是在斯坦福上课的实拍,比cousera的更深,因为上课的是本科生(没记错的话),比较适合入门。不过数学的底子有要求,特别是线代。
话说回来,要做这一行,英语非常重要,楼主你得学英语了,读和听要搞定,最低限度读要没问题。另外,既然数据挖掘都是零基础,先把统计补一补。。。
一个小修正,Andrew的Machine Learning在S是graduate course,虽然有本科生毕竟还是master & PhD为主,尽管确实是什么背景的都有。。。所以深一些也是正常(话说Coursera上如果也和他的CS229难度一样恐怕要损失不少用户的吧。。。)
这边我就仅仅针对该如何入门这个问题回答这个问题吧。
既然上面已经有很多人给出了很好的回答,这边我给出两个参考,希望对你有帮助。
如果自学的话,这边我顺带给出我整理的自学路径,如果你认为有比这个更加好的参考,欢迎一起分享。
自然语言处理整理:
JustFollowUs/Natural-Language-Processing
机器学习整理:
JustFollowUs/Machine-Learning
数据挖掘相对简单。
吴恩达的课已经很简单了,本科低年级的学生都可以完成。
看3遍统计学习方法,然后把所有算法实现。
ok,然后你再来问,自己是去百度,还是阿里。
先去国内前20,米国前100的学校混一个数学/统计/计算机,并且和数据相关的学位在说吧
机器学习的职位,目前供需严重不平衡。很多人调过一两个库的几个算法就堂而皇之的把机器学习加到简历里面去了,滥竽充数的现象很严重。所以对于新人来说,没有学历基本上就是被秒刷的命。
知乎首答,写个短的。本人现在大三,计算机本科。目前在国立台湾大学做交换生。
第一个和第三个问题我不懂,坐等大牛回答。我只结合自己的情况说一下第二个问题。
NG的课程我以前看过一部分,讲的风格我觉得在干货之前都比较好懂(笑)。但是天朝的学子接受起来可能有困难。台湾大学的林轩田老师的machine learning至少在本科生教育上做的很好。他们有个team经常去各种比赛上刷奖。我目前在修他的机器学习课程,觉得质量不错。现在coursera上也有同步课程。
传送门:Coursera.org
个人觉得机器学习的很多方法都是从统计学上借鉴过来的,所以现在在补统计学的知识。同时作为一个理论性比较强的领域,线性代数和高等数学的知识起码是要具备的(至少人家用矩阵写个公式再做梯度下降你要看明白是在干嘛)。
我在大陆的mentor是做机器翻译的。我说我感觉这个领域现在是步履维艰,结果被我mentor教育了。现在微博数据好像挺好用的,数据抓过来跑一跑能出点票房预测什么的(其实非常吊了,反正我不会QAQ)。记得有本Python自然语言处理,NLTK还自带语料库,用来入门不错。起码要熟悉正则语言,再学个脚本语言。虽然Python已经很好用了,你要不要考虑下linux shell。以后混不下去了可以去给运维打下手。这东西又不是C语言,入门又没什么用,所以没什么30天精通NLP之类。而且自己研究NLP也面临着许多问题。首先你自己没有可研究的问题,没有动力。其次,研究资料也不算好找(虽然好像有免费的)。去年mentor给了我个5M的树库,还嘱咐我说是有版权的,不能给别人。(笑)
其实我自己都怀疑读研的时候要不要换个方向(请行里行外的师兄来劝我两句,要不要去做别的啊!!QAQ)
最后说一句,机器学习之类我觉得是国内大学所谓计算机专业比较偏向CS而不是CE的部分了。虽然工程性很重要,但是和软件工程什么的比起来Science的成分总要更大一些。我是比较喜欢理学才来学这个东西。当然我的认识可能不对,我姑妄说之。
《统计学习方法》是指李航那本?不适合初学者,术语太多,干货满满,在introduction那一章连个例子都舍不得举,简直看不下去(我没说这本书不好,只是不适合初学者,等你学的差不多了以后再来看这本书会有长进的)。
Andrew Ng的课指的是什么?网易公开课还是Coursera上的公开课?前者上不下去的话正常。后者比前者压缩掉了很多内容,把长视频切成了短视频,还有作业等互动环节,听不懂可以开字幕。要是这样你都听不下去,要么说明你该学英语了,要么说明你该学数学了:把机器学习的三驾马车——高等数学、线性代数、概率统计——好好补一补吧。
我不知道机器学习、数据挖掘、自然语言处理哪一个更有潜力,但我觉得你得先把数学和英语学好才能有潜力。
链接:https://www.zhihu.com/question/26391679/answer/34169968
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主的问题太多了,每个展开都可以讲很多~
作为自然语言处理(NLP)方向的研究生,我来回答一下题主关于自然语言处理如何入门的问题吧,最后再YY一下自然语言处理的前途~
有点话我想说在前头:
不管学什么东西,都要跟大牛去学,真正的大牛可以把一件事解释的清清楚楚。
If you can\’t explain it simply, you don\’t understand it well enough.
