一文带你了解文字识别
摘要:本文主要介绍文字检测和文字识别作为计算机视觉一部分的重要性,基本知识,面临的挑战,以及部分最新的成果。
人类在认识了解世界的信息中91%来自视觉,同样计算机视觉是机器认知世界的基础,也是人工智能研究的热点,文字识别也是人工智能的重要研究方向。在我们生活当中,文字是无处不在的,我们的衣食住行都是离不开它的。
文字的价值
首先,文字并非自然产生,而是人类特有的造物,是高层语义信息的载体。文字从整个文化的角度来讲也是非常重要的,人类的文明离不开文字,文字是我们学习知识、传播信息、记录思想很重要的载体,没有文字人类的文明无从谈起。比如说王羲之的“兰亭序”,不只是文化作品,也是人类历史上璀璨的明珠之一;再比如诗经,通过诗经我们既可以学习它朗朗上口的文学特性,也可以通过它了解两千年前历史的故事和先人的思想。

在上图的右侧的两幅图里面,可以看到是有建筑、有场景、有树木等。如果仅仅看到这两幅图,相信大家并不知道图片表达的意思。但是结合了文字之后,就可以一目了然的看到要讲的内容。所以说文字是计算机视觉的重要线索,与其他视觉信息有着重要的互补作用,可以和对话、NLP等,合成多模态语义分析。
