日志数据如何同步到MaxCompute
摘要:日常工作中,企业需要将通过ECS、容器、移动端、开源软件、网站服务、JS等接入的实时日志数据进行应用开发。包括对日志实时查询与分析、采集与消费、数据清洗与流计算、数据仓库对接等场景。本次分享主要介绍日志数据如何同步到MaxCompute。具体讲解如何通过Tunnel,DataHub,日志服务SLS以及Kafka将日志数据投递到MaxCompute的参数介绍和详细同步过程等内容。
演讲嘉宾简介:刘建伟,阿里云智能技术支持工程师
本次直播视频精彩回顾,戳这里!https://yq.aliyun.com/live/1575
以下内容根据演讲视频以及PPT整理而成。
本次分享主要围绕以下四个方面:
一、实验目的
二、方案介绍
三、方案比较及场景应用
四、操作步骤
一、实验目的及方案介绍
1.实验目的
日常工作中,企业需要将通过ECS、容器、移动端、开源软件、网站服务、JS等接入的实时日志数据进行应用开发。包括日志实时查询与分析、采集与消费、数据清洗与流计算、数据仓库对接等场景。

二、方案介绍
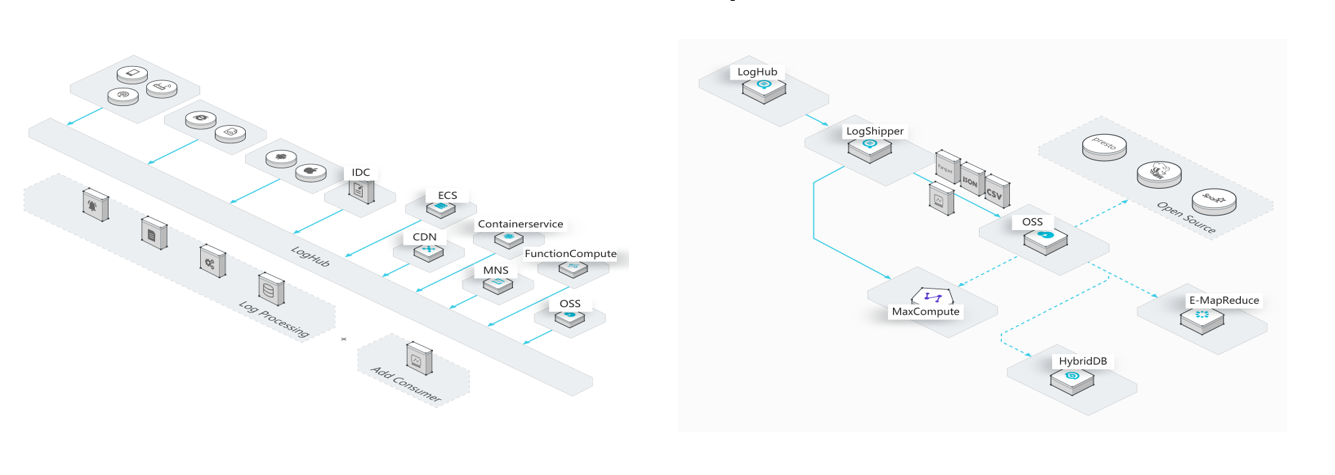
日志数据同步到MaxCompute的场景主要有四个方案。
方案一:使用Tunnel命令上传日志数据到MaxCompute。
方案二:通过DataHub投递数据到MaxCompute。DataHub DataConnector是把DataHub服务中的流式数据同步到其他云产品中的功能,目前支持将Topic中的数据实时/准实时同步到MaxCompute、OSS、ElasticSearch、RDS Mysql、ADS.、TableStore中。用户只需要向DataHub中写入一次数据,并在DataHub服务中配好同步功能,便可以在各个云产品中使用这份数据。
方案三:通过SLS实时采集与消费( LogHub )投递数据到MaxCompute。也可通过DataWorks的数据集成( Data Integration )功能投递至MaxCompute。
方案四:通过Kafka订阅实时数据投递至MaxCompute。
其中方案二(DataHub)和方案三( LogHub )差异化不强,均属于消息队列。一般来说DataHub用于进行公测或自研。
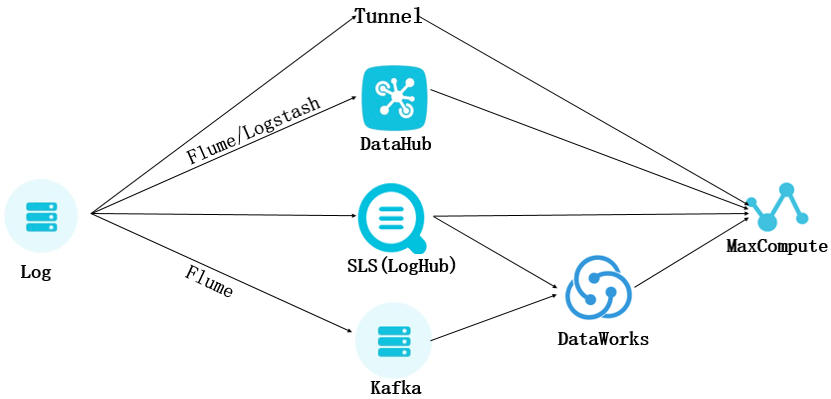
三、方案比较及场景应用
1. Tunnel