跟大牛学东西,你不会觉得难,一切都觉得很自然,顺利成章的就掌握了整套的知识。
不过很遗憾,大牛毕竟是少数,愿意教别人的大牛更少,所以如果遇到,就不要强求语言了吧~
开始进入正题,我将介绍如何从零基础入门到基本达到NLP前沿:
———-NLP零基础入门———-
首推资料以及唯一的资料:
Columbia University, Micheal Collins教授的自然语言课程
链接>> Michael Collins
Michael Collins,绝对的大牛,我心目中的偶像,这门课是我见过讲NLP最最最清楚的!尤其是他的讲义!
Collins的讲义,没有跳步,每一步逻辑都无比自然,所有的缩写在第一次出现时都有全拼,公式角标是我见过的最顺眼的(不像有的论文公式角标反人类啊),而且公式角标完全正确(太多论文的公式角标有这样那样的错标,这种时候真是坑死人了,读个论文跟破译密码似的),而且几乎不涉及矩阵表示……(初学者可能不习惯矩阵表示吧)。
最关键的是,Collins的语言措辞真是超级顺畅,没有长难句,没有装逼句,没有语法错误以及偏难怪的表示(学术圈大都是死理工科宅,语文能这么好真实太难得了)。《数学之美》的作者吴军博士在书中评价Collins的博士论文语言如小说般流畅,其写作功底可见一般。
举两个例子,如果有时间,不妨亲自体验下,静下心来读一读,我相信即使是零基础的人也是能感受到大师的魅力的。
1.语言模型(Language Model)
http://www.cs.columbia.edu/~mcollins/lm-spring2013.pdf
2.隐马尔可夫模型与序列标注问题(Tagging Problems and Hidden Markov Models)
http://www.cs.columbia.edu/~mcollins/hmms-spring2013.pdf
现在Michael Collins在coursera上也开了公开课,视频免费看
链接>> Coursera
比看讲义更清晰,虽然没有字幕,但是不妨一试,因为讲的真的好清楚。
其在句法分析与机器翻译部分的讲解是绝对的经典。
如果能把Collins的课跟下来,讲义看下来,那么你已经掌握了NLP的主要技术与现状了。
应该可以看懂部分论文了,你已经入门了。
———-NLP进阶———-
Collins的NLP课程虽然讲的清晰,不过有些比较重要的前沿的内容没有涉及(应该是为了突出重点做了取舍),比如语言模型的KN平滑算法等。
此外,Collins的课程更注重于NLP所依赖的基础算法,而对于这些算法的某些重要应用并没涉及,比如虽然讲了序列标注的算法隐马尔可夫模型,条件随机场模型,最大熵模型,但是并没有讲如何用这些算法来做命名实体识别、语义标注等。
Stanford NLP组在coursera的这个课程很好的对Collins的课进行了补充。
链接>> Coursera
本课程偏算法的应用,算法的实现过的很快,不过上完Collins的课后再上感觉刚刚好~
(这两门课是Coursera上仅有的两门NLP课,不得不佩服Coursera上的课都是精品啊!)