光学字符识别,英文为OCR,是指把图片、PDF中的文字转换成可编辑的文字,也就是通常所说的文字识别。如果只提光学字符识别,估计很多人不知道是什么意思,所以大家通常把光学字符识别说成为文字识别。实际光学字符识别是一般包括检测和识别等多个过程。文字检测,是指判断是否存在文字实例,并给出具体位置的过程。而文字识别是指把文字区域转化成计算机可读和编辑的符号。
文字识别方法也是有很多的,有一种方法是基于手工设计的特征。这个在2014年前是主流的方法,比如MSER,SIFT等。在2014年之后,大家主要用的方法是深度学习方法。

左边这两张图分别是把发票和文档转化成文字
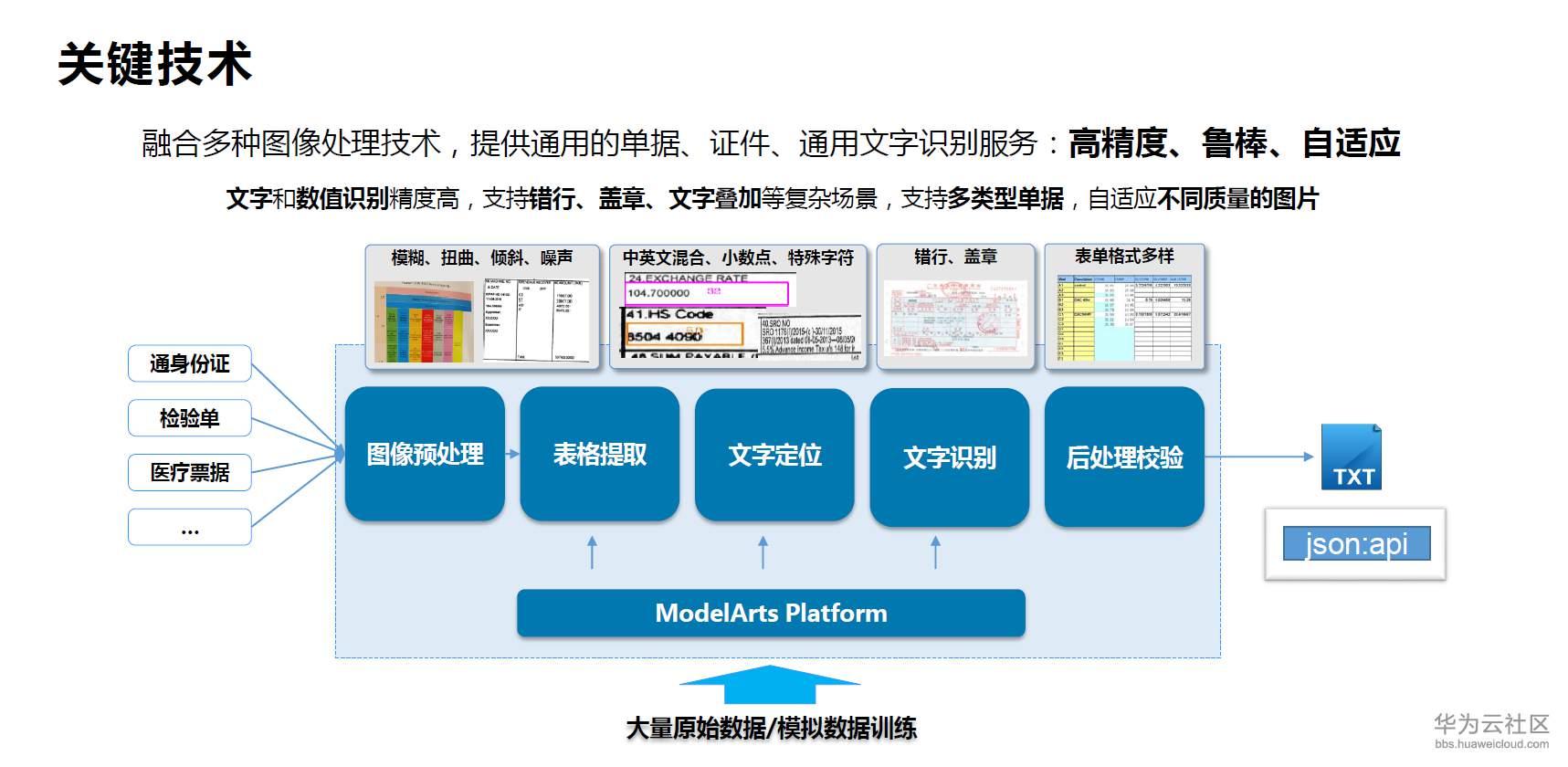
在文字识别技术领域,华为云也有着深入的研究。华为云的OCR处理流程,融合了多种图像处理技术,具有高精度,鲁棒性和自适应性等特点。处理结果中,文字识别精度特别高,支持错行、盖章、文字叠加等复杂场景。同时还支持多种类型单据、及自适应不同质量图片。整个流程包括图像预处理、表格提取(有没有表格进一步处理)、文字定位,整个流程中可能还会有文字矫正、文字识别、文字后处理等内容,最后返回给客户的是结构化的json数据。