Tunnel主要用于批量上传数据到离线表中,适用于离线计算的场景。对于特殊格式日志,一般建议将日志作为一个整体字段上传到MaxCompute表中,再进行拆分。
2. DataHub
DataHub用于实时上传数据的场景,主要用于流式计算场景。数据上传后会保存到实时表里,后续会在几分钟内通过定时任务的形式同步到离线表里,供离线计算使用。
3.日志服务(SLS)
LogHub:可适用于数据清洗(ETL)、流计算( Stream Compute)、监控与报警、机器学习与迭代计算等场景。其实时性强,写入即可消费。
Logtail (采集Agent ):实时采集传输,1秒内到达服务端( 99.9%)。写入即可查询分析。此外可支持海量数据,对数据量不设上限。种类丰富,支持行、列、TextFile等各种存储格式。而且配置灵活,支持用户自定义Partition等配置。
LogShipper(投递数仓):可支持稳定可靠的日志投递。将日志中枢数据投递至存储类服务进行存储。支持压缩、自定义Parition,以及行列等各种存储方式。可以进行数据仓库、数据分析、审计c推荐系统与用户画像场景的开发。支持通过控制台数据接入向导一站式配置正则模式采集日志与设置索引。
4.Kafka
Kafka是一款分布式发布与订阅的消息中间件,有高性能、高吞量的特点,每秒能处理上百万消息。Kafka适用于流式数据处理。可应用场景分别是大数据领域和数据集成。大数据领域主要应用于用户行为跟踪、日志收集等场景。结合数仓将消息导入MaxCompute、 OSS、RDS、Hadoop.、HBase等离线数据仓库。
四、操作步骤
1. 方案一:通过Tunnel命令上传日志数据到MaxCompute
环境准备及步骤:
(1) 开通MaxCompute服务,安装odpscmd客户端。
(2) 准备日志服务数据。
(3) 创建MaxCompute表,用于储存日志数据。
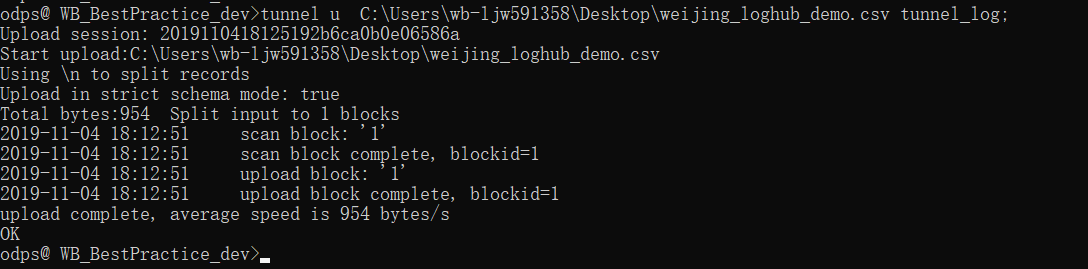
(4) 使用特征命令:tunnel u C:UsersDesktopweijing_loghub_demo.csv tunnel_log。
u即upload,随后是上传路径和用于存储日志数据的表名。如下图所示,执行后日志数据投递成功,说明已经通过Tunnel命令将日志数据上传到MaxCompute中。
(5) 查询表数据是否导入成功。
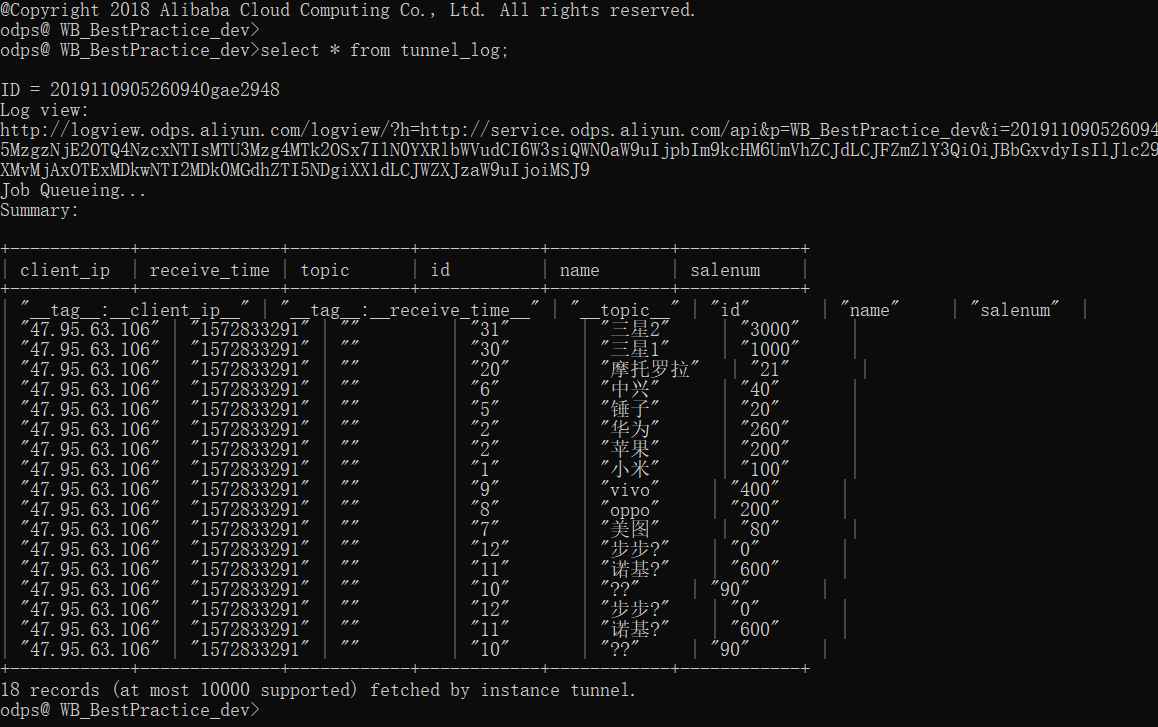
查询后显示表中已有数据导入,说明日志数据成功导入MaxCompute表中。
注意事项:
(1) 使用Tunnel命令行工具上传数据当前不支持通配符或正则表达式命令。若用户想借助正则表达式上传数据,可使用方案三(LogHub支持正则表达式)。
(2) 对于特殊格式的日志数据,一般建议作为一个整体字段上传,到MaxCompute里,再进行拆分。
2. 方案二:通过DataHub投递日志数据到MaxCompute
环境准备及步骤:
(1) 登录阿里云DataHub控制台,创建Project。
(2) 进入Project管理页面 Project列表->Project查看,创建Topic。创建Topic有两种方式,一是直接创建,或者是导入MaxCompute表结构。
(3) 选择导入MaxCompute表结构。输入MaxCompute项目,选择项目名称。输入MaxCompute表,此MaxCompute表可以是已经创建的表,也可新建表名,会自动创建一个MaxCompute表。然后填写AccessidAccessKey信息。勾选自动创建DataConnector,勾选后会在创建Topic时自动创建一个DataConnector。填写Topic名称。Shard数量默认为1k KPS,用户可根据自己的数据流量进行设置。再设置生命周期。
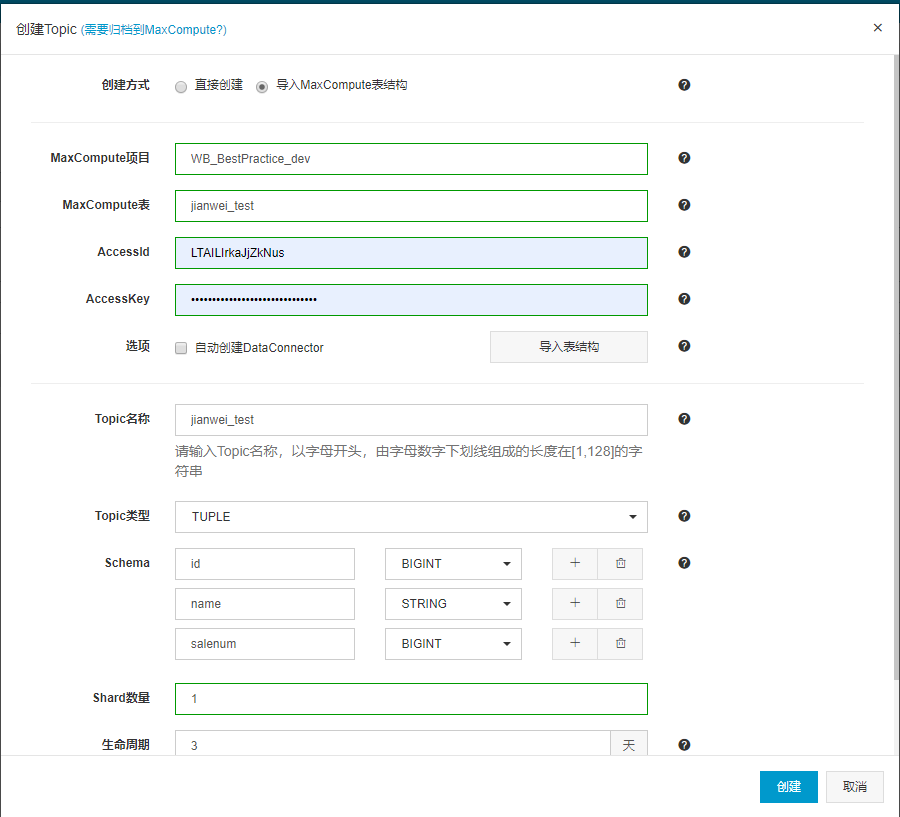
注意:Schema对应MaxCompute表,该表字段类型、名称、顺序必须与DataHub Topic字段完全一致,如果三个条件中的任意一个不满足,则归档Connector无法创建。
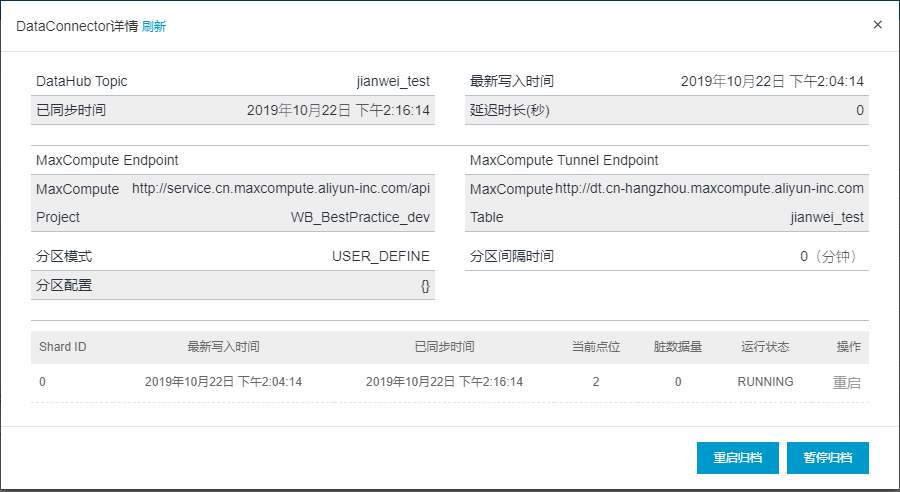
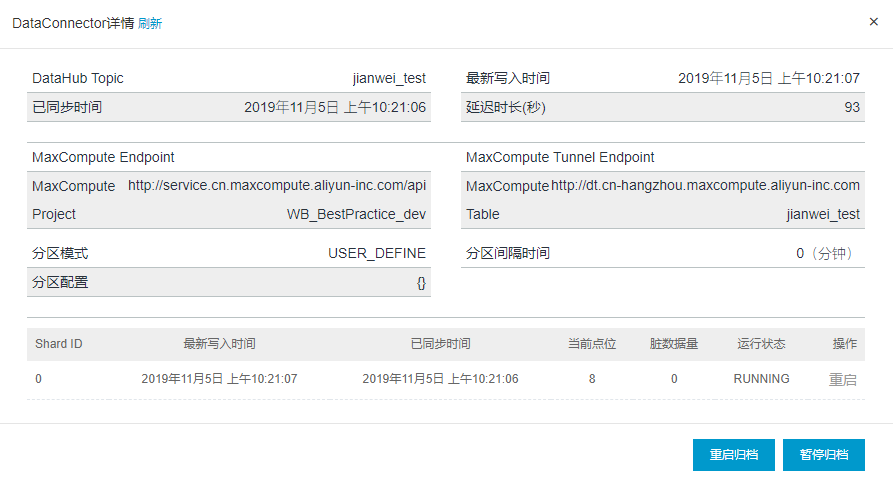
(4) 创建好的DataConnector详细信息如下图所示。包括已同步时间、最新写入数据时间、MaxCompute Endpoint、运行状态、脏数据量、当前点位。当前点位从0开始,下图示例中为2,说明已导入三条数据。
直接创建Topic: 首先输入一个MaxCompute项目,再输入MaxCompute表,可为已知表或新建表。再输入相应ACCESSIDACCESSKEY信息。
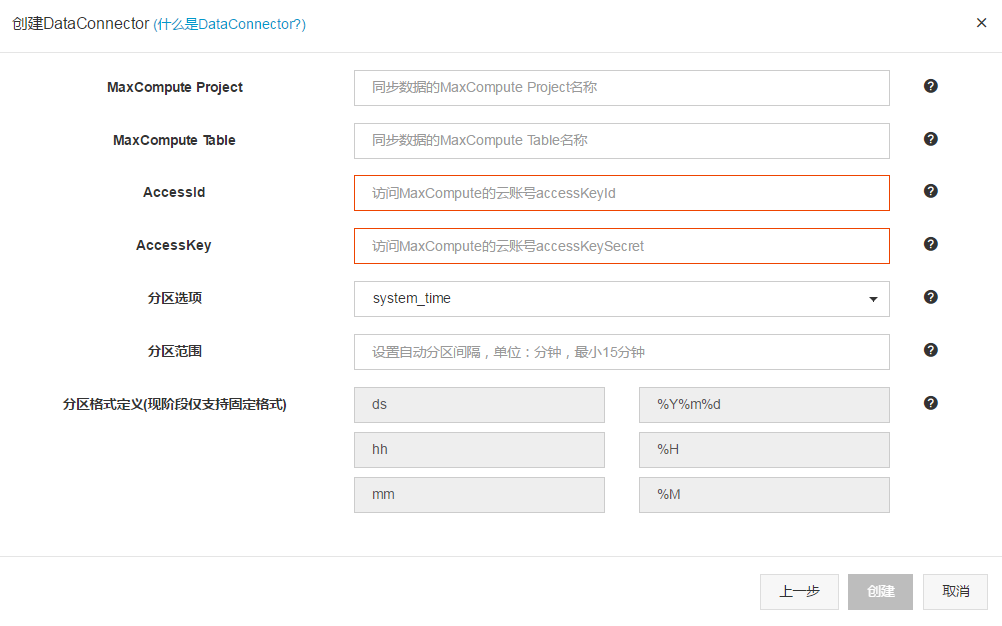
(5) 如果已经创建Topic,只需要在详情页的右上角点击 + DataConnector。