———-进阶前沿———-
上完以上两个课后,NLP的主要技术与实现细节就应该都清楚了, 离前沿已经很近了,读论文已经没问题了。
想要继续进阶前沿,就要读论文了。
NLP比起其它领域的一个最大的好处,此时就显现出来了,NLP领域的所有国际会议期刊论文都是可以免费下载的!而且有专人整理维护,每篇论文的bibtex也是相当清晰详细。
链接>> ACL Anthology
关于NLP都有哪些研究方向,哪些比较热门,可以参考:当前国内外在自然语言处理领域的研究热点&难点? – White Pillow 的回答
NLP是会议主导,最前沿的工作都会优先发表在会议上。关于哪个会议档次比较高,可以参考谷歌给出的会议排名:
Top conference页面
也可以参考各个会议的录稿率(一般来说越低表示会议档次越高):
Conference acceptance rates
基本上大家公认的NLP最顶级的会议为ACL,可以优先看ACL的论文。
————————-
最后简单谈一下这三者哪个更有发展潜力……作为一个NLP领域的研究生,当然要说NLP领域有潜力啦!
这里YY几个未来可能会热门的NLP的应用:
语法纠错
目前文档编辑器(比如Word)只能做单词拼写错误识别,语法级别的错误还无能为力。现在学术领域最好的语法纠错系统的正确率已经可以接近50%了,部分细分错误可以做到80%以上,转化成产品的话很有吸引力吧~无论是增强文档编辑器的功能还是作为教学软件更正英语学习者的写作错误。
结构化信息抽取
输入一篇文章,输出的是产品名、售价,或者活动名、时间、地点等结构化的信息。NLP相关的研究很多,不过产品目前看并不多,我也不是研究这个的,不知瓶颈在哪儿。不过想象未来互联网信息大量的结构化、语义化,那时的搜索效率绝对比现在翻番啊~
语义理解
这个目前做的并不好,但已经有siri等一票语音助手了,也有watson这种逆天的专家系统了。继续研究下去,虽然离人工智能还相去甚远,但是离真正好用的智能助手估计也不远了。那时生活方式会再次改变。即使做不到这么玄乎,大大改进搜索体验是肯定能做到的~搜索引擎公司在这方面的投入肯定会是巨大的。
机器翻译
这个不多说了,目前一直在缓慢进步中~我们已经能从中获益,看越南网页,看阿拉伯网页,猜个大概意思没问题了。此外,口语级别的简单句的翻译目前的效果已经很好了,潜在的商业价值也是巨大的。
不过……在可预见的近几年,对于各大公司发展更有帮助的估计还是机器学习与数据挖掘,以上我YY的那些目前大都还在实验室里……目前能给公司带来实际价值的更多还是推荐系统、顾客喜好分析、股票走势预测等机器学习与数据挖掘应用~
现在国内IT互联网公司大部分NLP和IR人才被BAT公司垄断,导致市面上的优秀NLP人才极少,因此很多创业公司紧缺这方面的人才。从人工智能发展的趋势来看,我认为这是一个不错的领域,可以为之奋斗一生。
学位都是浮云,关键还是实力。
NLP几乎是互联网机器学习业务的必备技能。因为互联网内容最大比例的是文本。NLP挺好找工作的,但是最好机器学习的内容学全一点,毕竟实际工作内容是很多类型的,所以NLP是比较必要但不充分。
根据付出就是感觉薪资不太给力 ,还有这东西不好创业或者接私活。但是单纯上班打工做做还是比较好的30~6,70万
nlp人才非常紧缺,这个不像是android,c#这种东西三个月可以培训出来的。机器学习这类工作即使再热门,也不会有太多的竞争者,这个不是北大青鸟可以培训出来的。普通的开发校招8-15k,nlp能给到15-20k,工作几年的更能拿到40w-100w的年薪。找这方面的工作可以去NLPJob看看
目前看来,nlp的人在国内找工作机会比较窄,主要是BAT特别是百度比较多,然后美图,新浪,搜狗,乐视,360这些公司里有一些,再就是一些发展成熟的创业公司零零星星有一些团队。作为一个猎头,经常会和在湾区的 data scientist 聊过,他们还是希望在那边多待几年,将内心建设祖国的伟大中国梦再憋一憋。
Fintech 中国50强企业 数库科技上海公司 招聘自然语言处理工程师:自然语言处理工程师岗位要求:1.语料库维护;2.知识图谱构建与维护。岗位要求:1.熟悉Python或Java开发;2.有自然语言处理相关经验,如分词、词性标注、实体识别、情感分析;3.有知识图谱构建相关经验;4.熟悉机器学习算法。有意者请发简历到hr@chinascope.com,欢迎你的加入!