文字和检测和识别的难点也是非常多。从下面图片可以看得出,它的背景非常的复杂,字体不一、颜色多种多样、字体多种朝向、大小各不相同、语言不统一、模板不固定等应用场景,这些都是日常生活中所看到的。

在日常生活的指示栏、窗户、砖块、图标、花草、栅栏、树木、机电等都与文字有一定的相似性,给检测和识别带来很大的干扰。
图像本身和成像也会存在的问题,比如分比率、曝光、反光、局部遮挡、干扰等,给检测和识别带来很大的挑战。

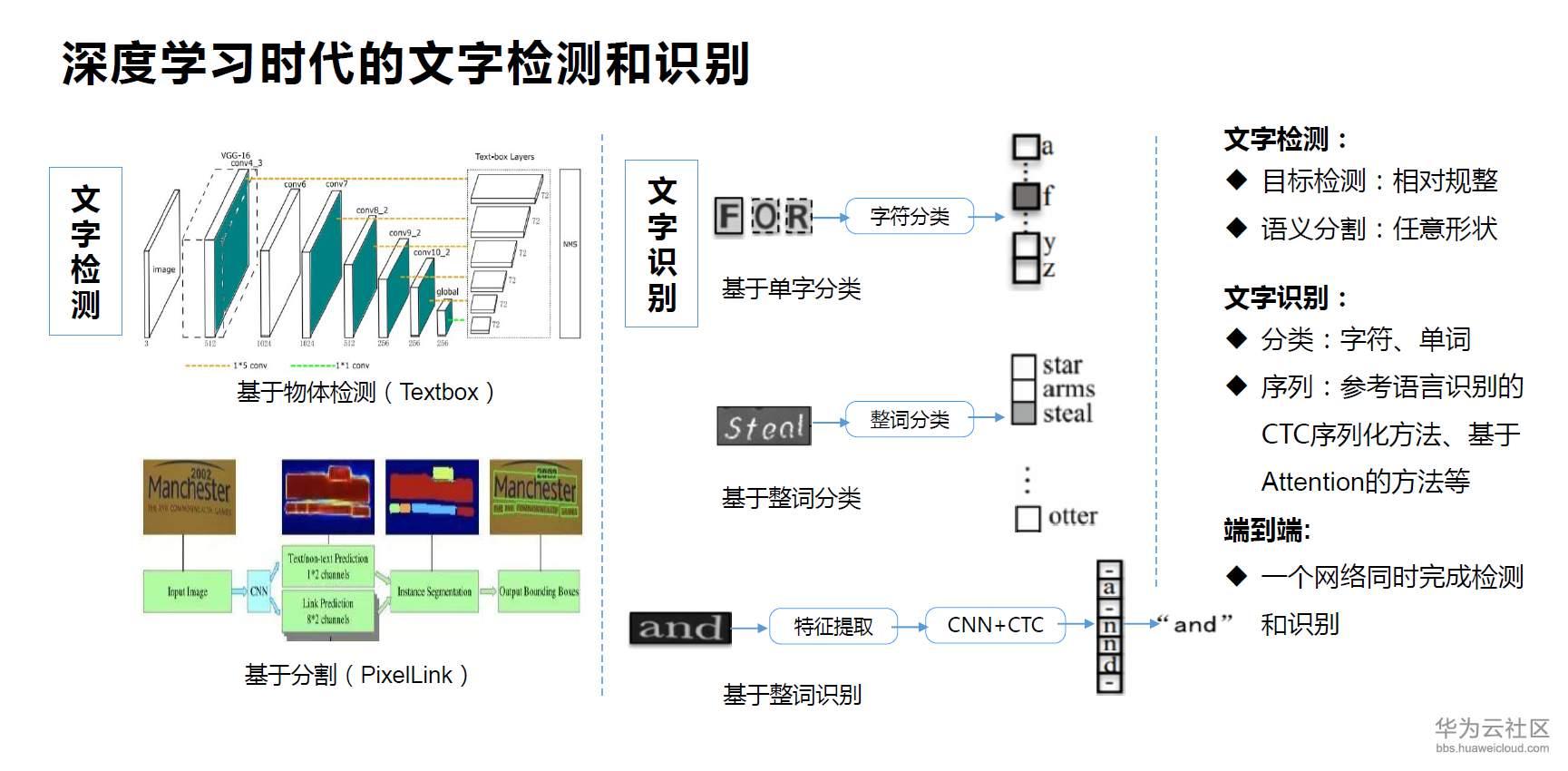
深度学习时代的文字和检测和识别,主要是基于深度学习。其中文字检测和目标检测类似,主要是基于物体检测和基于分割。比如说我们左上边看到的textbox是基于SSD目标检测网络,主要改了anchor的设置。在左下图的pixellink,则是基于分割。其中基于目标检测,更多是侧重比较规整的、可以用四点表示,而分割更多倾向于各种不规则形状的文字。