分区范围包含SYSTEM_TIME、EVENT_TIME、USER_DEFINE三种模式,SystemTime模式会使用写入时间转化为字符串进行分区。EventTime模式会根据topic中固定的event_time字段时间进行分区(需要在创建Topic时增加一个TIMESTAMP类型名称为event_time的字段,并且写入数据时向这个字段写入其微秒时间)。UserDefine模式将会直接使用用户自定义的分区字段字符串分区。分区格式目前仅支持固定格式。
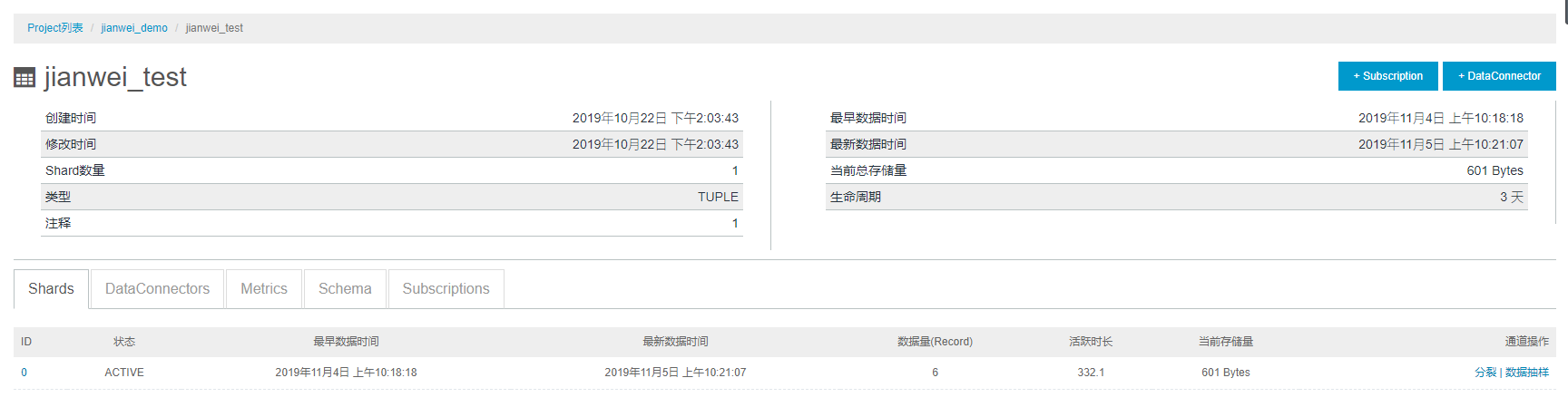
(6) 回到DataHub控制台,点击Topic。
如下图所示,可以看到Shard通道,会记录数据写入时间、最新数据时间、数据量以及当前存储量。
点击DataConnector,可查看其详细信息。包括配置的目标服务、目标描述以及最新写入数据的时间。
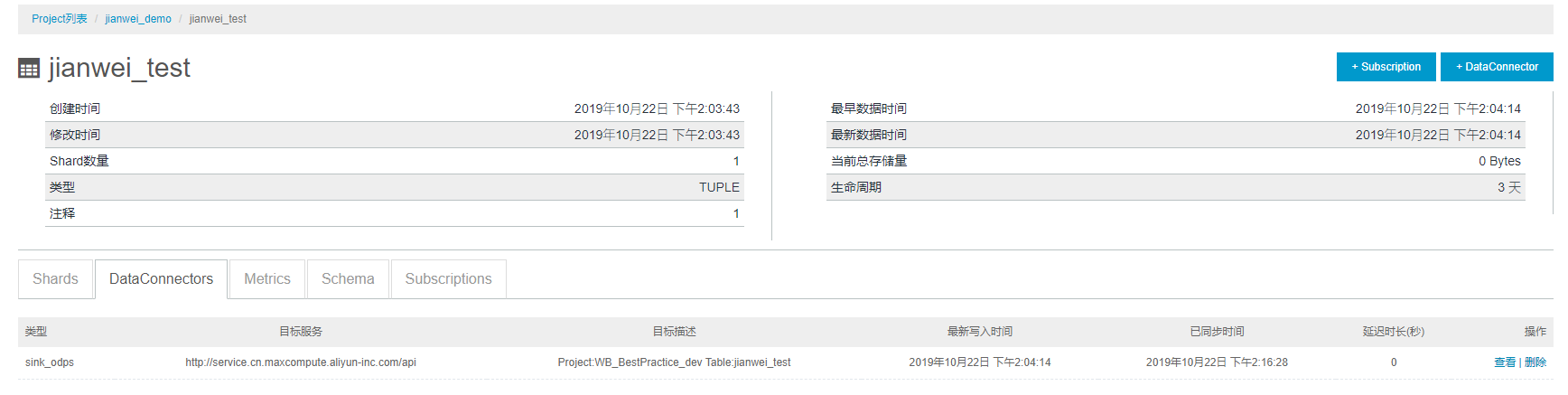
(7) 日志数据抽样。如下图所示点击数据抽样可以查看写入DataHub中的日志数据。
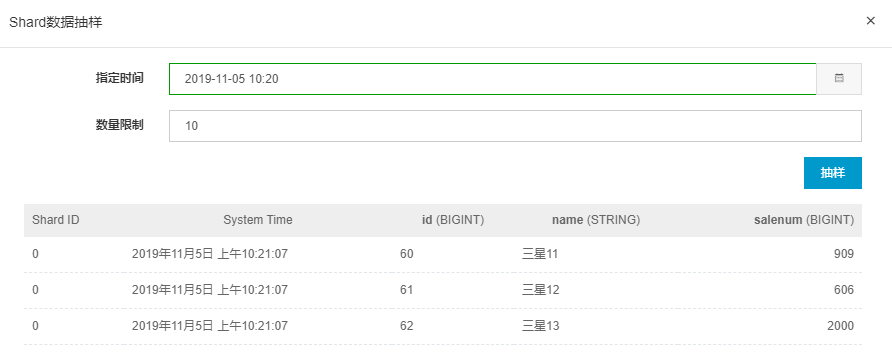
点击查看DataConnector详细信息,可看到归档信息包括当前点位、脏数据、运行状态。如果运行状态为失败,需要检查原因,一般可能为Endpoint配置问题。DataHub投入数据到MaxCompute离线表中默认每60M commit一次,或五分钟进行一次强行写入,可以保证至少五分钟一次数据同步。
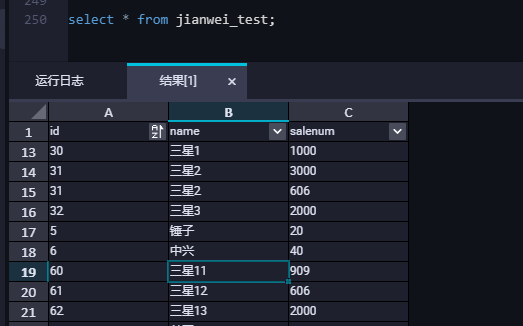
(8) 测试日志数据是否投递成功。如下图所示,进行扫描发现有数据写入,说明通过DataHub投递数据至MaxCompute成功。
注意事项:
(1) 目前所有DataConnector均仅支持同一Region的云服务之间同步数据,不支持同步数据到跨Region的服务。
(2) DataConnector所配置的目标服务Endpoint需要填写相应的内网域名(经典网络),不支持使用公网域名同步。
(3) 数据同步目前仅支持at least once语义,在网络服务异常等小概率场景下可能会导致目的端的数据产生重复但不会丢失,需要做去重处理。
(4) topic默认可创建20个,如果需要创建更多,需提交工单申请。
3. 方案三:通过LogHub投递日志数据到MaxCompute
直接通过LogHub投递:
环境准备及步骤:
(1) 开通日志服务,登录日志服务控制台,创建新的Project或者单击已创建的Project名称。
(2) 创建新的Logstore或者单击已经创建好的Logstore名称。