作者:刘知远
先说结论:哈工大的SCIR实验室绝对是国内数一数二的顶尖NLP实验室。</b></p><p>学术方面:</p><noscript><img src=\"https://pic1.zhimg.com/v2-b803f387266502f6f57ffbb9521027c4_b.png\" data-rawwidth=\"389\" data-rawheight=\"192\" class=\"content_image\" width=\"389\"></noscript><img src=\"//zhstatic.zhihu.com/assets/zhihu/ztext/whitedot.jpg\" data-rawwidth=\"389\" data-rawheight=\"192\" class=\"content_image lazy\" width=\"389\" data-actualsrc=\"https://pic1.zhimg.com/v2-b803f387266502f6f57ffbb9521027c4_b.png\"><br><p>刘挺教授在google scholar上总引用为6529次,2012年来共引用4114次,<b>目前我还不知道国内哪位NLP方向的教授的引用量比他更高</b>,如有知友发现,烦请告知。</p><br><noscript><img src=\"https://pic4.zhimg.com/v2-be972138cf4abf28b65351d5a004e21f_b.png\" data-rawwidth=\"693\" data-rawheight=\"565\" class=\"origin_image zh-lightbox-thumb\" width=\"693\" data-original=\"https://pic4.zhimg.com/v2-be972138cf4abf28b65351d5a004e21f_r.png\"></noscript><img src=\"//zhstatic.zhihu.com/assets/zhihu/ztext/whitedot.jpg\" data-rawwidth=\"693\" data-rawheight=\"565\" class=\"origin_image zh-lightbox-thumb lazy\" width=\"693\" data-original=\"https://pic4.zhimg.com/v2-be972138cf4abf28b65351d5a004e21f_r.png\" data-actualsrc=\"https://pic4.zhimg.com/v2-be972138cf4abf28b65351d5a004e21f_b.png\"><p>据剑桥大学高级研究员 Marek Rei 统计(<a href=\"https://link.zhihu.com/?target=http%3A//www.marekrei.com/blog/nlp-and-ml-publications-looking-back-at-2016/\" class=\" wrap external\" target=\"_blank\" rel=\"nofollow noreferrer\">NLP and ML Publications – Looking Back at 2016 – Marek Rei<i class=\"icon-external\"></i></a>),2016年,<b>刘挺教授的顶会论文总数量位居业界第九,第六是神一样的Bengio。</b>(注:本人不了解这些会议具体内容,若有贻笑大方之处,还请轻喷)</p><p>工业界方面:</p><p>百度:百度副总裁,<b>AI技术平台体系总负责人王海峰博士</b>毕业于哈工大,目前是SCIR实验室的兼职教授,王海峰博士是ACL50多年历史上唯一出任过主席的华人。据不完全统计,该实验室在百度的毕业生约为20位,其中包李彦宏的开门弟子(博士后),百度高级研究院赵世奇博士等。