文字识别,最常用的思想是把文字分成一个个字符,然后直接分类,这是以前传统方法最常用的技术之一。中间一个也是基于分类,但是基于单词,对整句话非常难以处理好。最后,是基于序列的特征,提取基本特征,比如说CTC,是参考语音识别,比如说Attention,比如说基于sequence2sequence。最后就是端到端的识别,是在一个网络里同时做到文字检测和识别,检测和识别可以相辅相成,提高性能。
华中科技大学许老师提出一个TextField的概念,就是文字方向场的概念,传统基于分割的文字检测方法有一个很大的局限性就是对密集文本无法有效区分开。他们提出一个文字方向场,基于像素做回归,然后通过后处理组合成一个文字条,对于弯曲特别离谱的文字都可以检测出来。

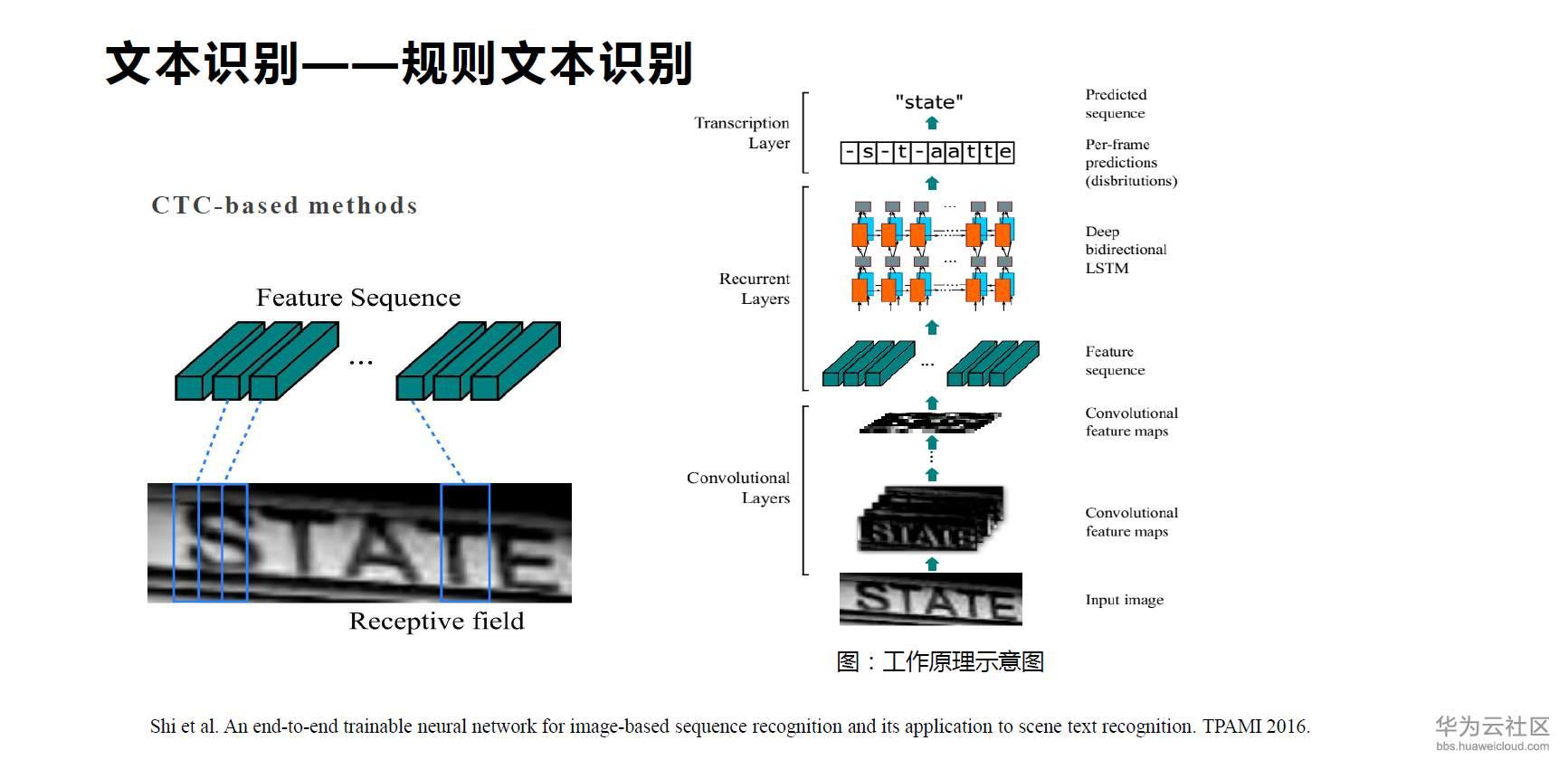
在文字识别当中非常有代表性的一个方法是就是华中科技大学白老师团队提出的CRNN模型(后正式发表在IEEE TPAMI2016上),称之为 CRNN,其底层用 CNN 提取特征,中层用 LSTM 进行序列建模,上层用 CTC loss 对目标进行优化。它是一个端到端可训练的文字识别结构,但并未使用 Attention。目前,CRNN 已成长为该领域的一个标准方法。