(3) 单击对应的Logstore,查询分析导入到LogHub的日志数据。如下图演示所示几条数据即为LogHub的日志数据,需要将其同步到MaxCompute表中。
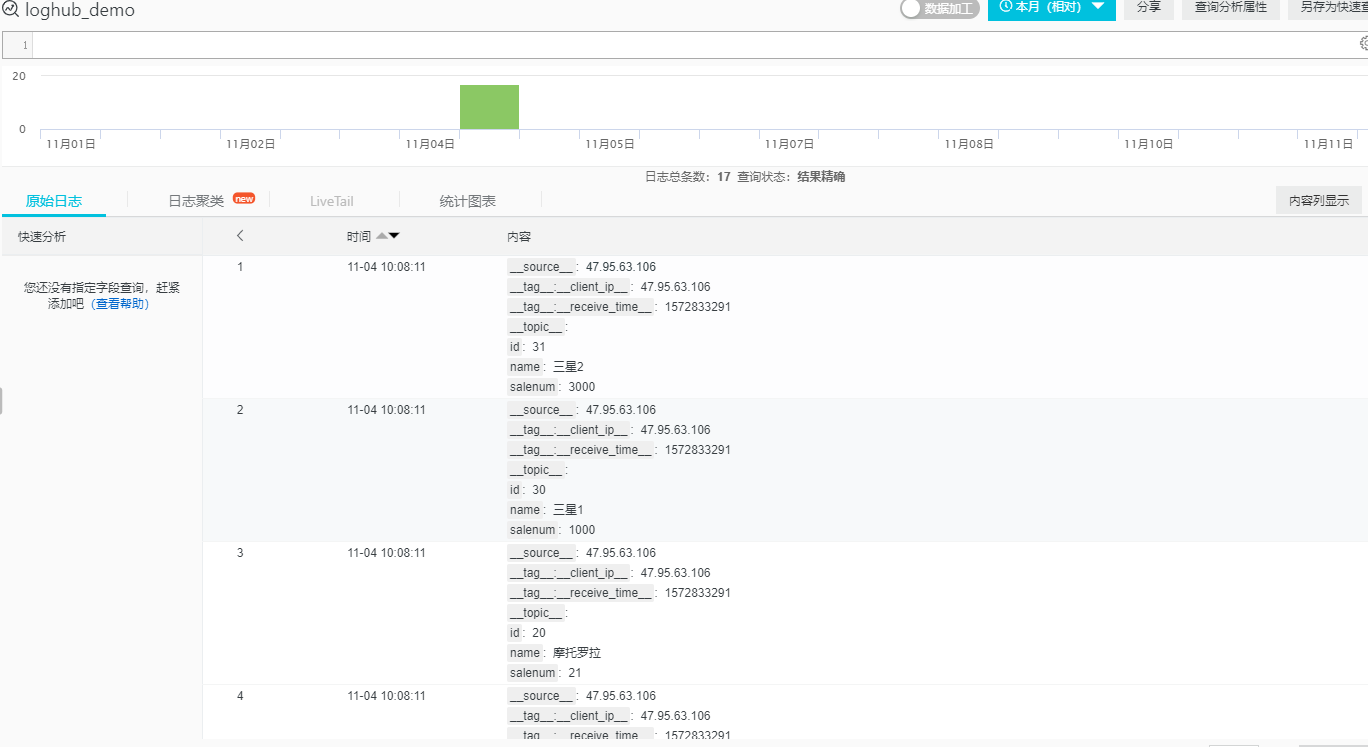
(4) 选择需要投递的日志库名称并依次展开节点,日志库名称->数据处理->导出->MaxCompute。单击开始投递。
(5) 单击开启投递以进入LogHub->数据投递页面。进行相关配置。
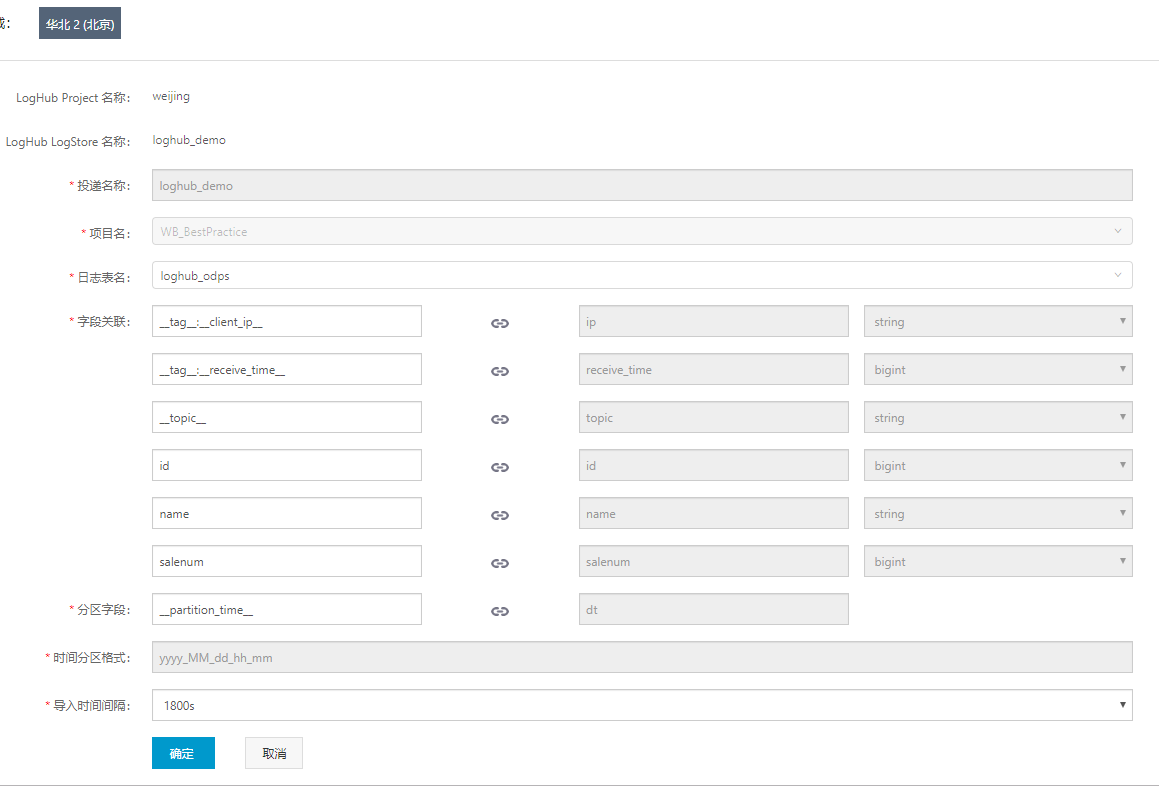
(6) 配置投递规则,在LogHub->数据投递页面配置字段关联等相关内容。如下图所示。
a) 自定义一个投递名称
b) MaxCompute表名称,项目名以及日志表明。输入自定义的新建的MaxCompute表名称或者选择已有的MaxCompute表。
c) 字段关联。左边是LogHub表的字段列,右边是MaxCompute表中的字段列。按序,左边填写与MaxCompute表数据列相映射的日志服务字段名称,右边填写或选择MaxCompute表的普通字段名称及字段类型。
d) 分区字段:__partition_time__
格式:将日志时间作为分区字段,通过日期来筛选数据是MaxCompute常见的过滤数据方法。__partition_time__是根据日志__time__值计算得到(不是日志写入服务端时间,也不是日志投递时间),结合分区时间格式,向下取整。
(7) 在投递管理页面,单击修改即可对之前的配置信息进行编辑。如果想新增列,可以在大数据计算服务MaxCompute修改投递的数据表列信息,单击修改后会加载最新的数据表信息。
(8) 投递任务管理。如下图所示,配置成功后点击确定,会提示成功配置了一个数据投递到MaxCompute。
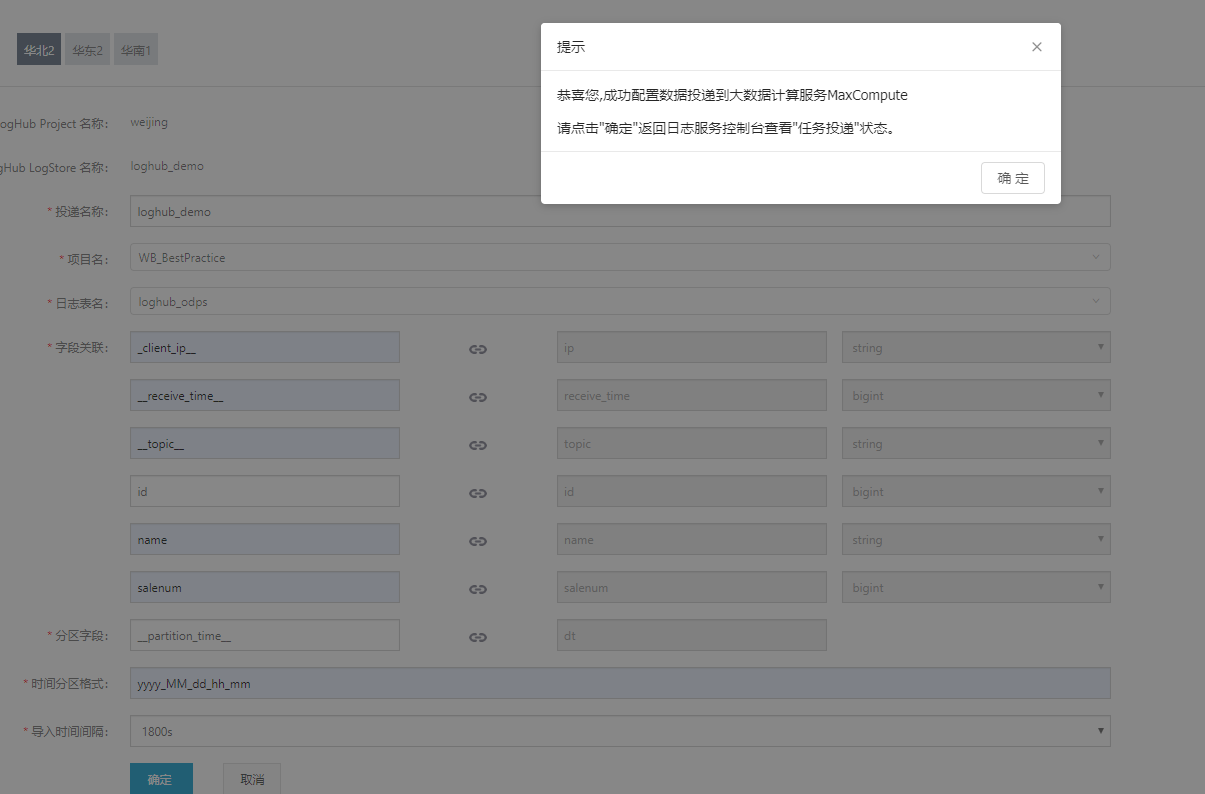
启动投递功能后,日志服务后台会定期启动离线投递任务。用户可以在控制台上看到这些投递任务的状态和错误信息。当投递任务发生错误时,需要查看错误信息,问题解决后可以通过云控制台中日志投递任务管理或SDK来重试失败任务。
(9) 查看日志投递的运行状态。如下图所示日志开始投递后状态是运行中,运行行数为0,日志投递成功后运行行数为11,状态转变为成功。说明通过LogHub投递日志到MaxCompute成功。
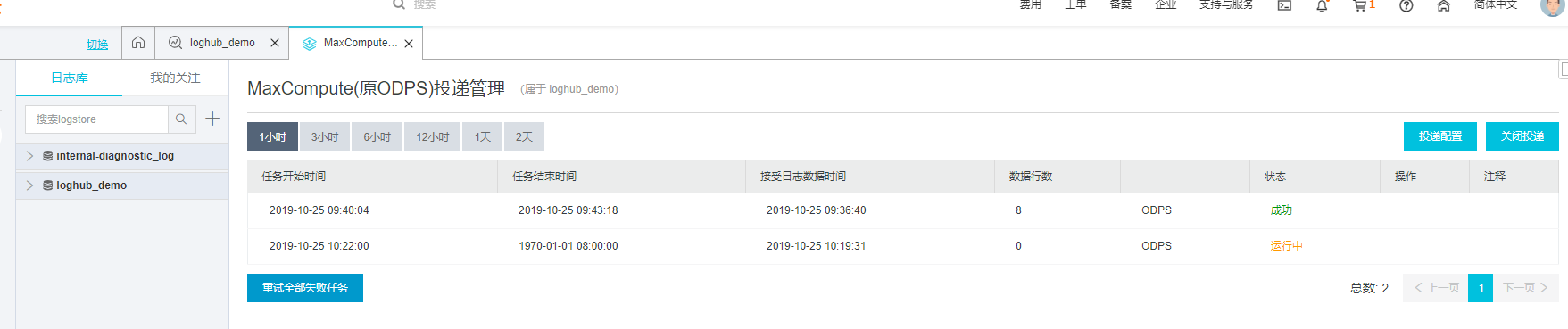