</p><p>腾讯:SCIR实验室是<b>腾讯AL Lab最早的联合实验室</b>,<b>腾讯AI平台部NLP技术中心副总监周连强</b>就是SCIR实验室07级的硕士生,刘挺教授还是<b>腾讯AI Lab特聘学术顾问</b>(<a href=\"https://link.zhihu.com/?target=http%3A//ai.tencent.com/ailab/%25E8%2585%25BE%25E8%25AE%25AF-%25E5%2593%2588%25E5%25B0%2594%25E6%25BB%25A8%25E5%25B7%25A5%25E4%25B8%259A%25E5%25A4%25A7%25E5%25AD%25A6%25E8%2581%2594%25E5%2590%2588%25E5%25AE%259E%25E9%25AA%258C%25E5%25AE%25A4.html\" class=\" wrap external\" target=\"_blank\" rel=\"nofollow noreferrer\">腾讯 AI Lab – 腾讯人工智能实验室官网<i class=\"icon-external\"></i></a>)。据不完全统计,该实验室在腾讯的毕业生约为25位。</p><p>阿里:<b>自然语言处理部总监郎君</b>为SCIR实验室的06级博士生。据不完全统计,该实验室在阿里的毕业生约为10位。</p><p>微软:微软和国内的很多高校有联合实验室 (详见<a href=\"https://link.zhihu.com/?target=http%3A//www.msra.cn/zh-cn/connections/jointlab/default.aspx\" class=\" wrap external\" target=\"_blank\" rel=\"nofollow noreferrer\">联合实验室 – 微软亚洲研究院<i class=\"icon-external\"></i></a>),但NLP方向的联合实验室只有清华和哈工大两家,在微软亚洲研究院的门户网站上,<b>共列出研究人员11名,其中有5人是在哈工大获得博士学位。</b></p><p>(注:微软哈工大联合实验室是哈工大机器智能实验室,此实验室并非之前说的SCIR实验室,该实验室有著名的李生教授坐镇,其官网为 <a href=\"https://link.zhihu.com/?target=http%3A//mitlab.hit.edu.cn\" class=\" external\" target=\"_blank\" rel=\"nofollow noreferrer\"><span class=\"invisible\">http://</span><span class=\"visible\">mitlab.hit.edu.cn</span><span class=\"invisible\"></span><i class=\"icon-external\"></i></a> ,由于鄙人不了解该实验室,恕不详细介绍,知友可自行了解。)</p><p>科大讯飞:科大讯飞是亚太地区最大的语音上市公司,在智能语音技术的多个领域均处于业界领先地位。科大讯飞与哈工大有语言认知计算联合实验室(<a href=\"https://link.zhihu.com/?target=http%3A//ir.hit.edu.cn/1348.html\" class=\" wrap external\" target=\"_blank\" rel=\"nofollow noreferrer\">哈尔滨工业大学社会计算与信息检索研究中心 – 理解语言,认知社会 &amp;amp;quot; 科大讯飞与哈工大联合创建语言认知计算联合实验室<i class=\"icon-external\"></i></a>),<b>刘挺担任实验室主任。</b></p><p>SCIR实验室官方网站:<a href=\"https://link.zhihu.com/?target=http%3A//ir.hit.edu.cn/\" class=\" wrap external\" target=\"_blank\" rel=\"nofollow noreferrer\">哈尔滨工业大学社会计算与信息检索研究中心 – 理解语言,认知社会<i class=\"icon-external\"></i></a></p><p>此外,顺便再说一句,国内大部分顶级高校的研究生都是三年或两年半,哈工大只要两年哦~</p><p>两年你买不了吃亏,两年你买不了上当~</p><p>而且SCIR实验室的老师都超级nice的~</p><p>欢迎各位来SCIR!</p><p>希望刘教授收留我 (ಥ﹏ಥ) </p><p>评论区有询问实验室招生情况的,这个我也不是特别了解,请向ir实验室的秘书李冰咨询,她的邮箱请去实验室网站上找
国内自然语言处理学者众多,很难一一枚举。我就简单罗列一下我们系的几位相关老师,方便大家了解。都是我随便写的,没有字斟句酌,排名也不分先后,如有疏漏和错误多请指出,不要见怪。:)孙茂松教授:早年以中文分词研究成果闻名,计算机系人智所自然语言处理课题组(THUNLP)的学术带头人,是国内自然语言处理唯一的一级学会、中国中文信息学会副理事长,研究兴趣比较广泛,涵盖中文信息处理、社会计算、信息检索等。马少平教授:计算机系人智所信息检索课题组(THUIR)的学术带头人,是中国人工智能学会副理事长,研究兴趣偏重搜索引擎,为本科生上《人工智能导论》必修课,深受欢迎。朱小燕教授:计算机系智能技术与系统国家重点实验室(即人智所)主任,信息获取课题组的学术带头人,研究兴趣偏重问答系统、情感分析、文档摘要等。李涓子教授:计算机系软件所知识工程课题组的学术带头人,研究兴趣偏重知识图谱与知识工程。研制推出的XLORE是国内屈指可数的大规模知识图谱。唐杰副教授:数据挖掘领域的青年学者,主要研究社会网络分析、社会计算和数据挖掘,也会做一些自然语言处理研究。刘洋副教授:自然语言处理领域的青年学者,主要研究统计机器翻译。我有幸跟刘洋老师一个办公室,非常佩服他的学术品味、工作态度和为人。张敏副教授:信息检索领域的青年学者,主要研究推荐系统与情感分析。是信息检索与数据挖掘的著名会议WSDM 2017的PC主席。刘奕群副教授:信息检索领域的青年学者,主要研究搜索引擎用户的行为建模,近年来用眼动手段开展研究工作,得到较多的学术关注。是信息检索顶级会议SIGIR 2018的PC主席。朱军副教授:机器学习领域的青年学者,主要研究统计机器学习,也会在自然语言处理和知识获取等方面做一些研究,例如比较有名的StatSnowball,MedLDA等。黄民烈副教授:自然语言处理领域的青年学者,过去主要研究情感分析、文档摘要,近年来开始在智能问答和人机对话发力。贾珈副教授:多媒体处理领域的青年学者,早期研究语音,现在偏重社会媒体的多媒体处理,进行情感计算等研究,研制了很多很有意思的应用(如衣服搭配推荐等)。喻纯副研究员:人机交互领域的青年学者,研究面向文本输入等方面的交互设计,例如如何设计更便捷的输入法等。从我们自然语言处理领域来看创意很有意思、脑洞很大,例如在VR中通过头的摆动输入文本。刘知远助理教授(也就是我):早年研究关键词抽取和社会标签推荐,现在偏重知识图谱、表示学习和社会计算。值得一提的是,从去年开始我们系开始实施人事制度改革,采取国际的Tenure Track(教学研究系列)制度,进入该系列的老师均有招收博士生的资格,极大的提高了青年教师的生产力。因此,以上绝大部分老师均有招生资格,欢迎对这些方向感兴趣的同学联系他们。如果有还想了解的信息,可以评论告诉我,我尽量提供或转告相关老师。:)
作者:鱼小贱
说一下自己听说过的比较牛的团队或者个人吧,可能不全面,还请谅解。(排名不分先后)学术界清华大学自然语言处理与人文计算实验室(欢迎来到清华大学自然语言处理与社会人文计算实验室):清华计算机系前院长孙茂松教授是他们的leader北京大学计算语言学教育部重点实验室(北京大学计算语言学教育部重点实验室):是北大计算机学科比较有实力的一个研究方向之一中科院计算所自然语言处理研究组(欢迎来到中科院计算所自然语言处理组网站):尤其专长在机器翻译领域,组长为刘群研究员,大家常使用的中文分词工具ICTCLAS就是他们参与开发的哈尔滨工业大学:实力也很强,实验室查了一下感觉好乱,主要有:智能技术与自然语言处理研究室(ITNLP)、哈工大语言语音教育部-微软重点实验室(哈工大语言语音教育部)、(哈尔滨工业大学社会计算与信息检索研究中心)哈尔滨工业大学社会计算与信息检索研究中心;现任中文信息学会理事长李生教授就是哈工大的、下面提到的现任ACL主席王海峰先生也是哈工大毕业的;而且值得一提的是,哈工大虽然远在最东北地区,但是和工业界,像微软、百度、科大讯飞等都有着紧密的联系。工业界像知名搜索引擎公司在这些方面应该都有不俗的积累搜狗公司百度公司:现任副总裁王海峰先生是自然语言处理领域世界上影响力最大、也最具活力的国际学术组织ACL(Association for Computational Linguistics)50多年历史上唯一的华人主席。微软亚洲研究院科大讯飞:国内专业做中文语音、文字产品研发的企业,是目前国内最大的智能语音技术提供商。
国内NLP三大重镇:清华、哈工大、中科院(自动化所,计算所)。另外一些NLP比较强的高校:复旦大学黄萱菁、邱锡鹏组,苏州大学周国栋、朱巧明组,北京大学李素建组,东北大学朱靖波组等。
http://www.cs.columbia.edu/~mcollins/notes-spring2013.html
https://github.com/ZixuanKe/Ch2r_ood_understanding
https://www.coursera.org/browse?languages=en&source=deprecated_spark_cdp