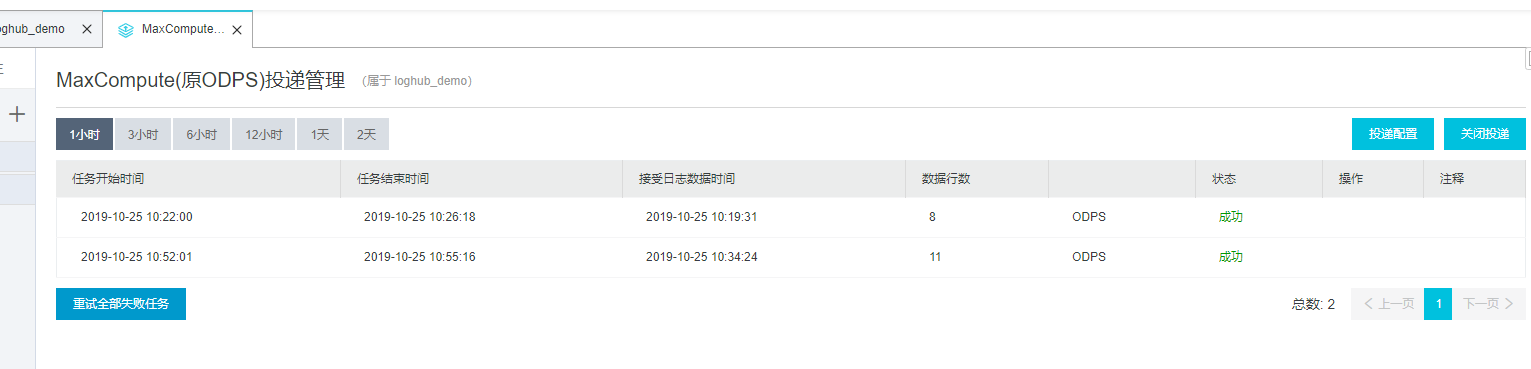
(10) 日志投递MaxCompute后,检查数据完整性。
a) 通过控制台或API/SDK判断(推荐)。使用API、SDK或者控制台获取指定Project/Logstore投递任务列表。控制台会对该返回结果进行可视化展示。
b) 通过MaxCompute分区粗略估计,比如在MaxCompute中以半小时做一次分区,投递任务为每30分钟一次,当表中包含以下分区:
2019_10_25_10_00
2019_10_25_10_30
当发现分区2019_10_25_11_00出现时,说明11:00之前分区数据已经完整。该方法不依赖API,判断方式简单但结果并不精确,仅用作粗略估计。
(11) 查询MaxCompute表中数据。
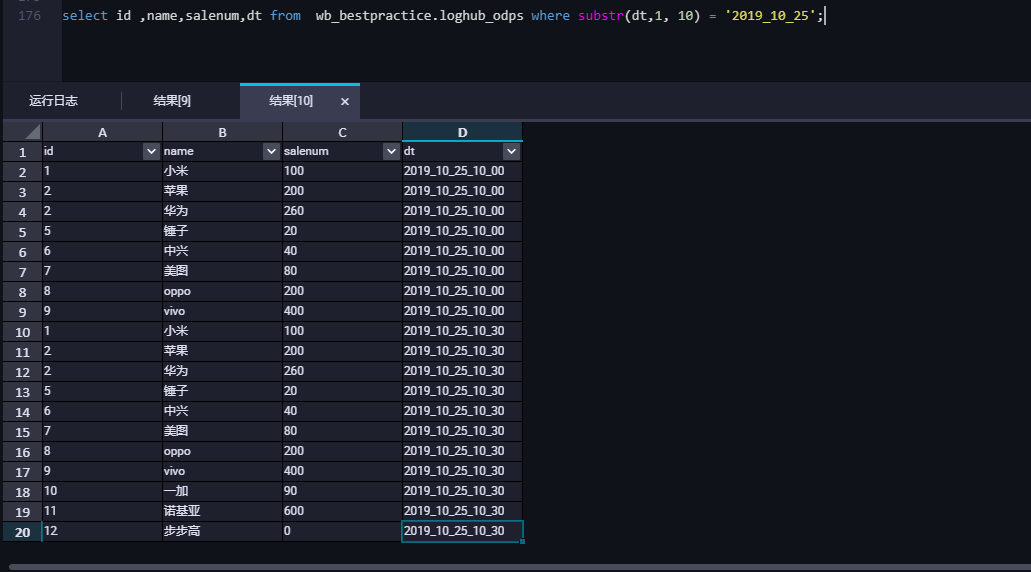
注意事项:
(1) 数加控制台创建、修改投递配置必须由主账号完成,不支持子账号操作。
(2) 不同Logstore的数据不可导入到同一个MaxCompute表中,否则会造成分区冲突、丢失数据等后果。
(3) MaxCompute表至少包含一个数据列、一个分区列。
(4) MaxCompute单表有分区数目6万的限制,分区数超出后无法再写入数据,所以日志服务导入MaxCompute表至多支持3个分区列。需谨慎选择自定义字段作为分区列,保证其值可枚举。
(5) 日志服务数据的一个字段最多允许映射到一个MaxCompute表的列(数据列或分区列),不支持字段冗余,同一个字段名第二次使用时其投递的值为null,如果null出现在分区列会导致数据无法被投递。
(6) 投递MaxCompute是批量任务,需谨慎设置分区列及其类型:保证一个同步任务内处理的数据分区数小于512个;用作分区列的字段值不能为空或包括‘/’等MaxCompute保留字段。
(7) 不支持海外Region的MaxCompute投递,海外Region的MaxCompute可使用DataWorks进行数据同步。
DataWorks:
环境准备及步骤:
(1) 登录阿里云LogHub控制台,创建Project。
(2) 登录DataWorks控制台,单击对应项目进入数据集成。
(3) 配置LogHub数据源。进入同步资源管理->数据源页面,单击右上角的新增数据源。
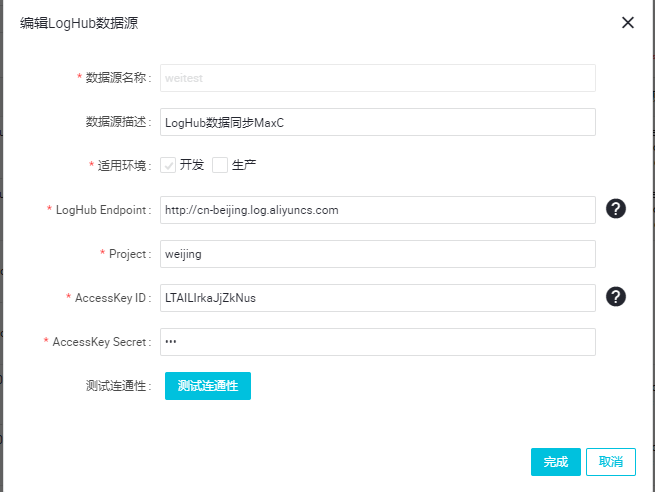
(4) 选择数据源类型为LogHub,填写新增LogHub数据源对话框中的配置,如下图所示。选择环境,填写数据源名称、LogHub Endpoint、在LogHub中创建的Project以及ACCESSIDACCESSKEY信息。填写完成后单击测试连通性。测试连通性通过说明数据源可以正确使用。单击确定。
(5) 配置同步任务。可选择向导模式,通过简单便捷的可视化页面完成任务配置;或者选择脚本模式,深度自定义配置同步任务。
新建业务流程->数据集成->新建数据集成节点->数据同步进入数据同步任务配置页面。
使用向导模式需要填写日志开始时间和结束时间。日志开始时间表示数据消费的开始时间位点,为yyyyMMddHHmmss格式的时间字符串(比如20191025103000),左闭右开。日志结束时间表示数据消费的结束时间位点,格式与日志开始时间相同。
批量条数:一次读取的数据条数,默认为256。
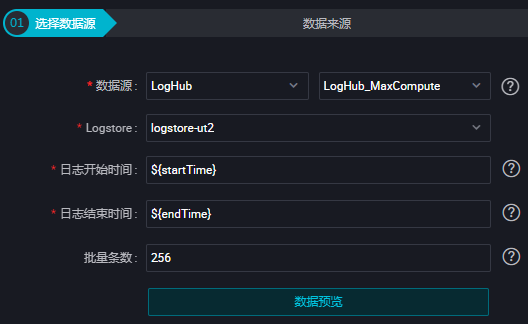
a) 向导模式配置同步任务。
配置数据源及数据去向。数据源为LogHub,填写Logstore,配置日志开始时间和日志结束时间。数据去向可选择MaxCompute的一个数据源,选择需要导入的表,填写数据信息,进行字段映射。保存数据同步的配置。提交并运行。查询MaxCompute表中数据,确保日志服务数据已经成功同步到MaxCompute。
b) 脚本模式配置同步任务。
导入模板,选择数据源和目标数据源。编辑脚本。需要填写reader和writer的脚本配置。
如下图红色框框选内容所示,reader端需要填写beginDataTime(日志开始时间)、datasourse(数据源,填写已配置好的数据源名称)、encoding(编码格式)、endDataTime(日志结束时间)、logstore(日志库)等。下图绿色框框选内容所示为writer端即(MaxCompute端)相应配置信息。需要填写列名,需要和LogHub配置的列名对应。填写datasourse、partition、table、truncate。
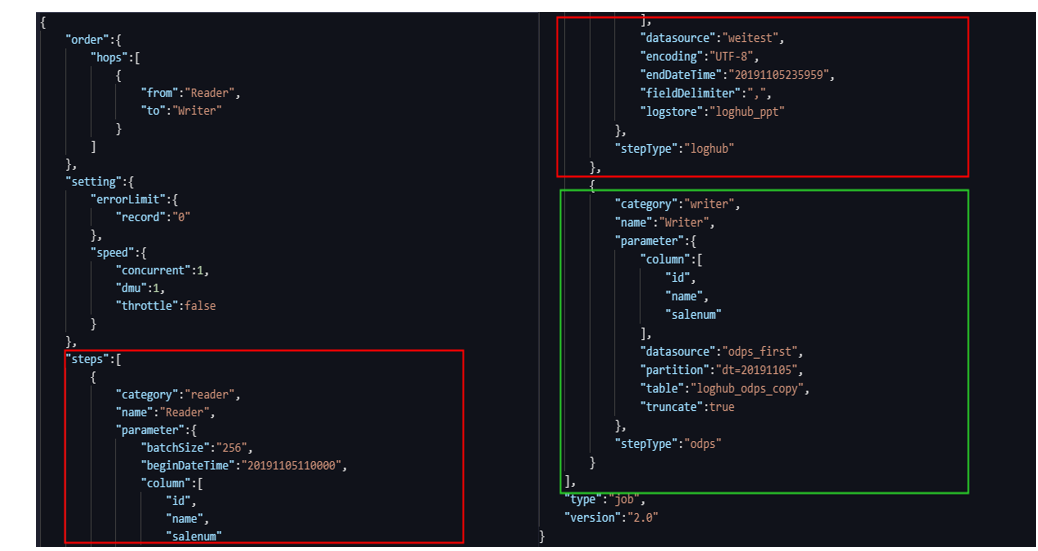
保存脚本数据节点,脚本模式配置成功后单击提交并运行。运行后数据即会从LogHub投递到MaxCompute表中。
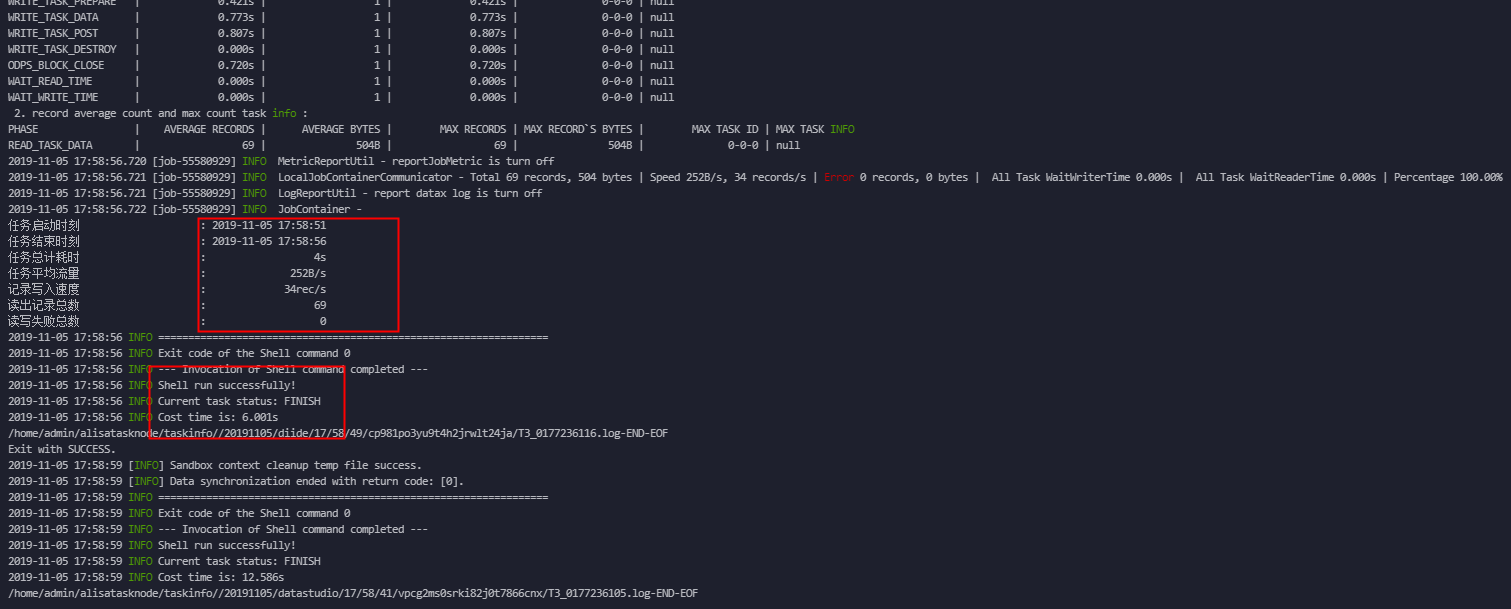
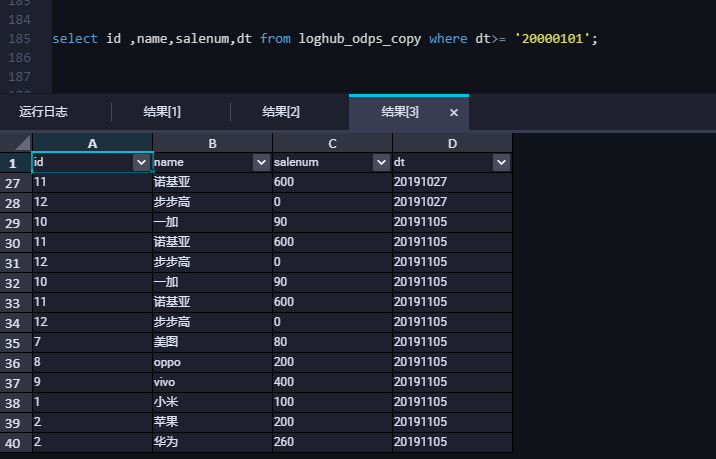
如上图演示截图所示,投递成功。查询MaxCompute表中数据,确保日志服务数据已经成功同步到MaxCompute。如下图所示。
4. 方案四:通过Kafka投递日志数据到MaxCompute
环境准备及步骤:
(1) 搭建Kafka集群。
(2) 在控制台创建Topic和Consumer Group。
(3) Flume读取日志文件数据写入到Kafka。首先为flume构建agent:进入flume下的配文件夹中编写构建agent的配置文件。再通过此命令启动flume的agent:bin/flume-ng agent -c conf -f 配置文件夹名/配置文件名-n a1 -Dflume.root.logger=INFO,console。然后启动Kafka的消费者进行数据写入bin/Kafka-console-consumer.sh:–zookeeper 主机名:2181 –topic Kafka_odps 。这样就开启了日志采集,文件会写入到Kafka中。
(4) 数据写入到Kafka,通过数据集成DataWorks同步数据到MaxCompute。
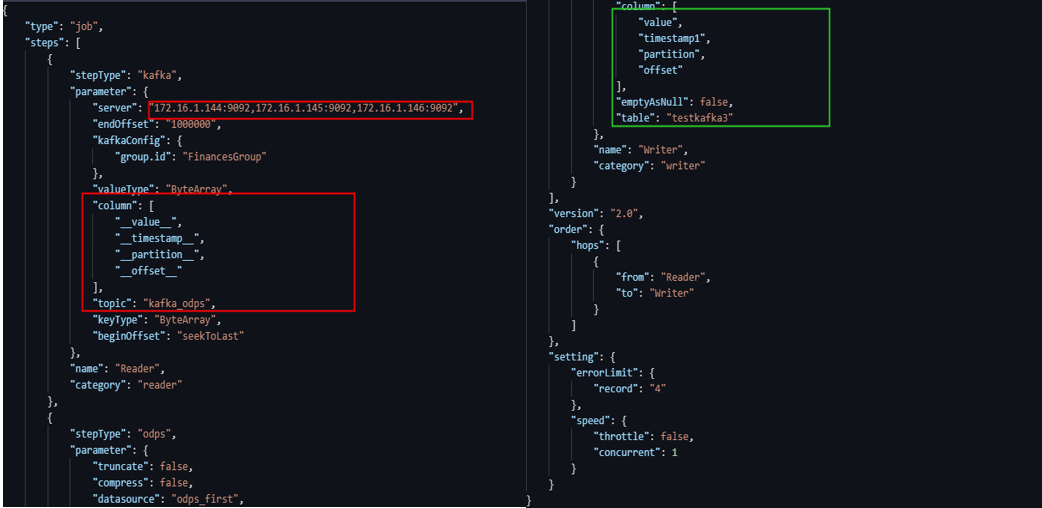
新建业务流程->新建数据同步节点->转换为脚本->配置脚本。
(5) 配置脚本信息,运行脚本进行数据节点的同步。如下图红色框框选内容为reader端配置,绿色框框选内容为writer端配置。注意reader端需要配置server,为Kafka broke Server,格式为:ip 端口号。框选的列为Kafka的属性列、数据列。下图演示中所填写内容为属性列,再填写相应Topic。需要填写begin offset,即数据消费开始节点。MaxCompute writer端,一一对应Kafka左边的列,需要填写table表名、datasourse等。脚本配置完成后点击提交并运行。运行成功后日志数据就会投递到MaxCompute表中。
(6) 查询MaxCompute表中数据,确保日志服务数据成功同步到MaxCompute。如下图演示所示。
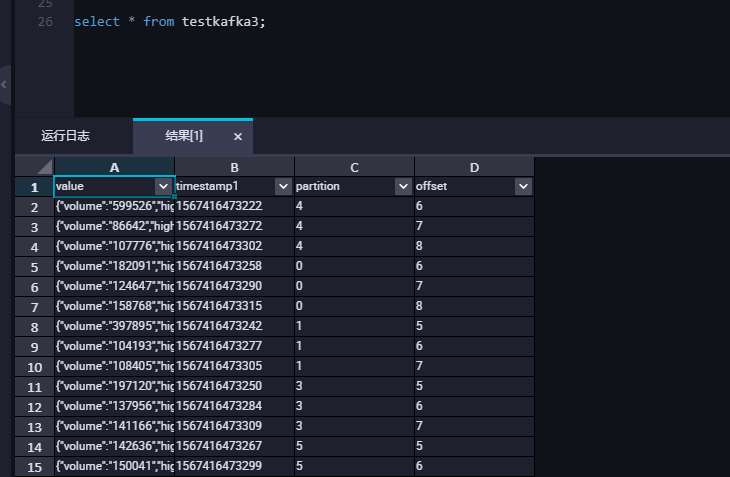
注意事项:
(1) 数据同步的脚本编写,Reader、Writer的配置。如果脚本配置有误,数据投递将会失败,运行失败。可以结合官方文档进行配置。
(2) Flume采集日志数据中配置文件的配置。配置文件中的Topic必须与Kafka创建的Topic保持一致。
本文作者:刘-建伟
本文为云栖社区原创内容,未经允许不得转载。